

产品中心
在企业知识管理场景中,单纯的文本问答往往不能满足需求——用户可能需要上传图片、文档进行识别分析,也可能只是简单的文字提问。Dify 作为一款开源的 LLM 应用开发平台,提供了 Chatflow 编排能力,可以灵活地将知识库检索、条件分支、多模型调用组合在一起。
本文记录了一个实际场景:构建一个同时支持知识库问答和图片/文件识别的智能 Chat 系统。用户发送纯文字时,系统会从知识库检索相关内容后由 LLM 整合输出;当用户上传图片或文件时,系统会调用视觉模型进行识别分析。
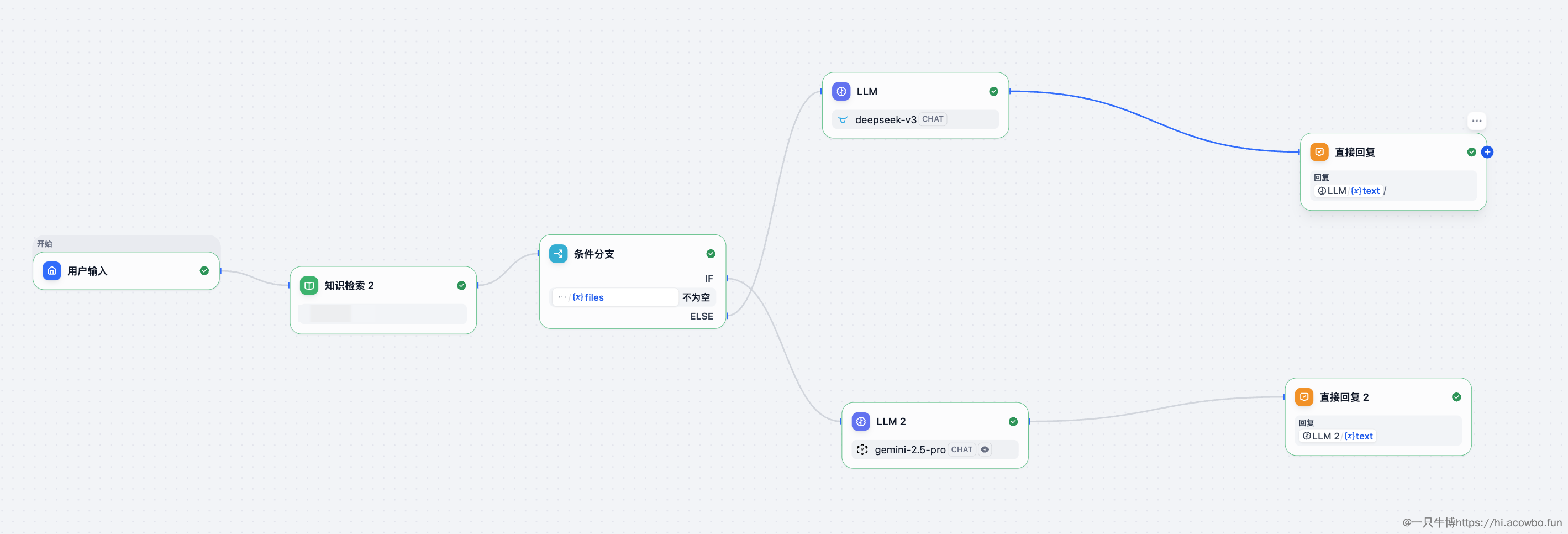
在动手配置之前,先梳理一下整个流程的逻辑架构:
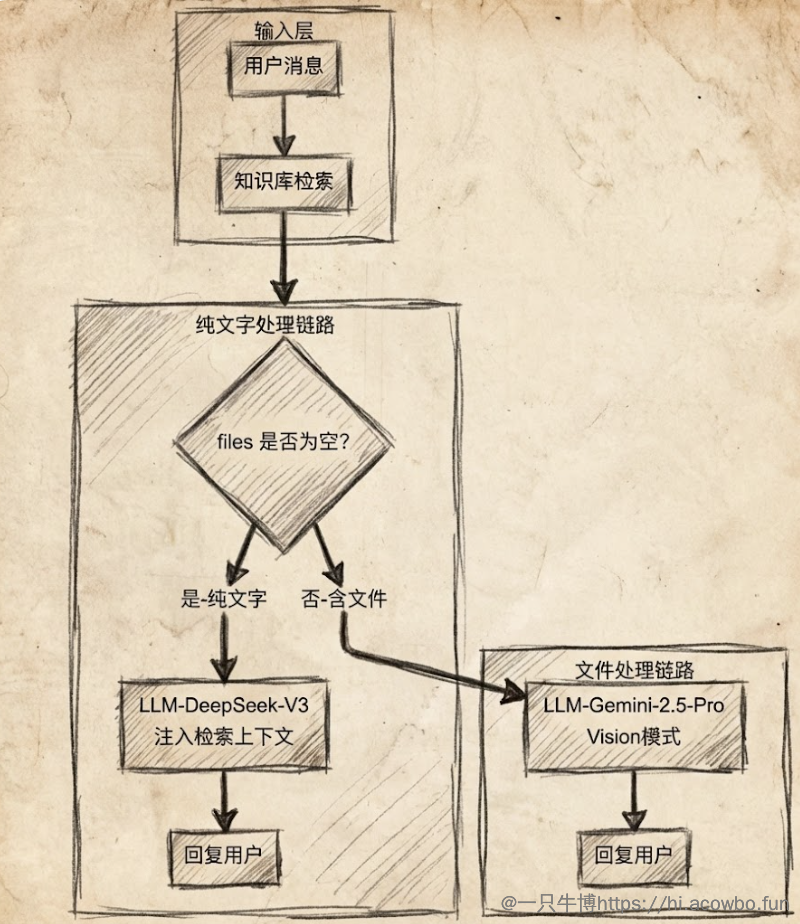
这个架构的核心思路是:先统一进行知识检索,再根据用户输入中是否包含文件来决定走哪条处理链路。知识检索前置的好处是,即使用户上传了文件,也可以结合知识库内容进行更智能的分析。
组件 | 版本/配置 |
|---|---|
Dify | Cloud 或 Self-hosted |
文本模型 | DeepSeek-V3 |
视觉模型 | Gemini-2.5-Pro |
知识库 | 已创建并导入文档 |
需要确保你的 Dify 账户已经配置好相应的模型 API Key。
进入 Dify 工作室,点击「创建应用」按钮,可以看到多种应用类型的选择:
Dify 提供了 Chatflow、工作流、聊天助手、Agent、文本生成 等多种类型。这里我们选择 Chatflow,它适合需要多轮对话且有复杂流程控制的场景。
另外一种快速开始的方式是从模板创建。Dify 官方提供了丰富的模板库:
可以看到「知识库 + 聊天机器人」这类模板,不过为了更好地理解原理,这里选择从空白 Chatflow 开始搭建。
整个 Chatflow 由以下几个核心节点组成:

创建 Chatflow 后,第一个节点是「用户输入」,需要配置两个输入字段:
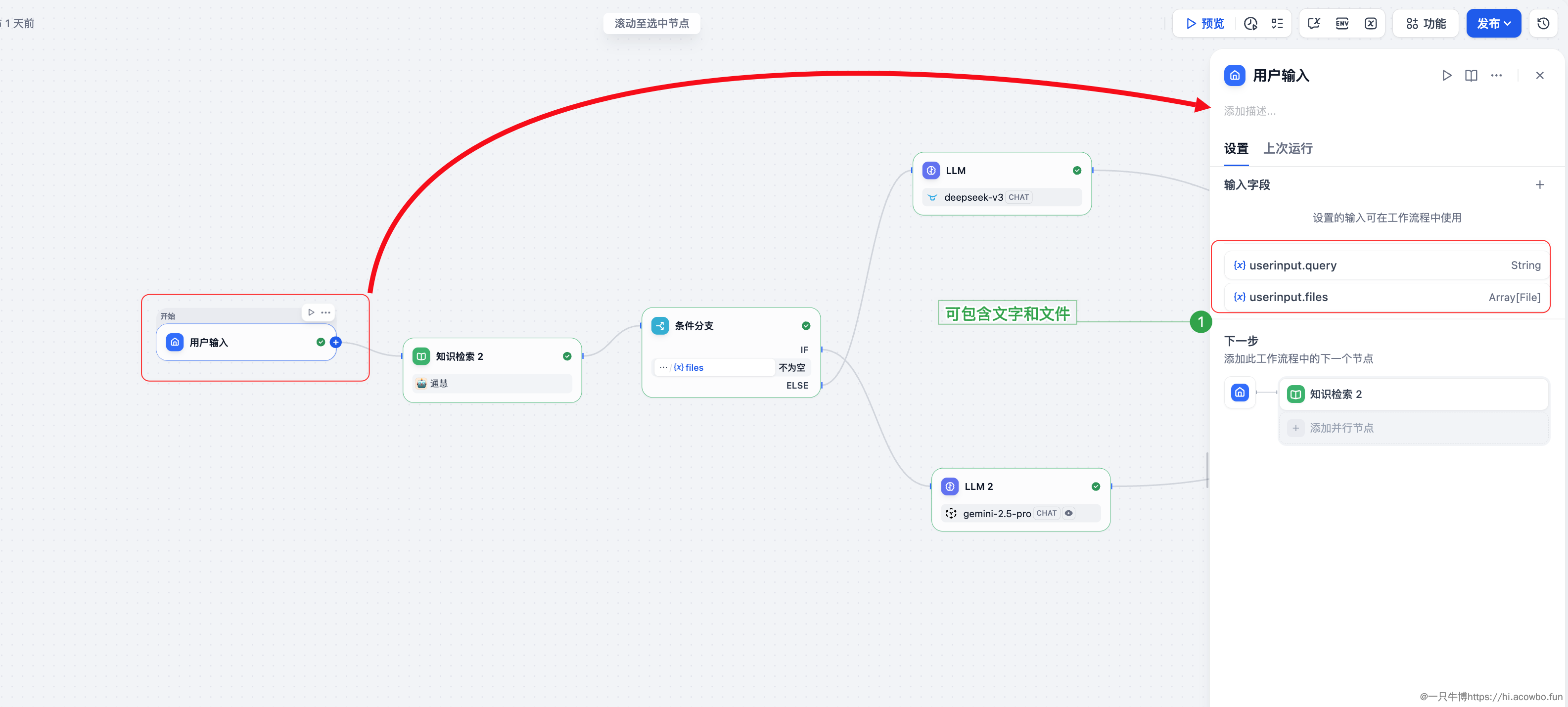
关键配置点:
配置完成后,这两个变量可以在后续节点中通过 {{用户输入.query}} 和 {{用户输入.files}} 引用。
用户输入之后,紧接着就是知识检索节点。这里的设计思路是:无论用户是否上传文件,都先进行一次知识库检索,为后续的 LLM 提供参考上下文。
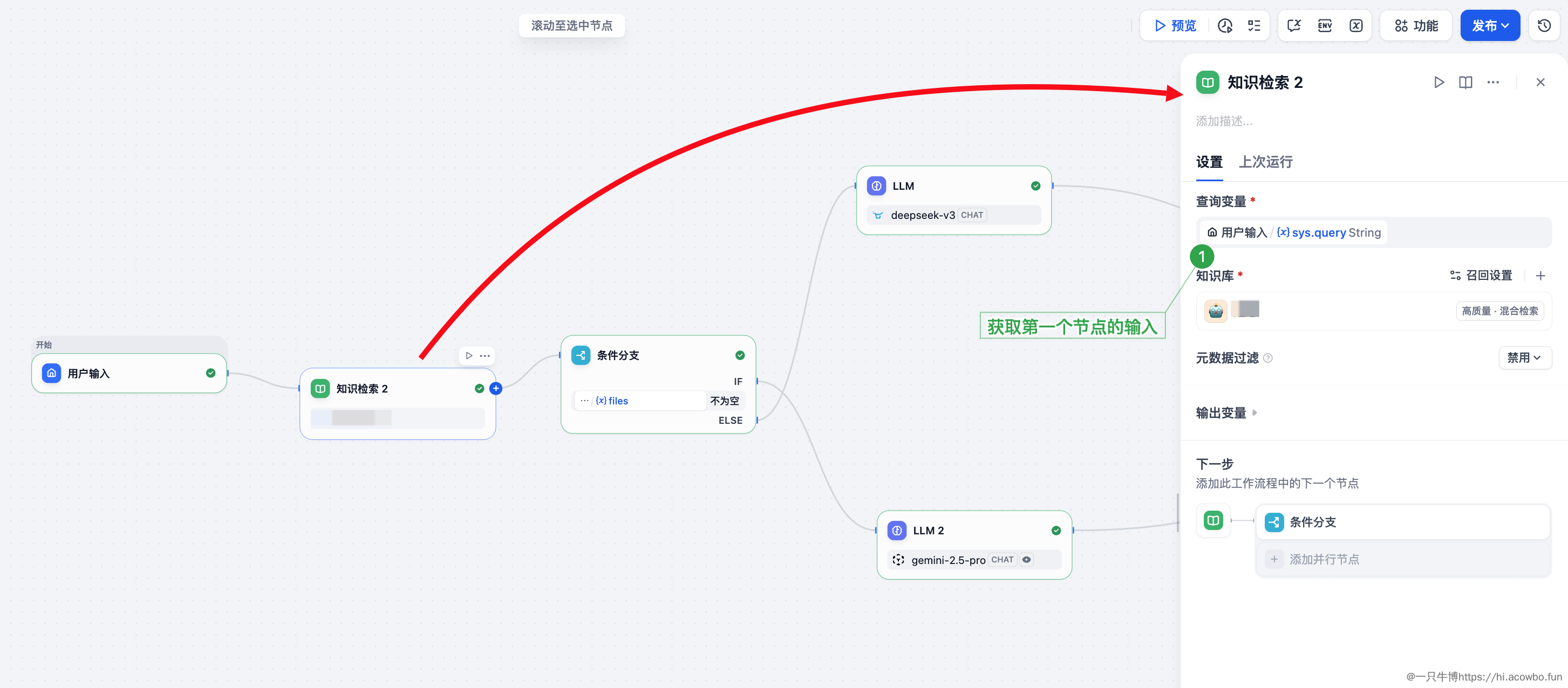
配置要点:
sys.query,即用户输入的文字内容知识检索节点的输出变量是 result,类型为 Array[Object],包含了检索到的文档片段。这个结果会传递给后续的条件分支,由分支决定如何使用。
知识检索完成后,进入条件分支节点。这是整个流程的路由中心——根据用户是否上传了文件来决定走哪条处理路径:
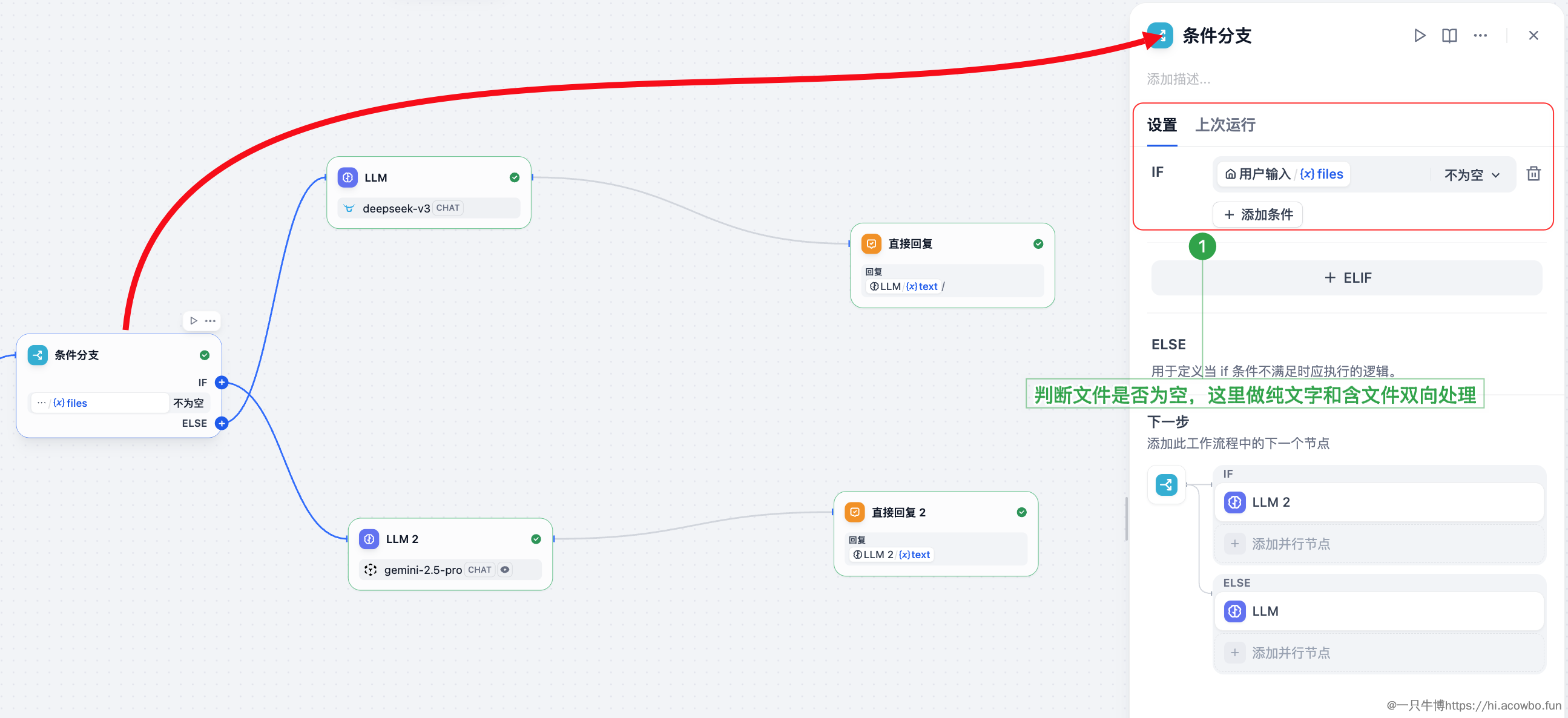
分支逻辑:
用户输入.files 不为空 → 走视觉模型链路(LLM2-Gemini)这样设计的好处是同一个 Chat 界面可以处理两种完全不同的需求,用户体验更加统一。
纯文字链路的 LLM 节点需要特别注意上下文配置:
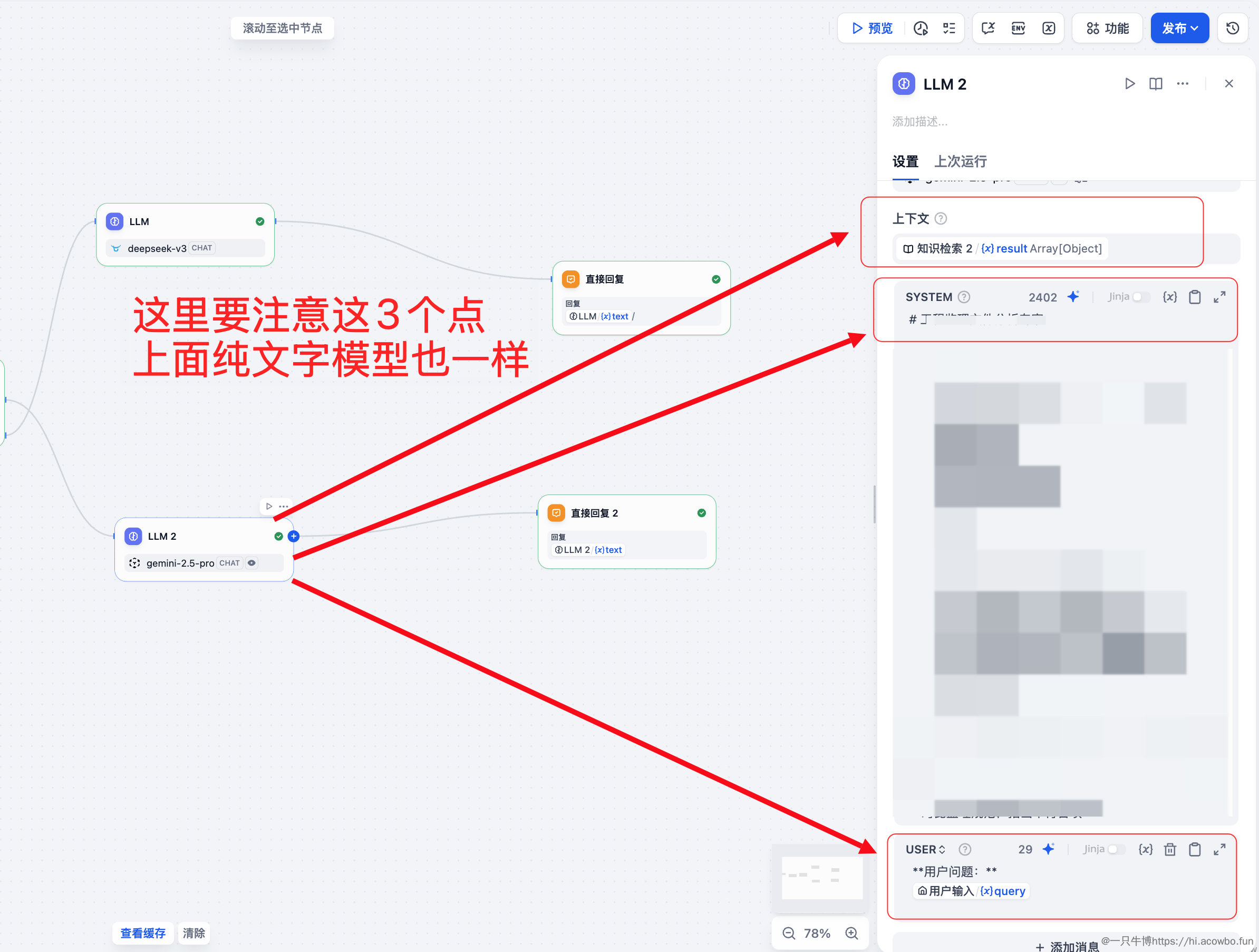
核心配置:
result 添加到上下文中Prompt 模板示例:
## 角色
你是一个智能助手,基于提供的知识库内容回答用户问题。
## 知识库内容
{{#context#}}
## 用户问题
{{用户输入.query}}
## 要求
- 基于知识库内容回答,不要编造
- 如果知识库中没有相关内容,诚实告知用户文件识别链路使用 Gemini-2.5-Pro,它具备强大的多模态理解能力:
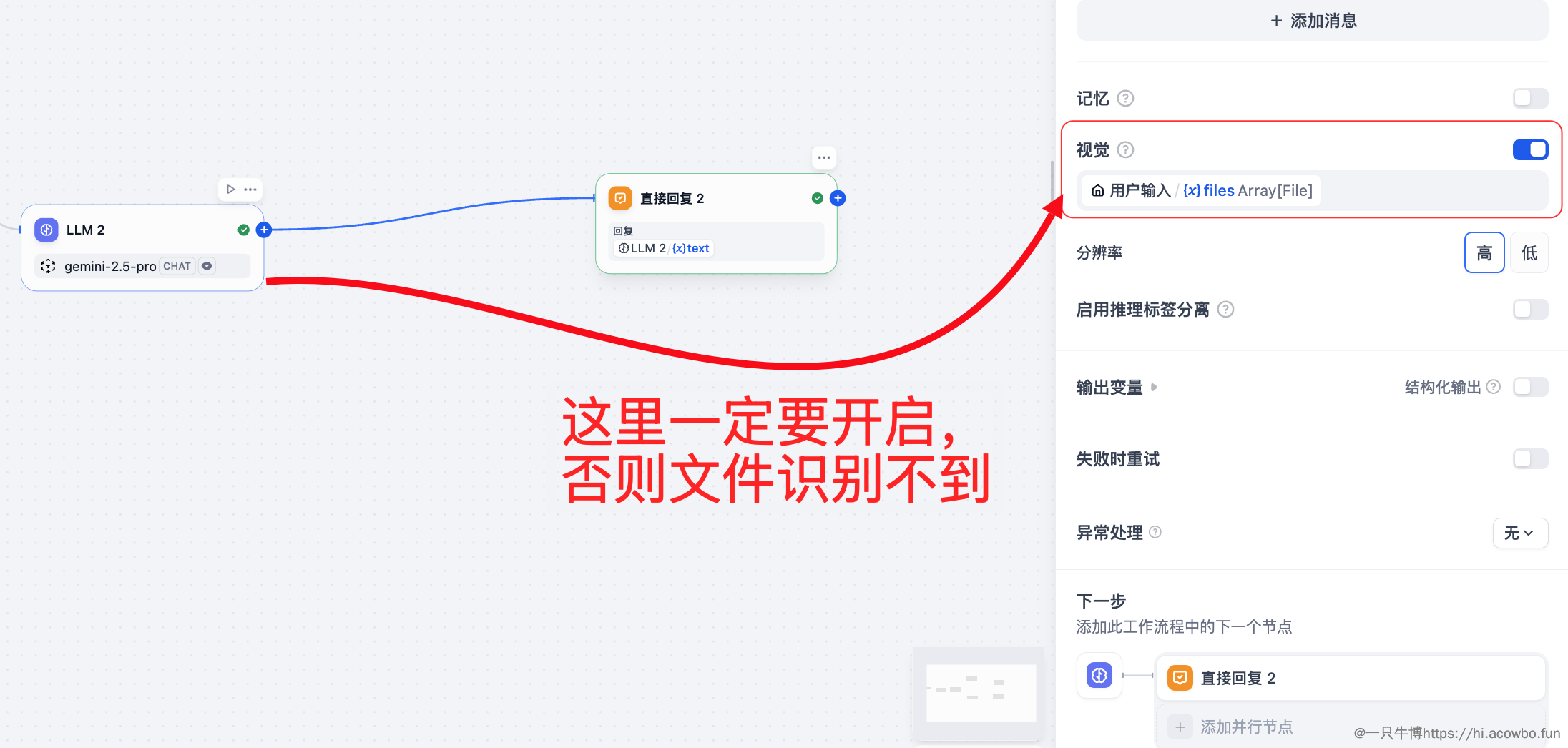
关键配置项——必须开启 Vision:
用户输入.files这是一个常见的踩坑点:如果不开启 Vision,即使用户上传了图片,模型也只会返回无法识别文件的提示。
所有节点配置完成后,最终的 Chatflow 如下:
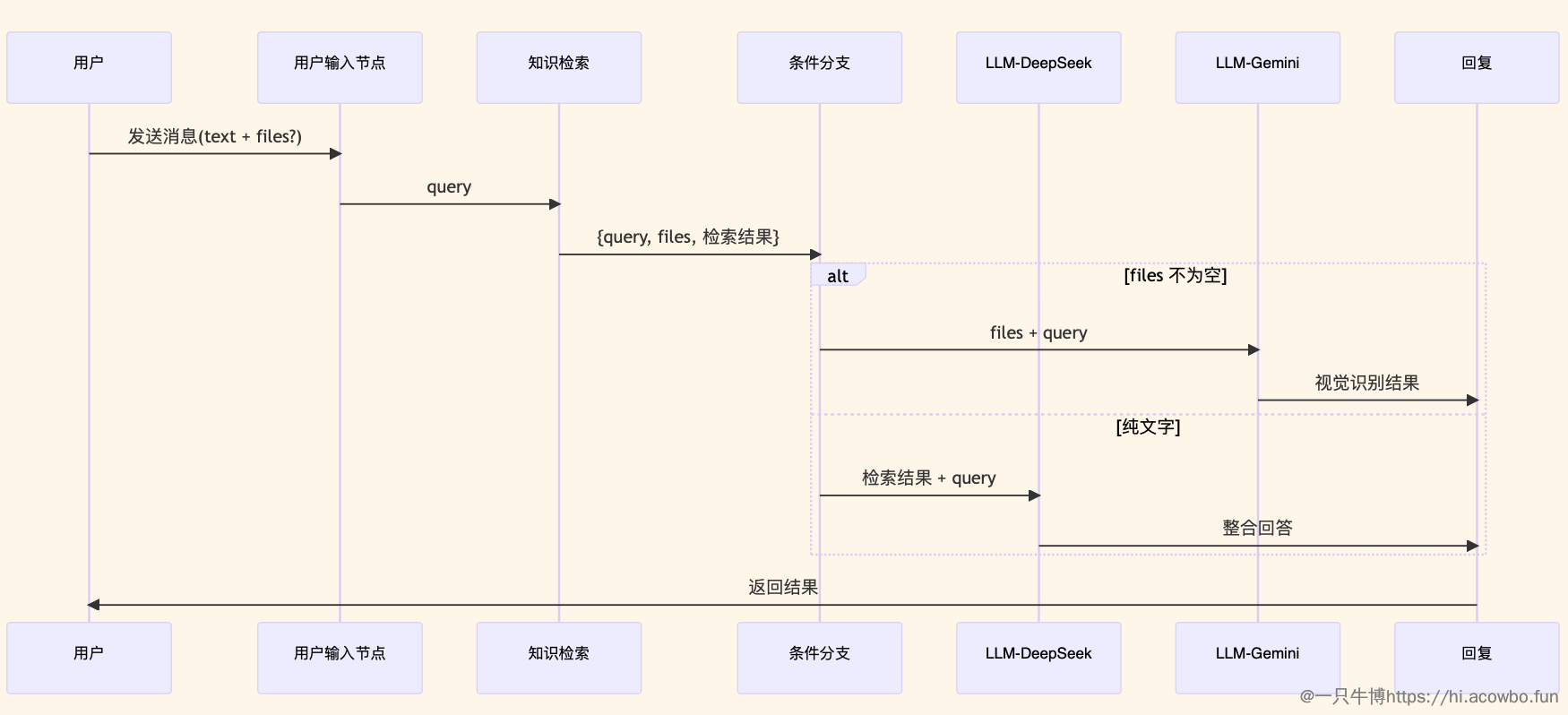
为了更清晰地理解数据在各节点间如何流转,这里用序列图展示:
发布 Chatflow 后,可以在预览界面进行测试:
场景一:纯文字问答
用户:什么是 RAG?
系统:[基于知识库检索结果回答]场景二:图片识别
用户:[上传一张截图] 帮我分析这张图片
系统:[调用 Gemini 视觉能力分析图片内容]两种场景在同一个 Chat 界面无缝切换,用户无需关心后台的处理逻辑。
检查 LLM 节点是否开启了 Vision 功能。这是最常见的配置遗漏,Gemini 等视觉模型需要显式开启才能处理图片输入。
确认知识库已正确导入文档,且文档已完成向量化索引。可以在知识库管理页面查看文档状态。
确保条件表达式使用的是正确的变量路径,files 不为空 的判断需要选择 用户输入.files 变量。
通过 Dify Chatflow 的可视化编排能力,我们实现了一个同时支持知识库问答和图片识别的智能 Chat 系统。整个配置的核心在于流程编排:用户输入后先统一进行知识检索,再由条件分支根据是否包含文件来路由——纯文字走 DeepSeek + 知识库上下文的 RAG 模式,文件上传则调用 Gemini 视觉模型。这种「检索前置 + 条件路由」的设计既保证了知识库的利用率,又能灵活支持多模态输入。后续可以在此基础上扩展更多分支(如 PDF 解析、音频转写),或在视觉模型中同样注入知识检索结果以实现更智能的图文混合分析。


