

产品中心
你有没有遇到过这样的场景:报表中本该显示数字的地方却是一片空白,只因为某个字段存在 NULL 值?或是编写复杂查询时,层层嵌套的 CASE WHEN 让逻辑变得臃肿难读?今天,就在处理一个看似简单的数据补偿需求时,我再次与这个老问题狭路相逢。而破局的关键,正是那个熟悉又常被低估的 SQL 函数,或者说过去我不怎么用过的函数——COALESCE 函数。
COALESCE 函数 远不止是处理空值的工具。在巧妙的构思下,它能化身为优雅的数据缝合者、默认值的守护者,甚至成为简化条件逻辑的利器。接下来,就让我们一起看看,这个简单的函数如何用一行代码,干净利落地解决了我的难题,或许也能为你打开新的思路。
今天在工作中遇到这样一个场景,在项目一中,用到了一个表,叫做 银行支行信息表 ,里面的数据是完善的。而在项目二中,同样的业务场景也需要用到这样一张表,同样叫做 银行支行信息表。但是不同的是,在项目一中,业务方已经很早就维护好了 银行支行信息表 中的数据,而在项目二 中,业务方由于有其他的事情耽误了,只是在银行支行信息表中维护了一个支行名称,而其他的字段还来不及去维护。
可是,马上就要用到 银行支行信息表 中的数据,项目二的业务方却还没有维护关键字段,怎么办呢?这个时候就考虑到,既然项目一和项目二中的业务场景一样,使用的 银行支行信息表 也是相似的表,且对于银行支行信息 这种固定不变的数据,不管是项目一和项目二,在这种基础数据上基本都一样,不会有很大差异。那么奔着求同存异的想法,也为了项目二可以快速投入使用,这里就考虑将项目一中 银行支行信息表 中的数据通过一条 SQL 补全到 项目二中相同 支行名称下缺失的字段中去。想法确定,开干!
既然上面我们已经定好了大概的方案,那么下面我们就需要来具体实施了。在实施之前,为了更好的讲述这个场景,我们先来准备两张表,其中假设表 t_base_data_bank01 是从项目一中拷贝过来的数据比较全的 银行支行信息表 ,t_base_data_bank 是项目二中对应的 数据不太全的 银行支行信息表。具体的建表sql 如下
// 项目二 数据不全的业务表
CREATE TABLE `t_base_data_bank` (
`ID` varchar(64) NOT NULL COMMENT 'id',
`BANK_NAME` varchar(128) NOT NULL COMMENT '银行名称',
`cnaps_code` varchar(64) DEFAULT NULL COMMENT '联行号',
`COUNTRY_NAME` varchar(64) DEFAULT NULL COMMENT '国家',
`country_code` varchar(64) DEFAULT NULL COMMENT '国家编码',
PRIMARY KEY (`ID`) USING BTREE,
KEY `idx_bank_name` (`BANK_NAME`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC COMMENT='银行信息表';
// 项目一 数据比较全的业务表
CREATE TABLE `t_base_data_bank01` (
`ID` varchar(64) NOT NULL COMMENT 'id',
`BANK_NAME` varchar(128) NOT NULL COMMENT '银行名称',
`cnaps_code` varchar(64) DEFAULT NULL COMMENT '联行号',
`COUNTRY_NAME` varchar(64) DEFAULT NULL COMMENT '国家',
`country_code` varchar(64) DEFAULT NULL COMMENT '国家编码',
PRIMARY KEY (`ID`) USING BTREE,
KEY `idx_bank_name` (`BANK_NAME`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC COMMENT='银行信息表';为了更好的演示数据,这里我们在上面两张示例表中先初始化一些数据,在表 t_base_data_bank 中初始化数据不全的数据
insert into t_base_data_bank (id,BANK_NAME) values('1','名称1');
insert into t_base_data_bank (id,BANK_NAME) values('2','名称2');
insert into t_base_data_bank (id,BANK_NAME) values('3','名称3');
insert into t_base_data_bank (id,BANK_NAME) values('4','名称4');
insert into t_base_data_bank values('5','名称5','666666','中国','CHN');在表 t_base_data_bank01 中初始化数据比较全的数据
insert into t_base_data_bank01 values('1','名称1','111111','中国','CHN');
insert into t_base_data_bank01 values('2','名称2','222222','中国','CHN');
insert into t_base_data_bank01 values('3','名称3','333333','中国','CHN');
insert into t_base_data_bank01 values('4','名称4','444444','中国','CHN');
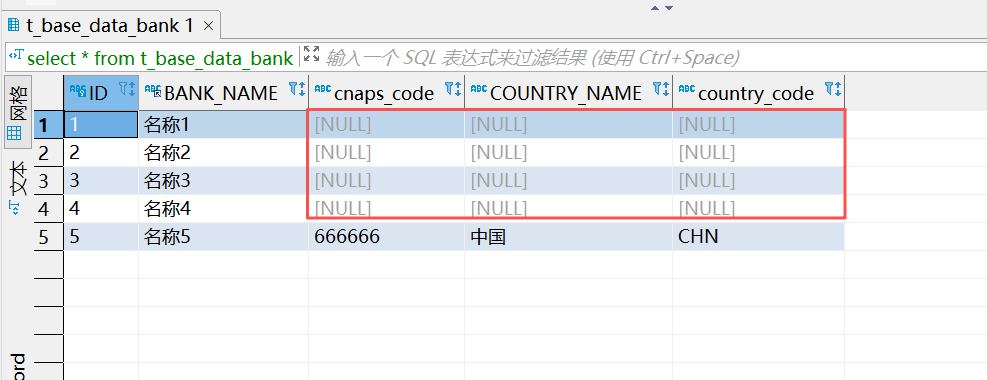
insert into t_base_data_bank01 values('5','名称5','555555','中国','CHN');数据初始化之后,查看数据表中的数据,其中,select * from t_base_data_bank; 可以看到有一部分数据不全
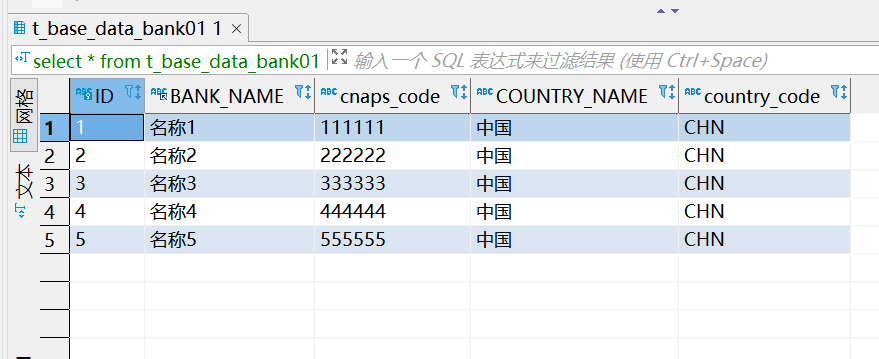
执行sql 查询 select * from t_base_data_bank01; 可以看到这张表中数据是全的
到这里我们的数据表以及初始化数据已经准备完了。下面我们就开始处理我们上面业务场景中描述的问题了。
在补全数据之前,给大家介绍一个投机的好办法。CodeBuddy 相信大家都比较熟悉吧,具体的产品介绍,这里我就不详细说了。我就说一下具体怎么投机就行了。其实很简单,我们将我们的需求通过文字描述好之后,让 CodeBuddy 帮我们写好SQL ,然后我们直接执行就可以了。就像上面的需求,转化成文字描述就像这样
对比 表 table_a 和 table_b ,根据 table_a 的 bank_name 和 table_b 的 bank_name 关联,如果 table_a 中 cnaps_code 、COUNTRY_NAME 、country_code 为空 则用 table_b 对应字段的值补充,写sql 实现将我们的需求转述成 AI 容易识别的描述后,放入 CodeBuddy 的AI 对话框中,此时可以看到 AI 会根据我们的需求对我们的需求进行分析,并根据我们的需求直接为我们生成我们想要的 SQL 语句,那么下面我们就直接用这个 SQL 来执行
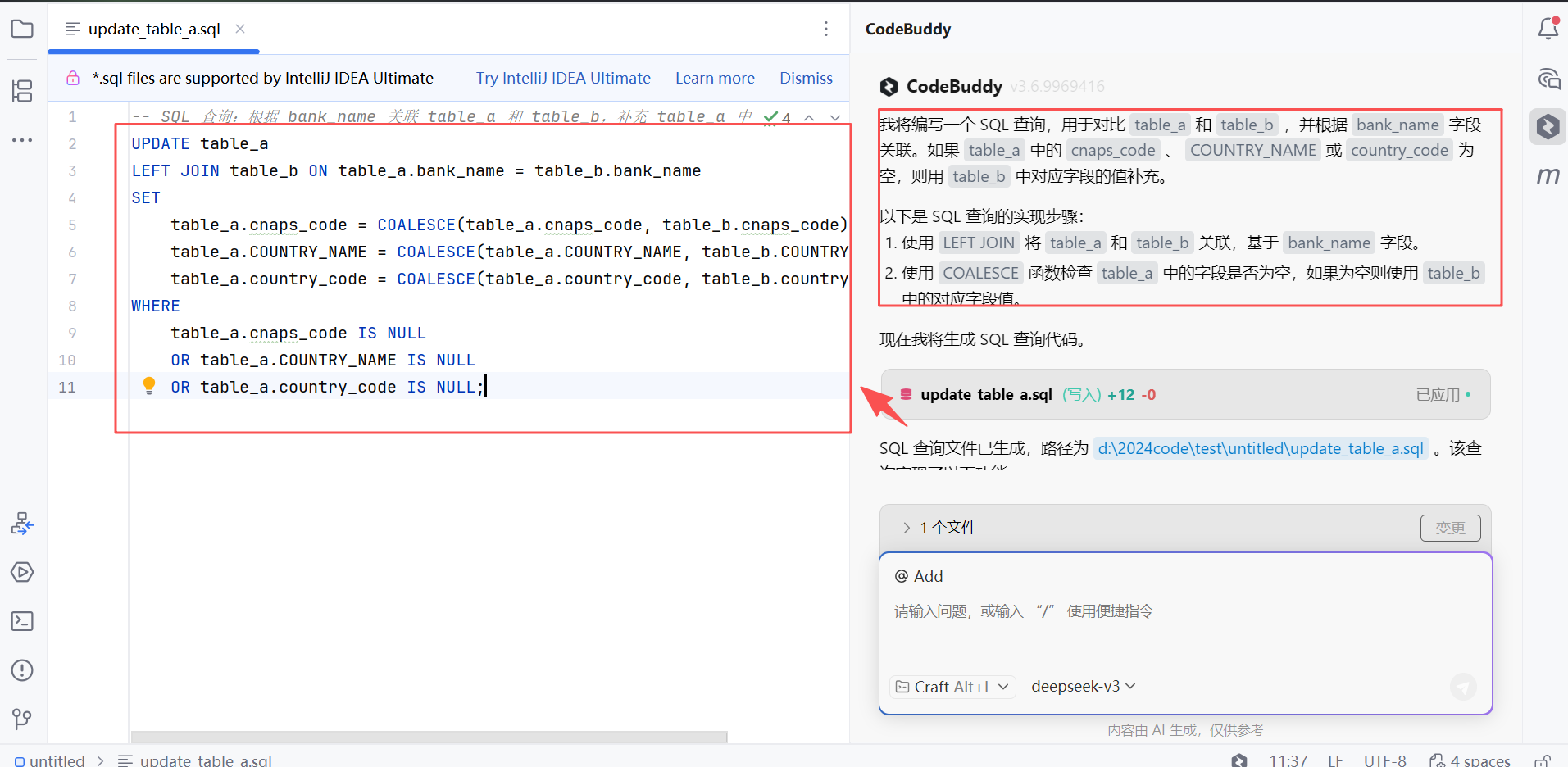
执行之前需要将 上述sql 中的 表名 table_a 和 table_b 替换为 t_base_data_bank 和 t_base_data_bank01 ,替换完成之后的 sql 语句如下
UPDATE t_base_data_bank
LEFT JOIN t_base_data_bank01 ON t_base_data_bank.bank_name = t_base_data_bank01.bank_name
SET
t_base_data_bank.cnaps_code = COALESCE(t_base_data_bank.cnaps_code, t_base_data_bank01.cnaps_code),
t_base_data_bank.COUNTRY_NAME = COALESCE(t_base_data_bank.COUNTRY_NAME, t_base_data_bank01.COUNTRY_NAME),
t_base_data_bank.country_code = COALESCE(t_base_data_bank.country_code, t_base_data_bank01.country_code)
WHERE
t_base_data_bank.cnaps_code IS NULL
OR t_base_data_bank.COUNTRY_NAME IS NULL
OR t_base_data_bank.country_code IS NULL;
执行上述sql 语句之后,我们来查看一下我们项目二的 银行支行信息表 t_base_data_bank 中的数据,看看是不是都补全了
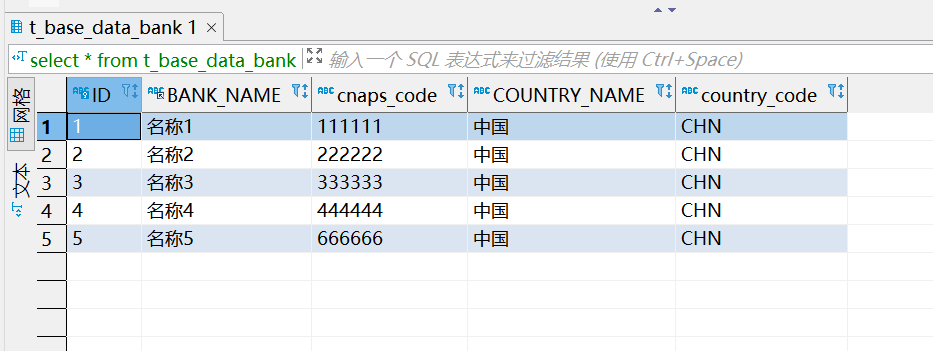
这里我们可以看到,项目二表 t_base_data_bank 中缺失的数据都通过 sql 补全过来了,其中 id = 5 的数据在一开始就是全的,所以执行上面的 sql 并没有将 t_base_data_bank01 中对应数据字段覆盖,是符合我们的补全业务数据的需求的。
到这里,我们的业务需求是完成了,但是我们用到了一个 Mysql 函数 — COALESCE。为了更好的理解这个函数,我们来详细介绍一下吧。
COALESCE函数是SQL中的一个标准函数,用于从参数列表中返回 第一个非NULL值。如果所有参数都为NULL,则返回NULL。
在实际数据库查询中,我们经常遇到需要处理NULL值的情况,COALESCE(table_a.cnaps_code, table_b.cnaps_code)就是一个典型的解决方案。
函数功能解析 COALESCE函数是SQL中处理NULL值的利器,它按顺序检查参数列表,返回第一个非NULL的值。在上面我们提到的场景中,它会:
首先检查table_a.cnaps_code
如果为NULL,则检查table_b.cnaps_code
如果两者都为NULL,则返回NULL
就像上面我们介绍的一样,在银行系统中,对于 银行支行信息表 中的数据,虽然业务方可能不同,但是像这种 银行支行信息 数据往往是比较固定的。因此就可以用到上面我们说的通过 COALESCE函数 来在不同的项目之间来补全缺失的字段数据。
除了上面的情况,或者是在银行或金融机构系统中,联行号(CNAPS Code)存储在不同的表中。比如: table_a存储主要账户信息 table_b存储备用或历史账户信息 当主要账户缺少联行号时,可以从备用表中获取。
比如我们想要获取表中的 cnaps_code 数据,我们就可以通过下面的查询
SELECT
a.account_no,
COALESCE(a.cnaps_code, b.cnaps_code) AS final_cnaps_code
FROM table_a a
LEFT JOIN table_b b ON a.BANK_NAME = b.BANK_NAME虽然说COALESCE函数 很好用,但是我们也要根据实际情况来使用,而不能滥用,比如不能有太多的嵌套,嵌套太多,可读性,可维护性都比较差
COALESCE(table_a.code, table_b.code, table_c.code, table_d.code, ...)或者也可以配合索引使用,这里我们为我们的字段 cnaps_code 创建索引,
create index cnaps_idx on t_base_data_bank(cnaps_code);
create index cnaps_idx on t_base_data_bank01(cnaps_code);下面执行以下两个 sql 来看一下具体的效果,第一个sql 是没有走 索引的 查询
SELECT COALESCE(a.cnaps_code, b.cnaps_code)
FROM t_base_data_bank a
LEFT JOIN t_base_data_bank01 b ON a.bank_name = b.bank_name
WHERE COALESCE(a.cnaps_code, b.cnaps_code) = '111111';下面我们来看一下 Mysql 的执行计划
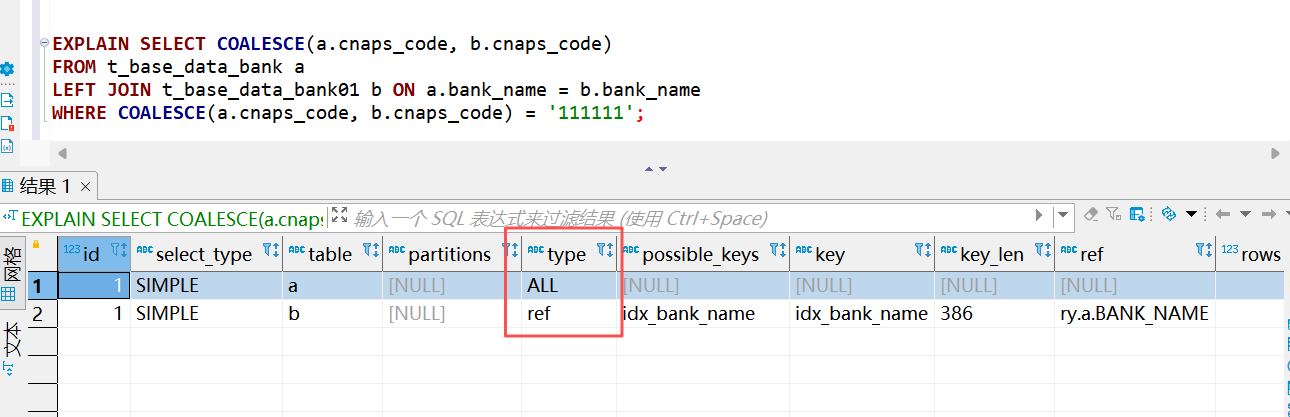
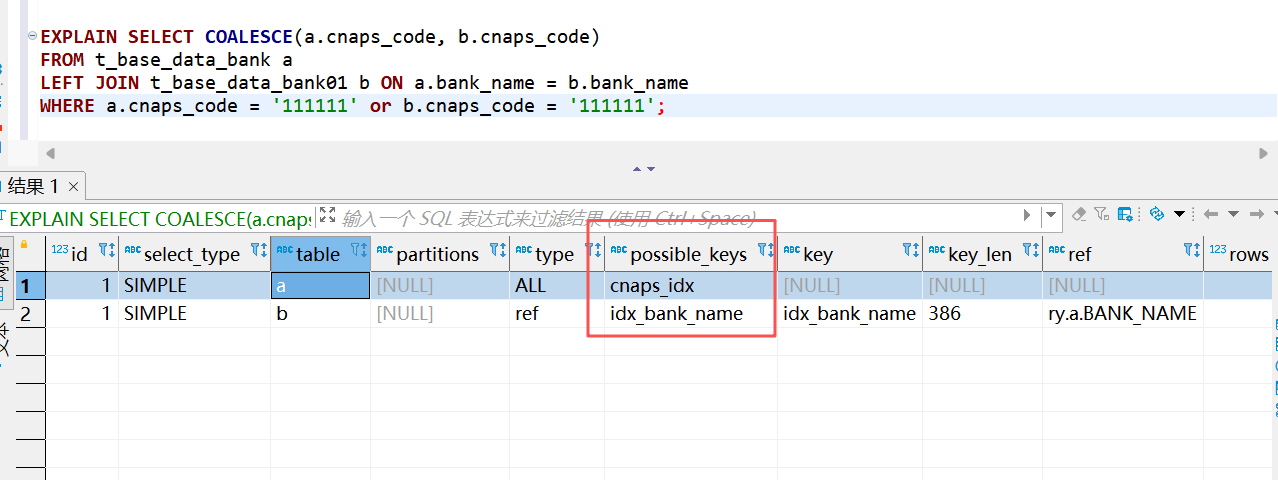
我们更改以下sql 语句后,变成为第二个sql ,第二个sql 是会走索引的
SELECT COALESCE(a.cnaps_code, b.cnaps_code)
FROM t_base_data_bank a
LEFT JOIN t_base_data_bank01 b ON a.bank_name = b.bank_name
WHERE a.cnaps_code = '111111' or b.cnaps_code = '111111'; 此时我们可以看到则是会触发 a 表的索引的,因此说即使 COALESCE函数 好用,也不能到处乱用的
函数 | 功能 | 区别 |
|---|---|---|
| 返回第一个非NULL值 | 可接受多个参数 |
| 如果value1为NULL则返回value2 | MySQL特有,只能两个参数 |
| 判断是否为NULL | 返回布尔值 |
| 两值相等时返回NULL | 用于特殊情况处理 |
COALESCE(table_a.cnaps_code, table_b.cnaps_code) 不仅仅是一个简单的NULL值处理函数,它体现了数据冗余设计的智慧,是构建健壮数据库查询的重要工具。在实际应用中,合理使用COALESCE可以:
提高数据查询的完整性
增强系统的容错能力
简化复杂的业务逻辑处理
优化多数据源整合的查询效率
理解其工作原理和适用场景,对于设计高质量的数据访问层和编写高效的SQL语句至关重要。
在实际工作中,数据的不完整性常常是开发过程中的痛点。本文通过一个具体的银行支行信息数据补全案例,展示了如何利用 SQL 的 COALESCE 函数优雅地解决跨项目数据缺失问题。面对项目二数据表关键字段缺失的困境,我们并没有选择复杂的手动维护或冗长的条件判断,而是通过 COALESCE 函数配合 LEFT JOIN,用一条简洁的 UPDATE 语句实现了智能数据填充—仅当目标表字段为 NULL 时,才用源表的对应值补全。
COALESCE 函数在此扮演了数据优先级选择器的角色,它按顺序返回参数中第一个非 NULL 的值,完美契合了 【补缺失而非覆盖】的业务需求。这个案例不仅解决了眼前的问题,更揭示了处理类似场景的通用思路:利用标准 SQL 函数将复杂的业务逻辑简化,提升代码的可读性和可维护性。
同时,我们也需要注意,虽然 COALESCE 强大便捷,但需注意其性能影响,特别是在结合 WHERE 子句使用时可能破坏索引效率。掌握其原理并合理运用,方能使其真正成为提升开发效率的利器。每一次对这类基础函数的深入理解,都是我们构建更健壮、更优雅数据应用的一块基石。


