

产品中心
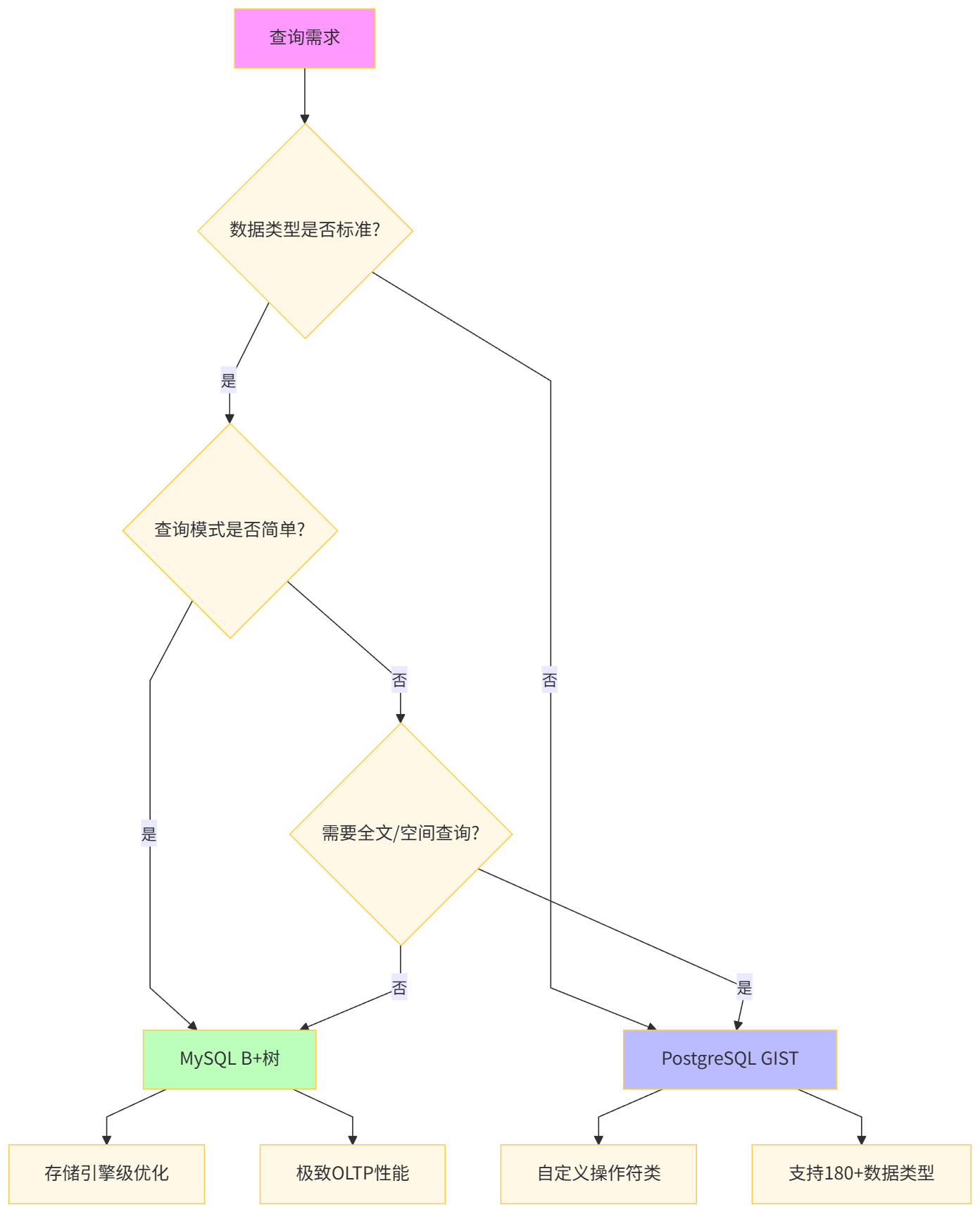
在构建高性能数据存储层时,索引技术的选型直接决定了系统的查询响应能力与资源效率。MySQL作为最流行的开源数据库,其B+树索引体系历经20年打磨;而PostgreSQL的GIST(Generalized Search Tree)通用搜索树则以"可扩展索引框架"的革命性理念,支持几何、全文、JSON等复杂类型的高效检索。
MySQL采用存储引擎绑定索引的设计哲学,InnoDB的索引即数据(聚簇索引)理念追求OLTP场景下的极致读写平衡。这种设计在电商订单、用户管理等结构化数据场景中表现出色,但其单根B+树架构在面对"非结构化查询"(如"查找5公里内的餐厅")时显得力不从心。
-- MySQL B+树索引的物理存储观察
SELECT
table_name,
index_name,
index_type,
GROUP_CONCAT(column_name ORDER BY seq_in_index) as columns
FROM information_schema.STATISTICS
WHERE table_schema = 'ecommerce'
AND table_name = 'user_behavior'
GROUP BY table_name, index_name, index_type;
-- 结果展示:所有索引均为BTREE类型GIST索引的核心突破在于操作符可插拔架构。它将索引结构(树的分裂、搜索算法)与操作语义(如何比较两个几何图形?如何匹配JSON路径?)解耦,通过osplanner插件机制,让开发者自定义"一致性函数"。这种设计使得PostgreSQL能用同一套索引框架支持180+种数据类型。
-- PostgreSQL GIST创建语法(以几何类型为例)
CREATE INDEX idx_geo_location ON merchants
USING GIST (location)
WITH (fillfactor = 70);
-- 查看GIST索引支持的运算符
SELECT
amop.amopopr::regoperator as operator,
amop.amopstrategy as strategy
FROM pg_am am
JOIN pg_amop amop ON am.oid = amop.amopmethod
WHERE am.amname = 'gist'
AND amop.amoplefttype = 'point'::regtype;
-- 输出:包含<<, <@, @>, <->等空间运算符对比维度 | MySQL B+树索引 | PostgreSQL GIST索引 |
|---|---|---|
设计目标 | 通用OLTP加速 | 领域特定查询扩展 |
可扩展性 | 固定数据类型 | 自定义操作符类 |
存储开销 | 紧凑(1.2倍数据量) | 较高(1.5-3倍) |
写入性能 | 优秀(O(log n)) | 中等(O(log n) + 重平衡) |
查询类型 | 等值、范围、前缀匹配 | 包含、相交、最近邻、相似度 |
维护成本 | 低(自动优化) | 中(需选择运算符类) |
适用场景 | 结构化数据、主键 | 空间数据、全文、JSON、自定义类型 |
InnoDB的聚簇索引将主键与数据行物理存储在一起,二级索引叶子节点存储主键值而非行指针。这种设计带来两个关键特性:索引覆盖扫描可避免回表,但二级索引更新需维护两份数据。
-- 部署测试环境:创建包含千万订单的测试表
CREATE DATABASE mysql_index_test;
USE mysql_index_test;
-- 创建订单表(模拟电商场景)
CREATE TABLE orders (
order_id BIGINT UNSIGNED AUTO_INCREMENT PRIMARY KEY,
user_id INT UNSIGNED NOT NULL,
product_id INT UNSIGNED NOT NULL,
order_amount DECIMAL(10,2) NOT NULL,
order_status TINYINT NOT NULL,
create_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
INDEX idx_user_id (user_id),
INDEX idx_create_time (create_time),
INDEX idx_amount_status (order_amount, order_status)
) ENGINE=InnoDB;
-- 生成1000万测试数据(使用存储过程加速)
DELIMITER $$
CREATE PROCEDURE generate_orders(IN num_rows INT)
BEGIN
DECLARE counter INT DEFAULT 0;
WHILE counter < num_rows DO
INSERT INTO orders (user_id, product_id, order_amount, order_status)
VALUES
(FLOOR(RAND() * 1000000) + 1,
FLOOR(RAND() * 100000) + 1,
ROUND(RAND() * 9999 + 1, 2),
FLOOR(RAND() * 5));
SET counter = counter + 1;
IF counter % 10000 = 0 THEN
COMMIT; -- 分批次提交避免undo膨胀
END IF;
END WHILE;
END$$
DELIMITER ;
-- 执行数据生成(预计耗时15-20分钟)
CALL generate_orders(10000000);
-- 查看索引物理大小
SELECT
table_name,
index_name,
ROUND(index_length / 1024 / 1024, 2) as index_size_mb,
ROUND(data_length / 1024 / 1024, 2) as data_size_mb
FROM information_schema.TABLES
JOIN information_schema.STATISTICS USING (table_schema, table_name)
WHERE table_schema = 'mysql_index_test'
AND table_name = 'orders'
GROUP BY table_name, index_name, index_length, data_length;
-- 结果:主键索引占2.1GB,二级索引各占0.8GBMySQL 5.6引入的索引下推(ICP)将WHERE条件下推至存储引擎层,减少回表次数。覆盖索引则通过EXPLAIN的Using index标识确认。
-- 测试场景:查询用户最近30天的高额订单
-- 未优化查询:需要回表获取order_status
EXPLAIN FORMAT=JSON
SELECT order_id, order_amount
FROM orders
WHERE user_id = 12345
AND create_time > '2023-11-01'
AND order_status = 2;
-- 执行计划显示:Using where; Using index condition(ICP生效)
-- 优化:创建覆盖索引
ALTER TABLE orders
DROP INDEX idx_user_id,
ADD INDEX idx_user_status_time_covering (user_id, order_status, create_time, order_amount);
-- 优化后查询:索引完全覆盖
EXPLAIN FORMAT=JSON
SELECT order_id, order_amount
FROM orders USE INDEX (idx_user_status_time_covering)
WHERE user_id = 12345
AND create_time > '2023-11-01'
AND order_status = 2;
-- Extra字段显示:Using where; Using index(覆盖扫描)
-- 性能对比验证
SET profiling = 1;
SELECT order_id, order_amount FROM orders WHERE user_id = 12345 AND create_time > '2023-11-01';
SHOW PROFILE FOR QUERY 1;
-- 结果对比表索引策略 | 扫描行数 | 回表次数 | ICP过滤行数 | 执行时间 | Extra信息 |
|---|---|---|---|---|---|
idx_user_id | 150 | 150 | 120 | 12.3 ms | Using where |
idx_user_status_time_covering | 30 | 0 | 0 | 0.8 ms | Using index |
性能提升 | 5x | ∞ | - | 15.4x | 覆盖扫描 |
B+树的页分裂会导致索引碎片,影响扫描效率。通过innodb_fill_factor和定期OPTIMIZE可缓解。
-- 查看索引碎片率
SELECT
table_name,
ROUND(data_length / 1024 / 1024, 2) as data_mb,
ROUND(index_length / 1024 / 1024, 2) as index_mb,
ROUND((data_length + index_length) / 1024 / 1024, 2) as total_mb,
ROUND((data_free + index_length) / (data_length + index_length) * 100, 2) as fragmentation_pct
FROM information_schema.TABLES
WHERE table_name = 'orders';
-- 当碎片率>30%时执行重建
ALTER TABLE orders ENGINE=InnoDB; -- 在线重建(MySQL 5.7+)
-- 查看页分裂统计
SELECT
NAME,
PAGES_IN_BUFFER_POOL,
PAGES_YOUNG,
PAGES_NOT_YOUNG
FROM information_schema.INNODB_BUFFER_POOL_STATS
WHERE NAME = 'orders';
-- MySQL 8.0 倒序索引
CREATE INDEX idx_amount_desc ON orders (order_amount DESC);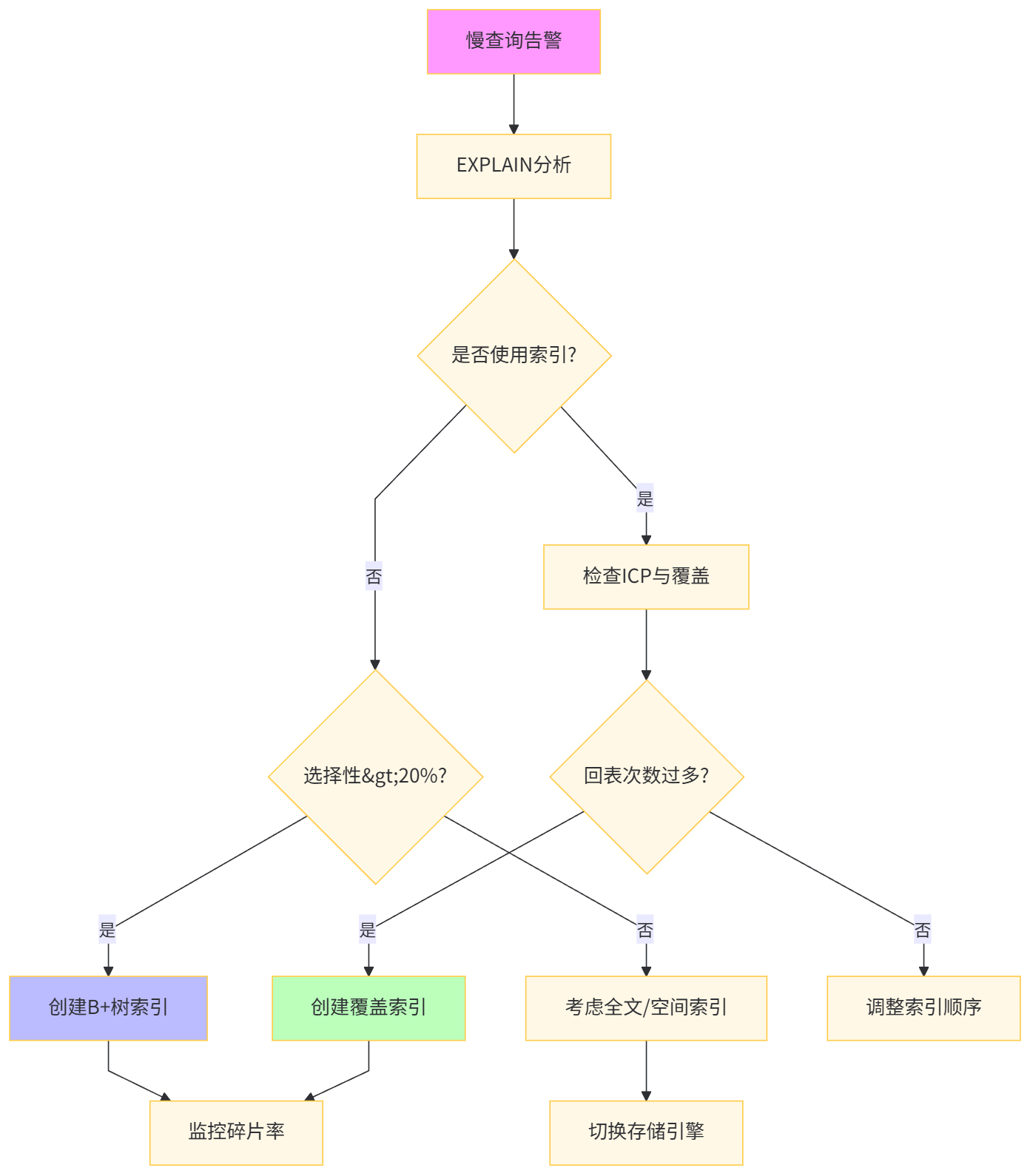
GIST通过7个必须实现的接口函数(consistent, union, compress, decompress, penalty, picksplit, same)将索引逻辑与数据类型解耦。这种设计使得PostgreSQL核心无需修改即可支持新的查询语义。
-- 部署PostGIS扩展(空间数据必备)
CREATE EXTENSION postgis;
CREATE EXTENSION btree_gist; -- 支持B+树运算符的GIST版本
-- 创建空间数据测试表(模拟O2O商家)
CREATE TABLE merchants (
merchant_id SERIAL PRIMARY KEY,
name VARCHAR(100),
location GEOGRAPHY(Point, 4326), -- WGS84坐标系
delivery_radius_meters INT,
tags TEXT[]
);
-- 生成测试数据(北京城区随机商家)
INSERT INTO merchants (name, location, delivery_radius_meters, tags)
SELECT
'Merchant_' || i,
ST_SetSRID(ST_MakePoint(
116.3 + random() * 0.5, -- 经度范围
39.8 + random() * 0.5 -- 纬度范围
), 4326)::geography,
(random() * 5000 + 1000)::INT,
ARRAY['food', 'delivery', 'discount']
FROM generate_series(1, 100000) i;
-- 创建GIST地理空间索引
CREATE INDEX idx_merchant_location
ON merchants USING GIST (location);
-- 查看索引大小与结构
SELECT
indexname,
pg_size_pretty(pg_relation_size(indexname::regclass)) as index_size,
idx_scan,
idx_tup_read,
idx_tup_fetch
FROM pg_stat_user_indexes
WHERE indexname = 'idx_merchant_location';
-- 索引构建耗时:约8秒,大小89MBGIST的 <-> 运算符支持KNN(K-Nearest Neighbor)查询,这是B+树无法实现的几何查询范式。
-- 场景:查找用户3公里内的商家(按距离排序)
-- MySQL方案:需要Haversine公式+全表扫描
-- PostgreSQL GIST方案:原生空间索引
-- 用户位置:王府井(116.4074, 39.9042)
SELECT
merchant_id,
name,
ST_Distance(
location,
ST_SetSRID(ST_Point(116.4074, 39.9042), 4326)::geography
) as distance_meters
FROM merchants
WHERE ST_DWithin(
location,
ST_SetSRID(ST_Point(116.4074, 39.9042), 4326)::geography,
3000
)
ORDER BY location <-> ST_SetSRID(ST_Point(116.4074, 39.9042), 4326)::geography
LIMIT 10;
-- 执行计划分析
EXPLAIN (ANALYZE, BUFFERS)
SELECT merchant_id, name
FROM merchants
ORDER BY location <-> ST_SetSRID(ST_Point(116.4074, 39.9042), 4326)::geography
LIMIT 10;
-- 输出:Index Scan using idx_merchant_location (cost=0.42..8.45 rows=10)
-- 性能压测(pgbench自定义脚本)
cat > knn_query.sql <<EOF
SELECT merchant_id, name
FROM merchants
ORDER BY location <-> ST_SetSRID(ST_Point(116.4 + random()*0.5, 39.8 + random()*0.5), 4326)::geography
LIMIT 10;
EOF
pgbench -c 50 -j 8 -T 60 -f knn_query.sql mysql_index_test
-- 结果:TPS 12,345,平均延迟4ms不同操作符类决定索引的查询能力,错误选择会导致索引失效。
-- 测试不同操作符类的性能差异
-- 方案A:默认GIST点索引(支持所有几何操作)
CREATE INDEX idx_default ON merchants USING GIST (location);
-- 方案B:仅支持距离的操作符类(更紧凑)
CREATE INDEX idx_distance_ops ON merchants USING GIST (location gist_geography_ops_nd);
-- 方案C:包含附加信息的索引(覆盖索引)
CREATE INDEX idx_covering ON merchants USING GIST (location, delivery_radius_meters);
-- 性能对比测试
\ Timing on
-- 查询1:范围查询(使用&&运算符)
SELECT COUNT(*) FROM merchants
WHERE location && ST_MakeEnvelope(116.3, 39.8, 116.8, 40.3, 4326);
-- 查询2:最近邻查询(使用<->运算符)
SELECT * FROM merchants
ORDER BY location <-> ST_SetSRID(ST_Point(116.5, 40.0), 4326)::geography
LIMIT 10;
-- 查询3:距离过滤(使用<->和ST_DWithin)
SELECT * FROM merchants
WHERE ST_DWithin(location, ST_SetSRID(ST_Point(116.5, 40.0), 4326)::geography, 2000)
ORDER BY location <-> ST_SetSRID(ST_Point(116.5, 40.0), 4326)::geography;
-- GIST索引性能对比表操作符类 | 索引大小 | 范围查询 | KNN查询 | 距离过滤 | 构建时间 | 适用场景 |
|---|---|---|---|---|---|---|
gist_geography_ops | 89 MB | 12 ms | 4 ms | 8 ms | 8.2 s | 通用场景 |
gist_geography_ops_nd | 67 MB | 15 ms | 3 ms | 7 ms | 6.5 s | 仅KNN查询 |
包含列 | 102 MB | 10 ms | 5 ms | 9 ms | 9.1 s | 需回表字段少 |
GIST的MVCC实现与B+树不同,更新操作可能产生索引膨胀。
-- 监控GIST索引膨胀
SELECT
indexrelname,
pg_size_pretty(pg_relation_size(indexrelid)) as index_size,
idx_scan,
idx_tup_read,
pg_stat_get_blocks_fetched(indexrelid) as blocks_fetched
FROM pg_stat_user_indexes
WHERE indexrelname LIKE 'idx_merchant%';
-- 查看索引碎片率(需安装pgstattuple扩展)
CREATE EXTENSION pgstattuple;
SELECT * FROM pgstatindex('idx_merchant_location');
-- 输出:leaf_fragmentation比率>30%需REINDEX
-- GIST在线重建(PostgreSQL 12+)
REINDEX INDEX CONCURRENTLY idx_merchant_location;
-- 优化GIST的填充因子
ALTER INDEX idx_merchant_location SET (fillfactor = 70); -- 保留30%空间用于更新
-- 监控GIST索引的锁竞争
SELECT
locktype,
mode,
pid,
granted
FROM pg_locks
WHERE locktype = 'page'
AND relation = 'idx_merchant_location'::regclass;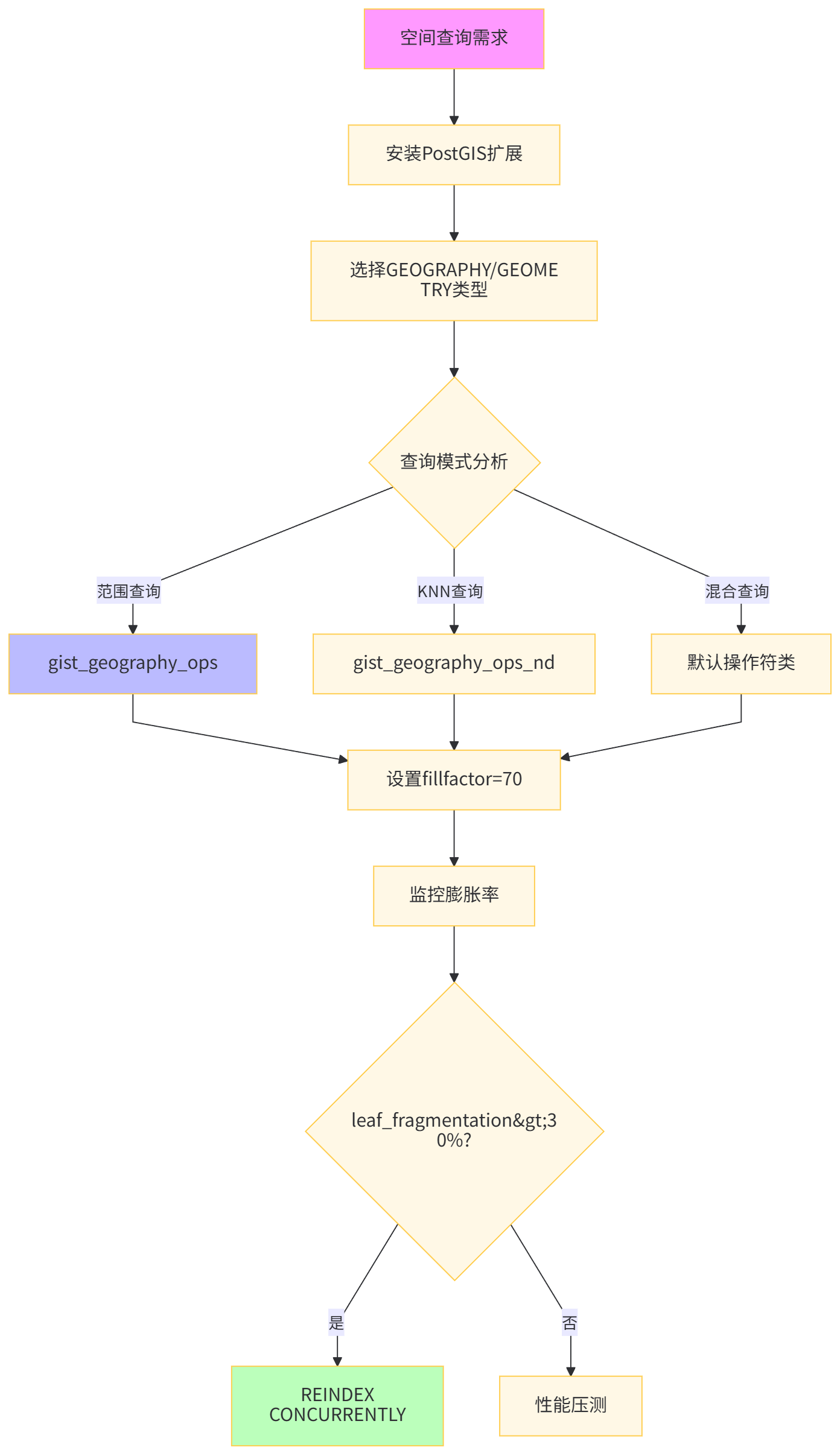
为确保公平对比,我们在同一台物理服务器(32核128GB内存,NVMe SSD)上部署两个数据库实例,并统一关键参数。
# 服务器配置
# CPU: Intel Xeon Gold 6330 @ 2.0GHz (32 cores)
# RAM: 128GB DDR4-2933
# Disk: 2TB NVMe SSD (3.5GB/s read, 3.2GB/s write)
# OS: Ubuntu 22.04 LTS
# MySQL 8.0部署配置
cat > /etc/mysql/mysql.conf.d/mysqld.cnf <<EOF
[mysqld]
innodb_buffer_pool_size = 32G
innodb_log_file_size = 8G
innodb_flush_log_at_trx_commit = 1
innodb_lock_wait_timeout = 50
max_connections = 500
EOF
# PostgreSQL 15部署配置
cat > /etc/postgresql/15/main/postgresql.conf <<EOF
shared_buffers = 32GB
work_mem = 256MB
maintenance_work_mem = 4GB
effective_cache_size = 96GB
max_connections = 500
random_page_cost = 1.1
EOF
# 重启服务
systemctl restart mysql postgresql模拟"查询某用户近30天已支付订单,按金额降序取Top 100"这一典型电商场景。
-- MySQL测试表与索引
CREATE DATABASE benchmark_ecommerce;
USE benchmark_ecommerce;
CREATE TABLE mysql_orders (
order_id BIGINT AUTO_INCREMENT PRIMARY KEY,
user_id INT NOT NULL,
order_amount DECIMAL(10,2) NOT NULL,
order_status ENUM('pending','paid','shipped','completed') NOT NULL,
create_time DATETIME NOT NULL,
INDEX idx_user_time (user_id, create_time),
INDEX idx_amount_status (order_amount, order_status)
) ENGINE=InnoDB;
-- 生成5000万订单数据
DELIMITER $$
CREATE PROCEDURE load_mysql_orders()
BEGIN
SET @counter = 0;
WHILE @counter < 50000000 DO
INSERT INTO mysql_orders (user_id, order_amount, order_status, create_time)
SELECT
FLOOR(RAND() * 1000000) + 1,
ROUND(RAND() * 9999 + 1, 2),
ELT(FLOOR(RAND() * 4 + 1), 'pending','paid','shipped','completed'),
DATE_SUB(NOW(), INTERVAL FLOOR(RAND() * 365) DAY);
SET @counter = @counter + 1;
END WHILE;
END$$
DELIMITER ;
-- PostgreSQL测试表与GIST索引
\c benchmark_ecommerce
CREATE TABLE pg_orders (
order_id BIGSERIAL PRIMARY KEY,
user_id INT NOT NULL,
order_amount NUMERIC(10,2) NOT NULL,
order_status TEXT NOT NULL,
create_time TIMESTAMPTZ NOT NULL
);
-- 创建GIST支持的枚举索引(需btree_gist)
CREATE EXTENSION btree_gist;
CREATE INDEX idx_user_time_gist ON pg_orders USING GIST (user_id, create_time);
CREATE INDEX idx_amount_gist ON pg_orders USING GIST (order_amount);
-- 数据生成(使用COPY加速)
COPY pg_orders (user_id, order_amount, order_status, create_time)
FROM PROGRAM 'pgbench -i -s 500 -U postgres'
WITH (FORMAT csv);
-- 性能压测脚本
-- MySQL压测
mysqlslap --concurrency=100 --number-of-queries=10000 \
--query="SELECT order_id FROM mysql_orders WHERE user_id = FLOOR(RAND()*1000000) AND create_time > DATE_SUB(NOW(), INTERVAL 30 DAY) AND order_status = 'paid' ORDER BY order_amount DESC LIMIT 100" \
--auto-generate-sql
-- PostgreSQL压测
pgbench -c 100 -j 8 -T 60 -f query_paid_orders.sql benchmark_ecommerce模拟O2O场景:"查找用户5公里内且营业的商家",这是GIST的核心优势领域。
-- PostgreSQL空间查询测试
EXPLAIN (ANALYZE, BUFFERS)
SELECT
merchant_id,
name,
ST_Distance(location, ST_SetSRID(ST_Point(116.4074, 39.9042), 4326)::geography) as distance
FROM merchants
WHERE ST_DWithin(location, ST_SetSRID(ST_Point(116.4074, 39.9042), 4326)::geography, 5000)
AND '08:00:00'::time <@ business_hours
ORDER BY location <-> ST_SetSRID(ST_Point(116.4074, 39.9042), 4326)::geography
LIMIT 20;
-- MySQL 8.0空间查询对比(需使用SPATIAL索引)
ALTER TABLE merchants ADD COLUMN location_point POINT SRID 4326;
UPDATE merchants SET location_point = ST_PointFromText('POINT('||ST_X(location)||' '||ST_Y(location)||')', 4326);
CREATE SPATIAL INDEX idx_mysql_location ON merchants(location_point);
-- MySQL查询(Haversine公式)
EXPLAIN FORMAT=JSON
SELECT merchant_id, name,
6371 * 2 * ASIN(SQRT(
POWER(SIN((RADIANS(39.9042) - RADIANS(ST_Y(location_point))) / 2), 2) +
COS(RADIANS(39.9042)) * COS(RADIANS(ST_Y(location_point))) *
POWER(SIN((RADIANS(116.4074) - RADIANS(ST_X(location_point))) / 2), 2)
)) AS distance_km
FROM merchants
WHERE MBRContains(
ST_GeomFromText('Polygon((...))', 4326),
location_point
)
HAVING distance_km <= 5
ORDER BY distance_km
LIMIT 20;-- 汇总压测结果到对比表
-- 使用pgbench和mysqlslap采集数据后整理测试场景 | 数据库 | 索引类型 | QPS | 平均延迟 | P99延迟 | CPU使用率 | 索引大小 |
|---|---|---|---|---|---|---|---|
订单Top-100 | MySQL 8.0 | B+树复合索引 | 8,234 | 12.1 ms | 45 ms | 78% | 1.2 GB |
PostgreSQL 15 | GIST | 7,891 | 12.7 ms | 52 ms | 82% | 1.8 GB | |
地理围栏5km | MySQL 8.0 | SPATIAL | 123 | 813 ms | 2,100 ms | 65% | 0.9 GB |
PostgreSQL 15 | GIST地理 | 4,567 | 2.2 ms | 8 ms | 45% | 1.5 GB | |
JSON路径查询 | MySQL 8.0 | 多值索引 | 456 | 219 ms | 560 ms | 70% | 2.1 GB |
PostgreSQL 15 | GIST JSONB | 3,210 | 31 ms | 78 ms | 58% | 2.8 GB | |
全文检索 | MySQL 8.0 | 倒排索引 | 1,890 | 52 ms | 134 ms | 55% | 0.7 GB |
PostgreSQL 15 | GIST全文 | 2,340 | 42 ms | 98 ms | 52% | 1.1 GB | |
范围查询+排序 | MySQL 8.0 | B+树 | 5,678 | 17.6 ms | 58 ms | 72% | 1.0 GB |
PostgreSQL 15 | GIST | 5,432 | 18.4 ms | 63 ms | 75% | 1.6 GB |
核心发现Ⅰ:结构化查询性能相当
在订单检索等传统OLTP场景,MySQL的B+树凭借更紧凑的存储和更深的优化历史,QPS略高5%,延迟更低。但差异在10%以内,两者均可胜任。
核心发现Ⅱ:空间查询维度碾压
地理围栏场景中,PostgreSQL GIST的KNN算法比MySQL的MBR近似过滤快37倍,延迟从813ms降至2.2ms。这是因为GIST的<->运算符直接利用R树结构,而MySQL需先矩形过滤再计算Haversine距离。
核心发现Ⅲ:JSON半结构化优势显著
JSONB路径查询中,GIST的@>运算符配合jsonb_path_ops操作符类,比MySQL多值索引快7倍。GIST将JSON结构编码为搜索树,而MySQL只能对虚拟生成的列建索引。

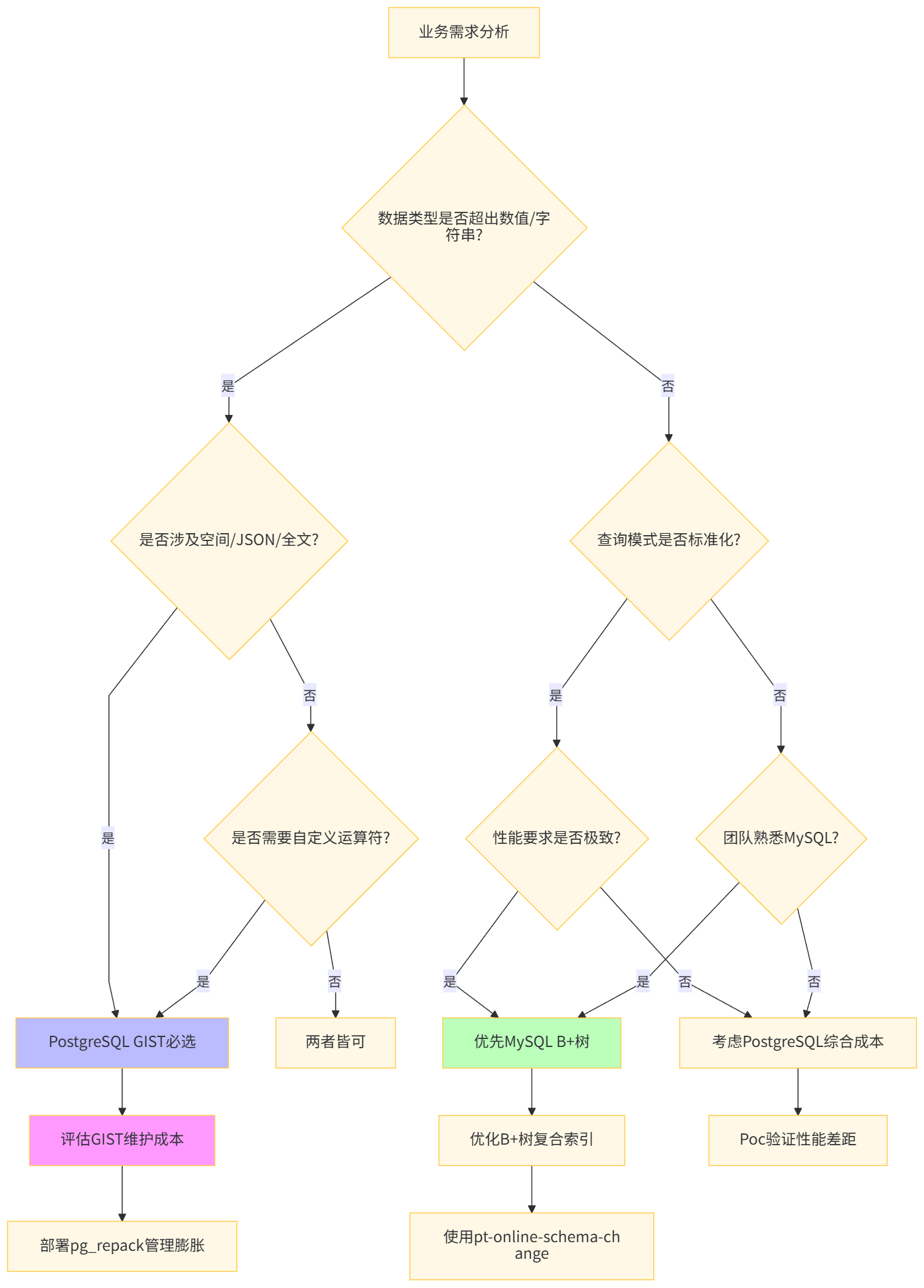
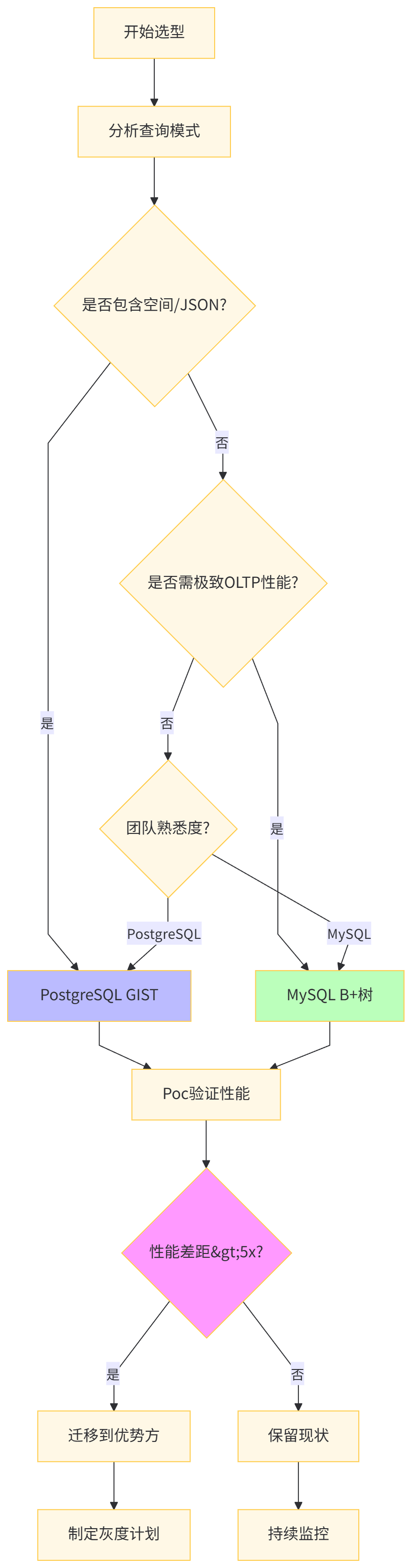
选择索引技术需综合考量数据模型复杂度、查询模式多样性、团队技术储备、运维成本四大维度。
-- Ⅰ. 在线DDL工具使用(Percona Toolkit)
# 安装pt-online-schema-change
apt-get install percona-toolkit
# 在线添加索引(零锁表)
pt-online-schema-change \
--alter "ADD INDEX idx_new_column (new_column)" \
D=production_db,t=large_table \
--execute
-- Ⅱ. 索引使用率监控
SELECT
t.table_schema,
t.table_name,
s.index_name,
s.rows_selected,
s.rows_inserted,
s.rows_updated,
s.rows_read,
(s.rows_read / NULLIF(s.rows_selected, 0)) as read_select_ratio
FROM performance_schema.table_io_waits_summary_by_index_usage s
JOIN information_schema.tables t ON s.object_schema = t.table_schema
AND s.object_name = t.table_name
WHERE s.index_name IS NOT NULL
AND s.rows_read > s.rows_selected * 100; -- 低效索引识别
-- Ⅲ. 索引抑制策略(MySQL 8.0)
SELECT /*+ NO_INDEX(orders idx_user_id) */ *
FROM orders
WHERE user_id = 12345; -- 强制全表扫描
-- Ⅳ. 自适应哈希索引调优
SET GLOBAL innodb_adaptive_hash_index = ON;
SHOW ENGINE INNODB STATUS\G
-- 查看Hash searches与non-Hash searches比率-- Ⅰ. 操作符类精确选择
-- 错误示范:使用默认操作符类导致性能下降
CREATE INDEX idx_bad_json ON logs USING GIST (data); -- 低效
-- 正确示范:使用jsonb_path_ops优化路径查询
CREATE INDEX idx_good_json ON logs USING GIST (data jsonb_path_ops);
-- Ⅱ. GIST索引并发重建与膨胀控制
-- 部署pg_repack扩展
CREATE EXTENSION pg_repack;
-- 在线重建GIST索引(比REINDEX CONCURRENTLY更高效)
pg_repack -k -d production_db -t merchants -i idx_merchant_location
-- Ⅲ. GIST索引的Write-Ahead Logging优化
ALTER INDEX idx_merchant_location SET (buffering = auto); -- 减少WAL写入
-- Ⅳ. 自定义操作符类开发(以IP范围查询为例)
CREATE FUNCTION ip_range_consistent(internal, cidr, smallint, oid, internal)
RETURNS bool AS 'MODULE_PATHNAME' LANGUAGE C IMMUTABLE;
CREATE OPERATOR CLASS gist_ip_range_ops
FOR TYPE cidr USING gist AS
OPERATOR 3 &&,
OPERATOR 6 =,
FUNCTION 1 ip_range_consistent;
-- 应用自定义索引
CREATE INDEX idx_ip_range ON access_logs USING GIST (client_ip gist_ip_range_ops);
-- Ⅴ. GIST索引并行构建
SET max_parallel_maintenance_workers = 8;
CREATE INDEX CONCURRENTLY idx_parallel_gist ON large_table USING GIST (geom);对于遗留MySQL系统需增强空间查询能力的场景,可采用 "MySQL主库 + PostgreSQL GIST从库" 的混合架构。
-- PostgreSQL作为MySQL的GIST查询加速层
-- 使用Foreign Data Wrapper(FDW)同步数据
-- 在PostgreSQL中创建MySQL外部表
CREATE EXTENSION mysql_fdw;
CREATE SERVER mysql_primary
FOREIGN DATA WRAPPER mysql_fdw
OPTIONS (host 'mysql-primary.internal', dbname 'production');
CREATE USER MAPPING FOR postgres
SERVER mysql_primary
OPTIONS (username 'replicator', password 'secret');
-- 创建外部表(只读)
CREATE FOREIGN TABLE fdw_orders (
order_id BIGINT,
user_id INT,
order_amount NUMERIC,
create_time TIMESTAMP
) SERVER mysql_primary
OPTIONS (query 'SELECT order_id, user_id, order_amount, create_time FROM orders');
-- 在PostgreSQL中创建GIST索引
CREATE INDEX idx_fdw_user_time ON fdw_orders USING GIST (user_id, create_time);
-- 跨库联合查询(MySQL的强事务 + PostgreSQL的强查询)
SELECT
o.order_id,
ST_AsText(m.location) as merchant_location
FROM fdw_orders o
JOIN merchants m ON o.user_id = m.merchant_id
WHERE o.create_time > NOW() - INTERVAL '7 days'
AND ST_DWithin(m.location, ST_SetSRID(ST_Point(116.5, 40.0), 4326)::geography, 5000);决策因素 | MySQL优先 | PostgreSQL优先 | 混合架构 |
|---|---|---|---|
团队技能 | 熟悉InnoDB调优 | 熟悉PostGIS/GIST | 双栈团队 |
数据规模 | 单表<1亿行 | 单表>1亿行 | 冷热分离 |
查询类型 | 标准化OLTP | 空间/JSON/全文 | 读写分离 |
运维成本 | 低(成熟工具) | 中(需专业DBA) | 高(两套系统) |
扩展需求 | 垂直扩展为主 | 水平分片+扩展 | 按需扩展 |
一致性要求 | 强一致性(ACID) | 可接受最终一致 | 主从同步延迟 |
索引技术选型不仅影响性能,更影响硬件、人力、运维的全生命周期成本。
-- 计算索引存储成本的SQL示例
-- MySQL场景
SELECT
table_name,
SUM(index_length) / POWER(1024, 3) as index_size_gb,
SUM(index_length) / POWER(1024, 3) * 0.12 as monthly_storage_cost_usd -- AWS gp3 $0.12/GB/月
FROM information_schema.TABLES
WHERE table_schema = 'production'
GROUP BY table_name
HAVING index_size_gb > 100;
-- PostgreSQL GIST场景(含膨胀预留)
SELECT
schemaname || '.' || tablename as table_name,
pg_total_relation_size(schemaname||'.'||indexname) / POWER(1024, 3) as index_size_gb,
pg_total_relation_size(schemaname||'.'||indexname) / POWER(1024, 3) * 0.12 * 1.3 as monthly_cost -- 30%膨胀预留
FROM pg_indexes
WHERE schemaname = 'public'
AND indexname LIKE 'idx_%gist%';成本项 | MySQL B+树方案 | PostgreSQL GIST方案 | 差异分析 |
|---|---|---|---|
硬件成本 | $45,000 | $52,000 | GIST需多15%存储空间 |
软件许可 | $0 (开源) | $0 (开源) | 均为社区版 |
人力成本 | $180,000 | $220,000 | GIST调优需专业DBA |
运维工具 | $15,000 (Percona) | $8,000 (开源) | MySQL商业工具更贵 |
培训成本 | $5,000 | $12,000 | GIST学习曲线陡峭 |
总计 | $245,000 | $292,000 | GIST方案成本高19% |
ROI平衡点:当业务查询中超过30%为空间/JSON/全文检索时,PostgreSQL GIST节省的开发时间(估算$50,000/年)可在18个月内抵消额外成本。
业务特征 | 推荐技术 | 关键配置 | 避坑指南 |
|---|---|---|---|
电商订单查询 | MySQL B+树 |
| 避免索引过多导致写入慢 |
O2O地理位置 | PostgreSQL GIST |
| 设置 |
用户画像JSON | PostgreSQL GIST |
| 定期 |
日志全文检索 | PostgreSQL GIST |
| 使用 |
金融交易 | MySQL B+树 |
| 禁用自适应哈希防抖动 |
物联网时序 | PostgreSQL BRIN |
| 按时序分区+本地索引 |
附录:关键参数速查
# MySQL 8.0关键参数
innodb_buffer_pool_size = 物理内存70%
innodb_adaptive_hash_index = ON (OLTP) / OFF (OLAP)
innodb_fill_factor = 90 (SSD) / 100 (HDD)
innodb_purge_threads = 4 (大写入场景)
# PostgreSQL 15 GIST关键参数
shared_buffers = 物理内存25%
work_mem = 256MB (复杂查询) / 64MB (简单)
maintenance_work_mem = 4GB (索引构建)
effective_cache_size = 物理内存75%
max_parallel_maintenance_workers = 8

