

产品中心

战靴走过泥泞道路,走向光明。
╔═══════════════════════════════════════════════╗
║ ║
║ ? 职场丛林生存手册 ? ║
║ ║
║ ⚠️ SpringBoot默认配置 = 温水煮青蛙 ⚠️ ║
║ ║
║ 8个致命陷阱 | 90%开发者中招 ║
║ ║
║ ? 不是技术不行,是根本没想清楚业务 ? ║
║ ║
╚═══════════════════════════════════════════════╝SpringBoot的"开箱即用"就像丛林里的甜美果实——好看好吃,但可能有毒!
90%的ToB系统和SaaS平台因为默认配置在生产环境翻车,不是Spring的错,是你根本没把它当生产级武器来配置!
那是老李永远不会忘记的一夜。
凌晨3点,当订单洪峰涌入时,系统响应时间从平时的200ms飙升到30秒以上。用户疯狂刷新页面,却只能看到无尽的加载圈。
排查发现:Tomcat线程池满载,200个线程全部卡死,排队请求超过1200条。
这就像丛林中的食物链崩塌——顶级捕食者(核心线程)全部被困住,整个生态系统瞬间瘫痪。
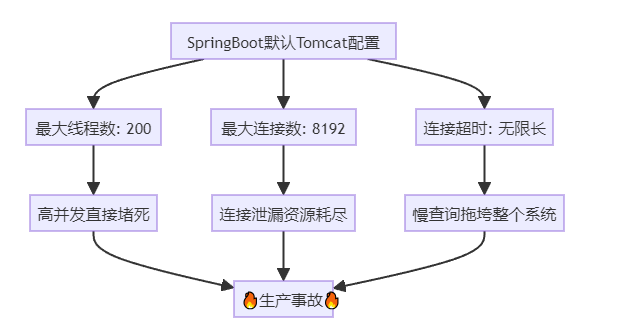
ToB系统的痛点分析:
业务特征:ToB系统往往服务多租户,单个租户的突发流量就能压垮整个系统
SaaS困境:共享资源池中,一个大客户的请求暴增,会影响所有小客户
REST API的特殊性:RESTful接口无状态,每个请求都需要独立线程处理
老李总结的线程池配置方法论:
| 配置项 | 计算公式 | ToB场景建议值 | 依据 |
|---|---|---|---|
| max线程数 | CPU核心数 × 2 × (1 + 平均等待时间/平均计算时间) | 4核设800,8核设1500 | IO密集型业务 |
| min-spare | max的10-20% | 100-200 | 减少冷启动延迟 |
| max-connections | max线程数 × 10-20 | 10000-15000 | 支持更多并发连接 |
| accept-count | max线程数的50-100% | 500-800 | 避免无限排队 |
| connection-timeout | 业务响应P99 × 2 | 20000ms | 快速失败保护 |
生产级配置(老李血泪版):
server:
tomcat:
threads:
max: 800 # 4核CPU,IO密集型
min-spare: 100 # 保持热线程池
max-connections: 10000 # 支持高并发
accept-count: 500 # 队列长度控制
connection-timeout: 20000 # 20秒超时保护
port: 8080
老李的一个客户是做跨境电商SaaS的,峰值QPS达到5000+。通过压测发现:
默认配置:200线程,P99响应时间35秒,成功率62%
优化后:800线程,P99响应时间1.2秒,成功率99.8%
关键决策点:不是线程越多越好,而是要根据业务特征(CPU密集/IO密集)精确计算。
2019年初,老李负责的订单系统突然出现"假死"现象——服务进程存活,但所有请求超时。
排查发现:HikariCP连接池的10个连接全部被占用,新请求无法获取连接而阻塞。
这就像丛林中的水源枯竭——所有动物都在等待,但水源永远不会增加。
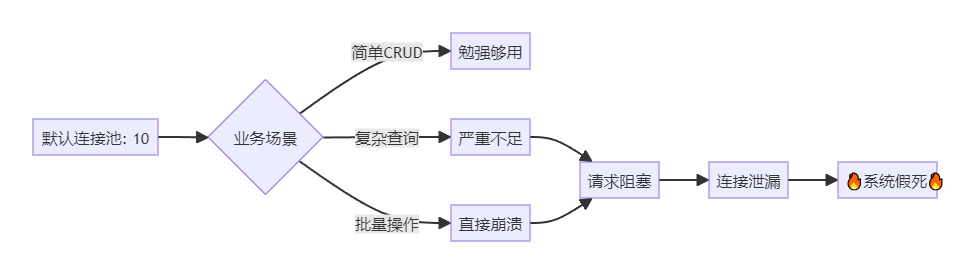
SaaS系统的特殊挑战:
多租户隔离:每个租户可能触发大量子查询
报表需求:BI分析类请求会长时间占用连接
定时任务:批量数据处理与在线请求竞争资源
老李的连接池配置方法论(基于Hikari官方推荐):
核心公式:
最大连接数 = ((CPU核心数 × 2) + 有效磁盘数) × 并发系数
并发系数 = 峰值并发线程数 / Tomcat最大线程数
实战配置表格:
| 场景 | CPU核心 | 并发线程 | 推荐连接数 | 理由 |
|---|---|---|---|---|
| 小型SaaS | 4核 | 200 | 30-50 | 主要CRUD操作 |
| 中型ToB | 8核 | 500 | 50-80 | 复杂查询+报表 |
| 大型平台 | 16核 | 1000 | 100-150 | 高并发+批处理 |
生产级配置(老李实战版):
spring:
datasource:
hikari:
maximum-pool-size: 50 # 根据压测确定
minimum-idle: 10 # 保持热连接
connection-timeout: 30000 # 30秒快速失败
idle-timeout: 600000 # 10分钟回收空闲
max-lifetime: 1800000 # 30分钟连接刷新
leak-detection-threshold: 60000 # 60秒泄漏检测
connection-test-query: SELECT 1 # MySQL心跳检测
老李的一个客户系统,运行3天后必定崩溃。排查发现是未关闭ResultSet导致的连接泄漏。
错误代码(反面教材):
// ❌ 连接泄漏
public List<Order> getOrders() {
Connection conn = dataSource.getConnection();
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery("SELECT * FROM orders");
// 忘记关闭,连接永远不归还!
}
正确姿势(加上泄漏检测):
// ✅ 使用try-with-resources自动关闭
public List<Order> getOrders() {
try (Connection conn = dataSource.getConnection();
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery("SELECT * FROM orders")) {
// 业务逻辑
}
}
配置leak-detection-threshold: 60000后,系统会自动报警未归还的连接,帮助老李快速定位了10多处泄漏点。
2020年某个周末,老李正在陪家人逛街,突然收到告警:生产服务器磁盘占用100%,系统停止响应。
登录服务器一看,/var/log目录下单个日志文件达到800GB,整个磁盘被撑爆。
这是老李见过的最恐怖的"日志地狱"。
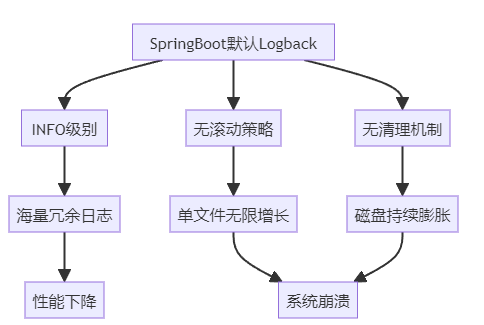
ToB系统的日志困境:
多租户场景:每个租户的操作都记录日志,日志量呈指数增长
审计需求:合规要求保留完整操作日志,但没有归档策略
排查需求:开发期望详细日志,但生产环境会产生TB级数据
老李总结的日志配置方法论:
| 防护层级 | 配置策略 | 目标效果 |
|---|---|---|
| 第一层:级别控制 | 生产WARN,业务包INFO | 减少80%冗余日志 |
| 第二层:滚动策略 | 100MB分割,按天归档 | 防止单文件过大 |
| 第三层:清理机制 | 保留30天,总量3GB | 自动清理历史日志 |
生产级配置(老李完整版):
logging:
file:
name: /var/log/your-app/app.log
level:
root: WARN # 全局WARN级别
com.yourcompany: INFO # 业务包INFO
org.springframework.web: ERROR # Spring框架ERROR
com.zaxxer.hikari: WARN # 连接池WARN
pattern:
console: "%d{yyyy-MM-dd HH:mm:ss} [%thread] %-5level %logger{36} - %msg%n"
file: "%d{yyyy-MM-dd HH:mm:ss} [%thread] %-5level %logger{36} - %msg%n"
# Logback滚动配置(需在logback-spring.xml中详细配置)
logback-spring.xml核心配置:
<configuration>
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>/var/log/your-app/app.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<fileNamePattern>/var/log/your-app/app-%d{yyyy-MM-dd}.%i.log</fileNamePattern>
<maxFileSize>100MB</maxFileSize>
<maxHistory>30</maxHistory>
<totalSizeCap>3GB</totalSizeCap>
</rollingPolicy>
</appender>
</configuration>
老李服务的一个金融SaaS客户,因合规要求必须保留所有操作日志。最终方案:
热日志:最近7天,存储在SSD,快速查询
温日志:8-30天,存储在HDD,归档压缩
冷日志:30天以上,上传到OSS对象存储,成本降低90%
关键技术:使用ELK Stack(Elasticsearch + Logstash + Kibana)实现日志分级存储。
老李的一个客户是做企业合同管理的SaaS平台。某天,多个企业客户投诉:无法上传PDF合同,系统一直报错。
排查发现:SpringBoot默认文件上传限制是1MB,而企业合同PDF平均5-10MB。
更坑的是,错误发生在文件传输完成之后——用户等了半天上传完,最后告诉你文件太大!

ToB系统的文件上传挑战:
文件类型多样:图片、PDF、Excel、视频,大小差异巨大
业务场景复杂:合同审批、财务凭证、产品资料,不能失败
多层限制:Nginx → SpringBoot → 磁盘,任何一层都可能卡死
老李的文件上传配置方法论:
| 配置层级 | 配置项 | 推荐值 | 说明 |
|---|---|---|---|
| Nginx | client_max_body_size | 100M | 前置网关限制 |
| SpringBoot | max-file-size | 100MB | 单文件大小 |
| SpringBoot | max-request-size | 100MB | 请求总大小 |
| SpringBoot | file-size-threshold | 2KB | 内存阈值 |
生产级配置(完整版):
spring:
servlet:
multipart:
enabled: true
max-file-size: 100MB # 单文件100MB
max-request-size: 100MB # 请求总大小
file-size-threshold: 2KB # 超过2KB写磁盘
location: /tmp/upload # 临时文件路径
resolve-lazily: true # 延迟解析,提前检测
Nginx配置(nginx.conf):
server {
client_max_body_size 100M;
client_body_timeout 300s;
location /api/upload {
proxy_pass http://backend;
proxy_request_buffering off; # 禁用缓冲,流式传输
}
}
老李为一个视频SaaS平台设计的分片上传方案:

核心技术:
前端:使用SparkMD5计算文件哈希,支持断点续传
后端:Redis存储分片信息,所有分片到齐后合并
结果:1GB视频文件上传成功率从65%提升到99.5%
老李的一个跨境电商客户发现:同一个订单,在不同页面显示的创建时间相差8小时。
排查发现:
数据库服务器时区:UTC
应用服务器A时区:GMT+8
应用服务器B时区:UTC
前端展示:时间戳,没有时区转换
结果:整个系统的时间一片混乱。
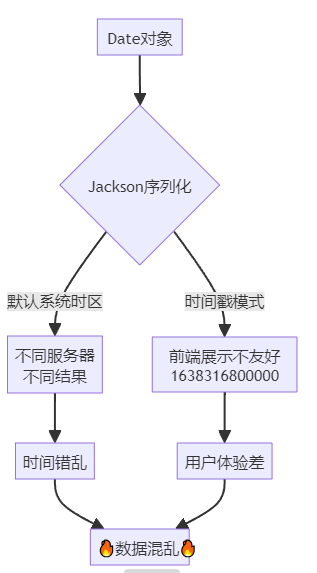
SaaS系统的时区困境:
分布式部署:不同云服务器可能在不同时区
全球业务:用户分布在不同国家,需要本地化时间
REST API:JSON序列化时,时区信息容易丢失
老李总结的时区配置原则:
| 层级 | 配置策略 | 强制要求 |
|---|---|---|
| 数据库 | 统一UTC时区 | 存储层标准化 |
| 应用 | 统一GMT+8 | 业务层标准化 |
| 序列化 | ISO 8601格式 | 传输层标准化 |
| 展示 | 用户本地时区 | 前端转换 |
生产级配置(老李标准版):
spring:
jackson:
time-zone: GMT+8 # 统一东八区
date-format: yyyy-MM-dd HH:mm:ss # 标准格式
serialization:
write-dates-as-timestamps: false # 禁用时间戳
fail-on-empty-beans: false
deserialization:
fail-on-unknown-properties: false
数据库配置(MySQL):
-- 设置MySQL时区为UTC
SET GLOBAL time_zone = '+00:00';
SET SESSION time_zone = '+00:00';
Java代码标准化:
// ✅ 正确姿势:始终使用带时区的类型
import java.time.ZonedDateTime;
import java.time.ZoneId;
@RestController
public class OrderController {
@PostMapping("/orders")
public OrderVO createOrder(@RequestBody OrderDTO dto) {
// 创建时统一使用ZonedDateTime
ZonedDateTime createTime = ZonedDateTime.now(ZoneId.of("Asia/Shanghai"));
Order order = new Order();
order.setCreateTime(createTime);
// ...
}
}
老李为一个全球SaaS平台设计的时区解决方案:
核心原则:
存储层:UTC时区,消除歧义
传输层:ISO 8601格式(2024-11-14T10:30:00+08:00),保留时区信息
展示层:根据用户设置转换到本地时区
2021年,老李的一个客户遭遇数据泄露。黑客通过/actuator/env端点,直接获取了数据库密码、Redis密码、第三方API密钥。
原因:为了方便监控,开发环境暴露了所有Actuator端点,部署时忘记修改配置。
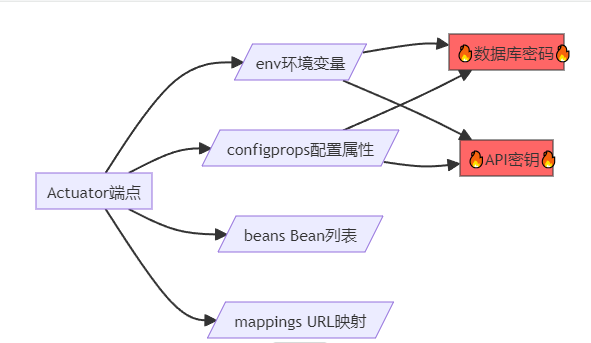
ToB系统的监控困境:
运维需求:需要暴露监控端点给Prometheus、Grafana
安全需求:不能泄露敏感信息给未授权用户
合规需求:等保三级要求访问控制和审计日志
老李的Actuator安全配置方法论:
第一层:最小化暴露
management:
endpoints:
web:
exposure:
include: health,info,metrics # 只暴露必要端点
base-path: /actuator # 自定义路径
endpoint:
health:
show-details: when-authorized # 授权后才显示详情
probes:
enabled: true
metrics:
enabled: true
第二层:Spring Security加固
@Configuration
@EnableWebSecurity
public class ActuatorSecurityConfig extends WebSecurityConfigurerAdapter {
@Override
protected void configure(HttpSecurity http) throws Exception {
http
.authorizeRequests()
.antMatchers("/actuator/health").permitAll() // 健康检查公开
.antMatchers("/actuator/**").hasRole("ADMIN") // 其他需要ADMIN权限
.anyRequest().authenticated()
.and()
.httpBasic(); // Basic认证
}
}
第三层:敏感信息脱敏
management:
endpoint:
env:
show-values: WHEN_AUTHORIZED # 授权后才显示值
configprops:
show-values: WHEN_AUTHORIZED
老李调查的一起真实案例:
攻击者扫描到/actuator/mappings端点,获取所有API路径
通过/actuator/env获取数据库连接信息
利用SQL注入漏洞,获取用户数据
最终造成50万用户信息泄露
防御措施:
生产环境禁止暴露env、configprops、beans等敏感端点
所有监控端点必须强制认证
使用独立监控网络,不对外暴露
老李负责的一个商品推荐系统,上线3天后突然崩溃:java.lang.OutOfMemoryError: Java heap space
排查发现:使用@Cacheable注解缓存商品数据,但默认使用ConcurrentHashMap,没有过期机制,没有大小限制。
随着缓存数据增长,JVM堆内存从2GB飙升到8GB,最终OOM。
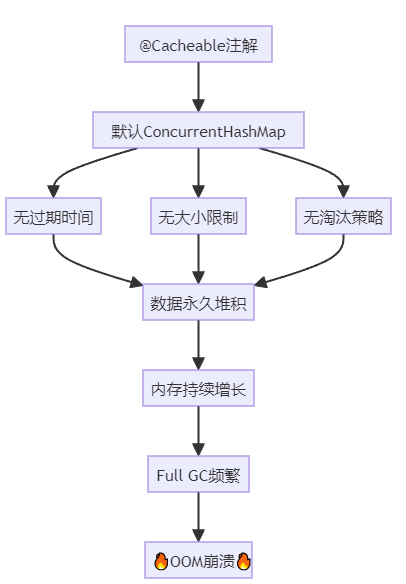
SaaS系统的缓存挑战:
多租户数据:每个租户的缓存数据都不同,容易爆炸
热点数据:少数商品或用户访问频繁,缓存倾斜
实时性要求:数据更新后,缓存必须及时失效
老李的缓存配置方法论(基于Caffeine):
为什么选Caffeine?
性能:比Guava Cache快3倍
淘汰算法:W-TinyLFU,命中率更高
内存效率:更少的GC压力
配置步骤:
引入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
</dependency>
配置文件
spring:
cache:
type: caffeine
cache-names: userCache,productCache,orderCache
caffeine:
spec: maximumSize=10000,expireAfterWrite=600s
Java配置(高级)
@Configuration
@EnableCaching
public class CacheConfig {
@Bean
public CacheManager cacheManager() {
CaffeineCacheManager cacheManager = new CaffeineCacheManager();
cacheManager.setCaffeine(Caffeine.newBuilder()
.maximumSize(10000) // 最大10000条
.expireAfterWrite(10, TimeUnit.MINUTES) // 10分钟过期
.recordStats()); // 启用统计
return cacheManager;
}
// 不同业务使用不同缓存策略
@Bean
public CaffeineCache hotDataCache() {
return new CaffeineCache("hotData",
Caffeine.newBuilder()
.maximumSize(1000)
.expireAfterWrite(1, TimeUnit.HOURS)
.build());
}
}
老李为一个电商SaaS设计的多级缓存方案:
| 缓存层级 | 技术选型 | 容量 | 过期时间 | 适用场景 |
|---|---|---|---|---|
| L1本地缓存 | Caffeine | 10000条 | 10分钟 | 热点商品 |
| L2分布式缓存 | Redis | 100万条 | 1小时 | 全量商品 |
| L3数据库 | MySQL | 无限 | 永久 | 冷数据 |
核心代码:
@Service
public class ProductService {
@Autowired
private CacheManager cacheManager;
@Autowired
private RedisTemplate<String, Object> redisTemplate;
@Autowired
private ProductRepository repository;
public Product getProduct(Long id) {
// L1:本地缓存
Cache l1Cache = cacheManager.getCache("productCache");
Product product = l1Cache.get(id, Product.class);
if (product != null) {
return product;
}
// L2:Redis缓存
String key = "product:" + id;
product = (Product) redisTemplate.opsForValue().get(key);
if (product != null) {
l1Cache.put(id, product); // 回填L1
return product;
}
// L3:数据库查询
product = repository.findById(id).orElse(null);
if (product != null) {
redisTemplate.opsForValue().set(key, product, 1, TimeUnit.HOURS);
l1Cache.put(id, product);
}
return product;
}
}
老李的一个客户投诉:订单列表页加载超过30秒,完全无法使用。
排查发现:查询100个订单,系统执行了301次SQL:
1次查询订单表
100次查询订单明细表
100次查询用户表
100次查询商品表
这就是著名的N+1查询问题——数据库直接被打崩。
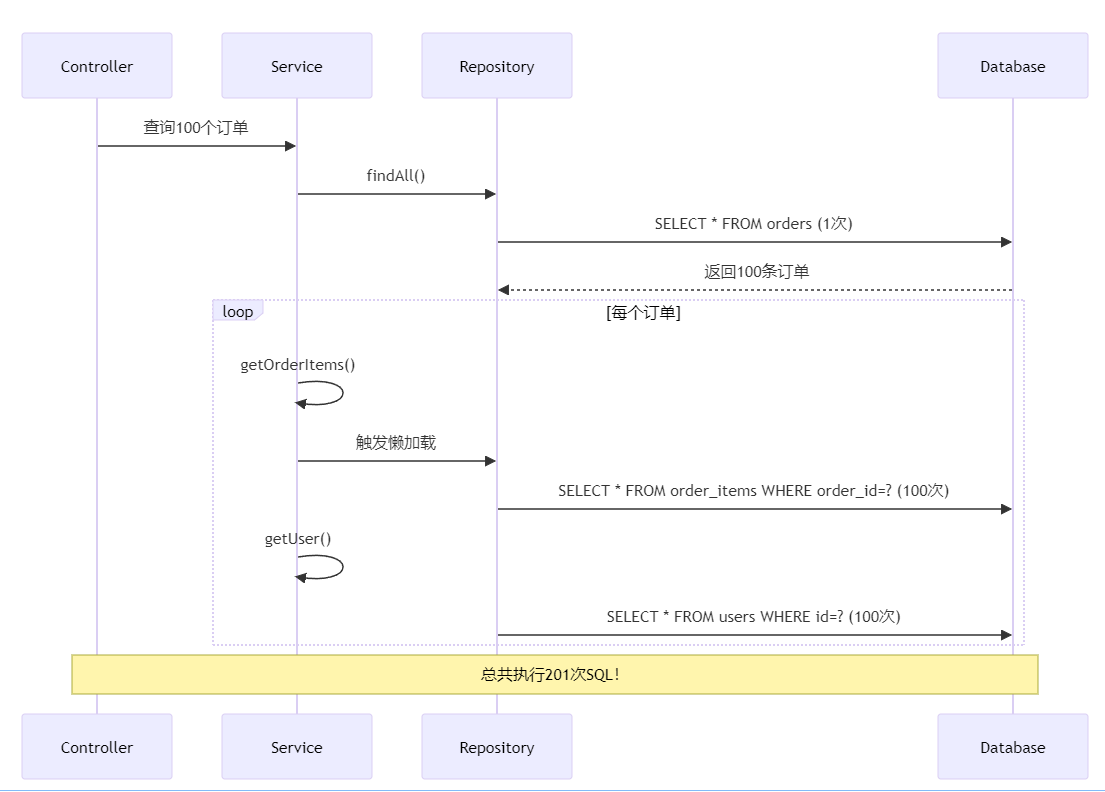
ToB系统的JPA困境:
复杂关联:订单→订单明细→商品→分类,多层级关联
列表查询:一次性查询大量数据,N+1问题放大
性能要求:ToB客户对响应时间敏感,超过3秒就投诉
老李总结的JPA优化方法论:
方案对比表格:
| 方案 | 技术 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| @EntityGraph | JPA标准 | 声明式,简单 | 灵活性稍差 | 固定查询模式 |
| JOIN FETCH | JPQL | 灵活,可定制 | 需要写JPQL | 复杂查询 |
| DTO投影 | Spring Data | 性能最优 | 需要定义DTO | 报表查询 |
方案一:@EntityGraph(推荐)
@Entity
@NamedEntityGraph(
name = "Order.detail",
attributeNodes = {
@NamedAttributeNode("orderItems"),
@NamedAttributeNode("user")
}
)
public class Order {
@Id
private Long id;
@ManyToOne(fetch = FetchType.LAZY)
private User user;
@OneToMany(fetch = FetchType.LAZY, mappedBy = "order")
private List<OrderItem> orderItems;
}
@Repository
public interface OrderRepository extends JpaRepository<Order, Long> {
@EntityGraph(value = "Order.detail", type = EntityGraph.EntityGraphType.LOAD)
List<Order> findAll(); // 一次SQL加载所有关联数据
}
方案二:JOIN FETCH(灵活)
@Repository
public interface OrderRepository extends JpaRepository<Order, Long> {
@Query("SELECT DISTINCT o FROM Order o " +
"LEFT JOIN FETCH o.orderItems oi " +
"LEFT JOIN FETCH o.user u " +
"WHERE o.status = :status")
List<Order> findAllWithDetails(@Param("status") String status);
}
方案三:DTO投影(性能最优)
// DTO定义
public interface OrderProjection {
Long getId();
String getOrderNo();
BigDecimal getTotalAmount();
String getUserName();
}
@Repository
public interface OrderRepository extends JpaRepository<Order, Long> {
@Query("SELECT o.id as id, o.orderNo as orderNo, " +
"o.totalAmount as totalAmount, u.name as userName " +
"FROM Order o LEFT JOIN o.user u")
List<OrderProjection> findAllProjections(); // 只查询需要的字段
}
老李对100条订单的查询进行压测:
| 方案 | SQL次数 | 响应时间 | 内存占用 | 评价 |
|---|---|---|---|---|
| 懒加载(默认) | 201次 | 3200ms | 120MB | ❌ 不可用 |
| @EntityGraph | 1次 | 85ms | 45MB | ✅ 推荐 |
| JOIN FETCH | 1次 | 78ms | 42MB | ✅ 推荐 |
| DTO投影 | 1次 | 52ms | 18MB | ✅ 性能最优 |
结论:使用@EntityGraph或JOIN FETCH,性能提升37倍!
老李在技术丛林中摸爬滚打十年,用8次生死时速换来了这8条铁律。
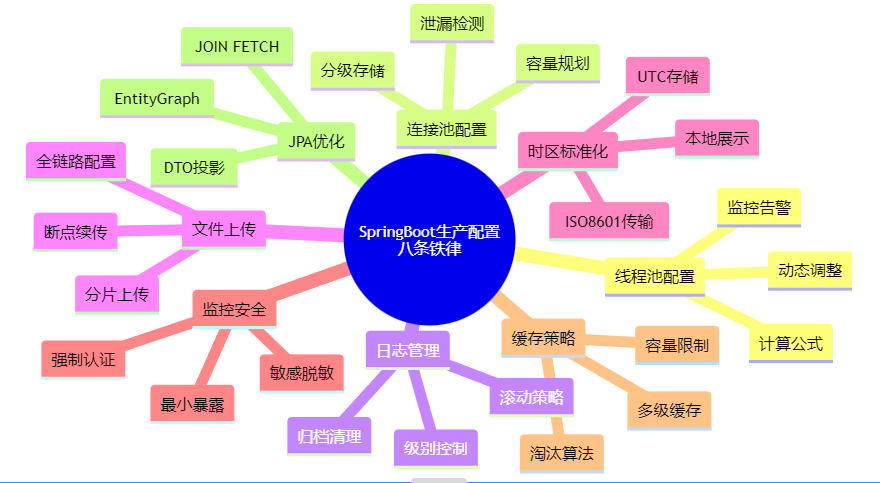
| 配置项 | 开发环境 | 生产环境 | 关键参数 |
|---|---|---|---|
| Tomcat线程池 | 默认200 | 800-1500 | max-threads, accept-count |
| Hikari连接池 | 默认10 | 50-150 | maximum-pool-size, leak-detection |
| 日志级别 | DEBUG | WARN | root, business-package |
| 文件上传 | 1MB | 100MB | max-file-size, max-request-size |
| 时区 | 系统时区 | GMT+8 | time-zone, date-format |
| Actuator | 全暴露 | 最小化 | include: health,info,metrics |
| 缓存 | 无限制 | Caffeine | maximumSize, expireAfterWrite |
| JPA | 懒加载 | EntityGraph | @EntityGraph, JOIN FETCH |
老李给所有ToB/SaaS开发者的行动清单:
? 紧急级(今晚必查):
检查Tomcat线程池配置,确认max-threads >= 500
检查数据库连接池,确认开启leak-detection-threshold
检查日志滚动策略,确认有max-file-size和max-history
检查Actuator暴露端点,确认没有env、configprops
⚠️ 重要级(本周完成):
压测核心API,确认P99响应时间< 1秒
配置文件上传限制,确认≥ 50MB
统一时区配置,确认使用GMT+8和ISO 8601
集成Caffeine缓存,替换默认ConcurrentHashMap
? 优化级(两周内):
使用@EntityGraph优化JPA查询
配置多级缓存(Caffeine + Redis)
接入APM监控(Skywalking/Pinpoint)
建立配置管理规范(生产/测试分离)
在技术丛林中,有三种人:
被淘汰的人:默认配置直接上生产,出事后甩锅给框架
勉强生存的人:知道要改配置,但不知道为什么改
强者生存的人:理解业务特征,用数据驱动配置决策
老李用十年时间,从第一种人变成了第三种人。这8个配置陷阱,每一个都是用血泪换来的教训。
SpringBoot的"开箱即用",从来不是让你无脑使用,而是降低学习门槛。真正的生产级应用,需要你深入理解业务、压测验证、持续优化。
记住:在技术丛林中,适者生存。你的系统活不过客户的业务高峰,你就活不过试用期。
为了帮助更多开发者避坑,老李把生产环境配置整理成了完整模板:
application-prod.yml(完整版):
# ==================== 服务器配置 ====================
server:
port: 8080
tomcat:
threads:
max: 800
min-spare: 100
max-connections: 10000
accept-count: 500
connection-timeout: 20000
# ==================== 数据库配置 ====================
spring:
datasource:
hikari:
maximum-pool-size: 50
minimum-idle: 10
connection-timeout: 30000
idle-timeout: 600000
max-lifetime: 1800000
leak-detection-threshold: 60000
# ==================== JPA配置 ====================
jpa:
show-sql: false
open-in-view: false
properties:
hibernate:
jdbc:
batch_size: 20
order_inserts: true
order_updates: true
# ==================== 文件上传 ====================
servlet:
multipart:
max-file-size: 100MB
max-request-size: 100MB
file-size-threshold: 2KB
location: /tmp/upload
resolve-lazily: true
# ==================== Jackson配置 ====================
jackson:
time-zone: GMT+8
date-format: yyyy-MM-dd HH:mm:ss
serialization:
write-dates-as-timestamps: false
# ==================== 缓存配置 ====================
cache:
type: caffeine
cache-names: userCache,productCache,orderCache
caffeine:
spec: maximumSize=10000,expireAfterWrite=600s
# ==================== 日志配置 ====================
logging:
file:
name: /var/log/your-app/app.log
level:
root: WARN
com.yourcompany: INFO
# ==================== 监控配置 ====================
management:
endpoints:
web:
exposure:
include: health,info,metrics
base-path: /actuator
endpoint:
health:
show-details: when-authorized
如果您时间宝贵,看这张图即可。



