

产品中心
本指南帮你把一个本地 RAG(Retrieval-Augmented Generation)示例工程整理成可直接构建与运行的 Git 项目,并提供在 cnb.cool(CNB)上自动化构建的 .cnb.yml 示例。目标是:最小改造、最快验证、可选接入 OpenAI。
CNB地址:https://cnb.cool
RAG-QA 项目:https://cnb.cool/istioagentnj/cnb
2025 第二期 Docker 训练营地址:https://opencamp.cn/Docker/camp/202502/register?code=dxJSEQUgrBdWs
2025 第二期 Docker 训练营是由 OpenCamp 社区 联合 腾讯云 CNB(Cloud Native Build) 共同举办的云原生技术实战项目。本期训练营采用“直播教学 + 闯关实战 + 项目实习”的模式,依托腾讯云 CNB 平台,为学员提供开箱即用的云端开发环境。
这里直接创建以下这些文件,然后将下面的代码放在相应对的文件中。
rag-qa-cnb/
├── app/
│ ├── __init__.py
│ ├── main.py ✅ 接口入口
│ ├── retriever.py ✅ 向量索引 & 检索
│ ├── models.py ✅ Pydantic 数据模型
│ └── utils.py ✅ 工具函数(Embedding / LLM)
├── requirements.txt
├── Dockerfile
fastapi==0.110.0
uvicorn[standard]==0.29.0
sentence-transformers==2.2.2
huggingface_hub<0.20.0
faiss-cpu==1.7.4
numpy<2.0
openai==0.28.1Dockerfile(用于在 CNB 上基于 Dockerfile 构建)
# 基础镜像
FROM python:3.11-slim
ENV PYTHONDONTWRITEBYTECODE=1
ENV PYTHONUNBUFFERED=1
WORKDIR /app
# 先拷贝 requirements,利用缓存加速构建
COPY requirements.txt /app/requirements.txt
# 安装系统依赖与 Python 依赖
RUN apt-get update && apt-get install -y \
build-essential git curl ca-certificates libopenblas-dev \
&& pip install --upgrade pip \
&& pip install --no-cache-dir -r /app/requirements.txt \
&& apt-get remove -y build-essential git && apt-get autoremove -y \
&& rm -rf /var/lib/apt/lists/*
# 拷贝项目代码
COPY . /app
# 暴露端口
EXPOSE 8000
# 可用的启动命令(CNB 平台会使用它或你在 UI 指定 CMD)
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "8000"]app/models.py(数据模型)
from typing import List, Optional, Dict
from pydantic import BaseModel
class Document(BaseModel):
id: str
text: str
meta: Optional[Dict] = {}
class IngestRequest(BaseModel):
documents: List[Document]
class QueryRequest(BaseModel):
question: str
top_k: int = 3
use_openai: bool = False
class QueryResponse(BaseModel):
answer: str
contexts: List[str]
app/utils.py(Embedding + LLM 工具)
import os
from typing import List
from sentence_transformers import SentenceTransformer
try:
import openai
except ImportError:
openai = None
# 全局 embedding 模型(只加载一次)
_embedding_model = SentenceTransformer("sentence-transformers/all-MiniLM-L6-v2")
def embed_texts(texts: List[str]) -> List[List[float]]:
"""
将文本列表转为向量
"""
embeddings = _embedding_model.encode(texts, convert_to_numpy=True)
return embeddings.tolist()
def call_openai_llm(prompt: str) -> str:
"""
调用 OpenAI 生成回答
"""
api_key = os.getenv("OPENAI_API_KEY")
if not api_key or openai is None:
raise RuntimeError("OpenAI API 未配置")
openai.api_key = api_key
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "你是一个专业的知识问答助手。"},
{"role": "user", "content": prompt},
],
temperature=0.2,
)
return response.choices[0].message["content"].strip()
def simple_fallback_answer(question: str, contexts: List[str]) -> str:
"""
无 LLM 时的兜底回答(教学/调试用)
"""
if not contexts:
return "未找到相关知识。"
joined = "\n".join(contexts)
return f"根据已知资料,问题「{question}」的相关内容如下:\n{joined}"
app/retriever.py(FAISS 向量索引)
from typing import List, Tuple
import faiss
import numpy as np
from app.utils import embed_texts
class FaissRetriever:
def __init__(self, dim: int):
self.dim = dim
self.index = faiss.IndexFlatL2(dim)
self.texts: List[str] = []
def add_texts(self, texts: List[str]):
"""
向索引中添加文本
"""
vectors = embed_texts(texts)
vectors_np = np.array(vectors).astype("float32")
self.index.add(vectors_np)
self.texts.extend(texts)
def search(self, query: str, top_k: int = 3) -> List[str]:
"""
相似度搜索
"""
if self.index.ntotal == 0:
return []
query_vec = embed_texts([query])[0]
query_np = np.array([query_vec]).astype("float32")
distances, indices = self.index.search(query_np, top_k)
results = []
for idx in indices[0]:
if 0 <= idx < len(self.texts):
results.append(self.texts[idx])
return results
app/main.py(FastAPI 主入口)
from fastapi import FastAPI
from pydantic import BaseModel
from app.retriever import FaissRetriever
from app.utils import call_openai_llm
import traceback
app = FastAPI()
retriever = FaissRetriever()
class QueryRequest(BaseModel):
question: str
use_openai: bool = False
@app.get("/health")
def health():
return {"status": "ok"}
@app.post("/query")
def query(req: QueryRequest):
contexts = retriever.search(req.question)
prompt = (
"请基于以下内容回答问题。\n\n"
+ "\n".join(contexts)
+ f"\n\n问题:{req.question}"
)
# 默认兜底答案
answer = "(本次回答由本地 RAG 检索生成,未调用大模型)\n\n" + "\n".join(contexts)
if req.use_openai:
try:
answer = call_openai_llm(prompt)
except Exception as e:
print("⚠️ OpenAI 调用失败,已回退:")
traceback.print_exc()
return {
"question": req.question,
"answer": answer,
"contexts": contexts,
}接下来就是创建镜像运行容器
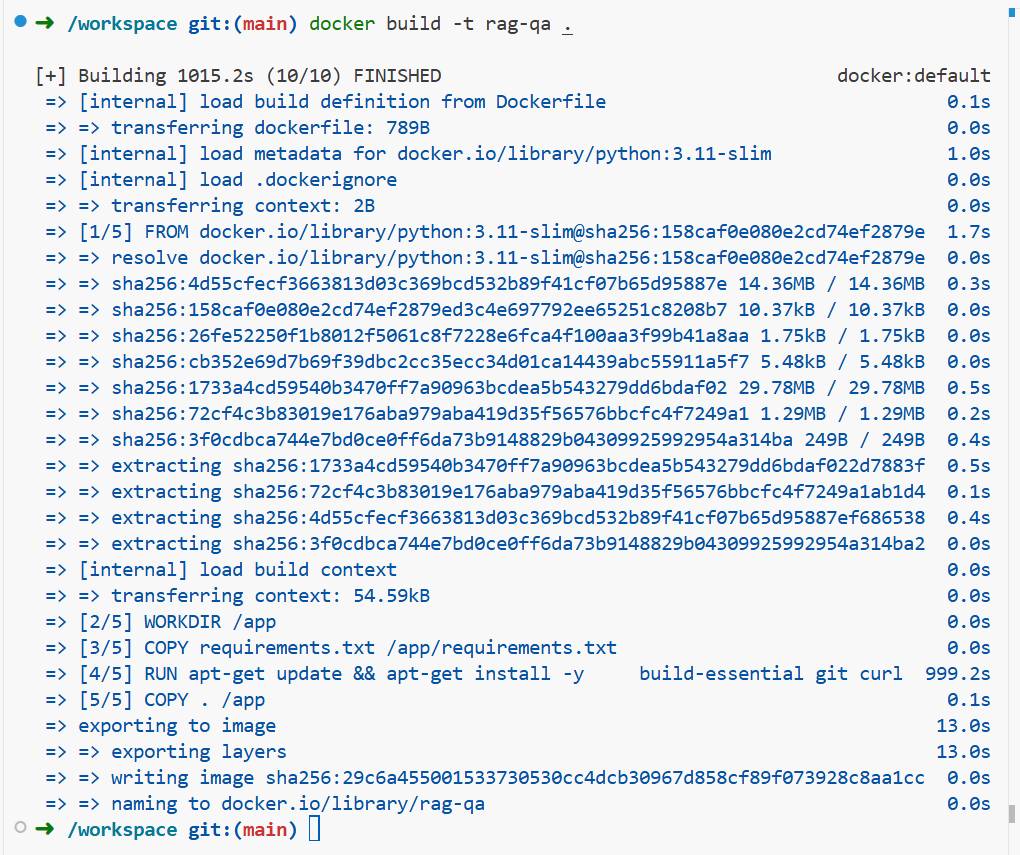
docker build -t rag-qa .如果成功,你会看到:
docker run -it --rm -p 8000:8000 rag-qa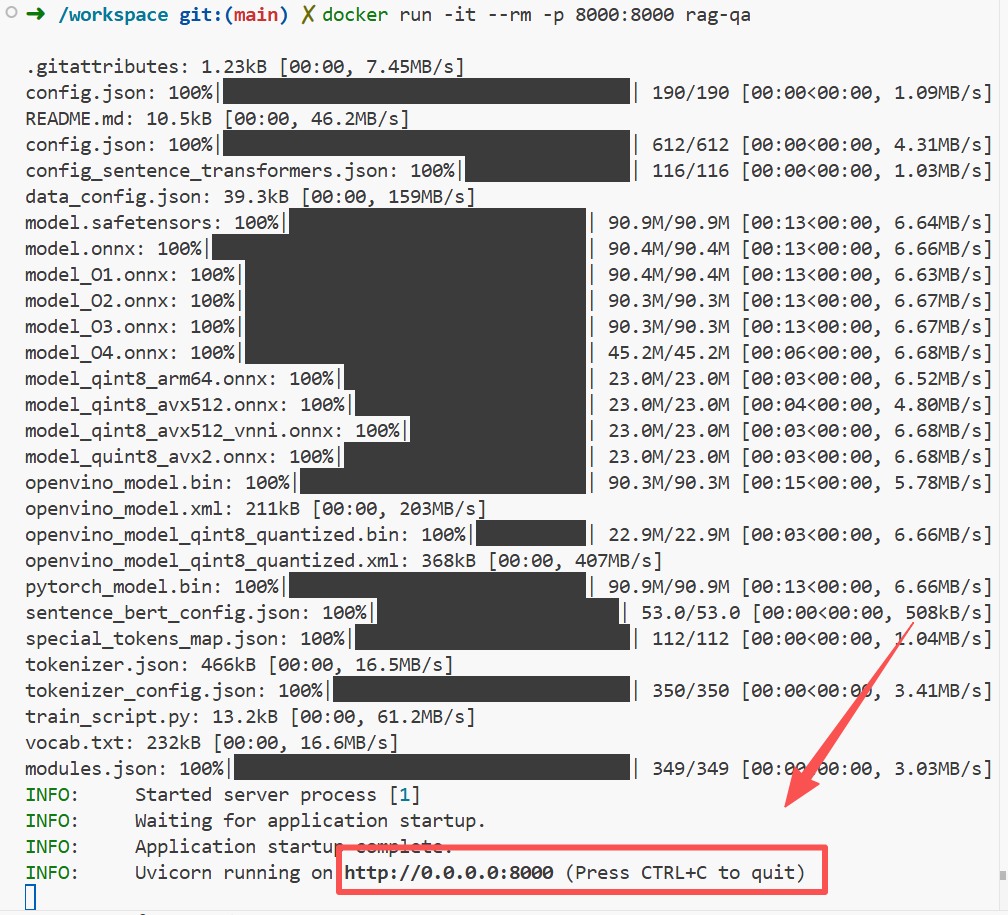
开新终端:
curl http://localhost:8000/health正确返回:

RAG = 先有知识,后能回答
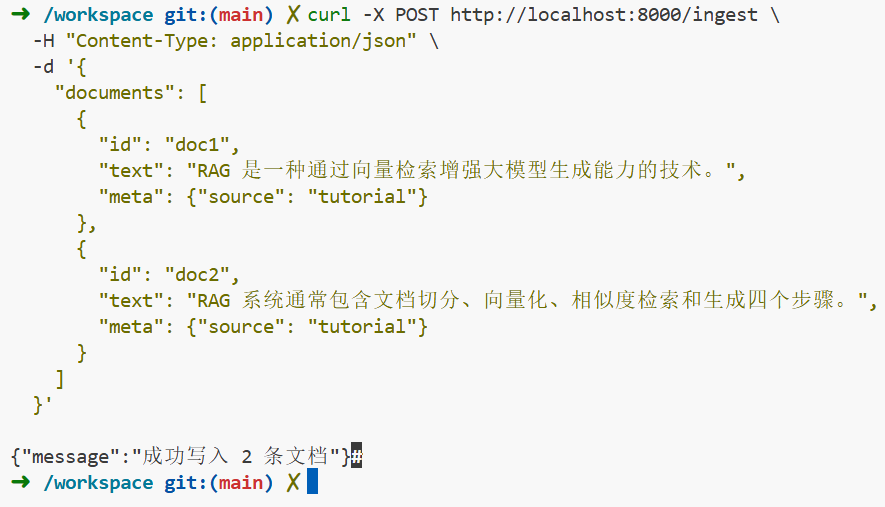
curl -X POST http://localhost:8000/ingest \
-H "Content-Type: application/json" \
-d '{
"documents": [
{
"id": "doc1",
"text": "RAG 是一种通过向量检索增强大模型生成能力的技术。",
"meta": {"source": "tutorial"}
},
{
"id": "doc2",
"text": "RAG 系统通常包含文档切分、向量化、相似度检索和生成四个步骤。",
"meta": {"source": "tutorial"}
}
]
}'
这一步说明:
Sentence-Transformers 正常工作
Embedding 生成成功
FAISS Index 已写入内存
注意:现在的向量是“内存态”的,重启容器会丢,这是正常的
我们先 不用 OpenAI,确保纯 RAG 检索链路是 OK 的。
curl -X POST http://localhost:8000/query \
-H "Content-Type: application/json" \
-d '{
"question": "RAG 系统一般包含哪些步骤?",
"top_k": 2,
"use_openai": false
}'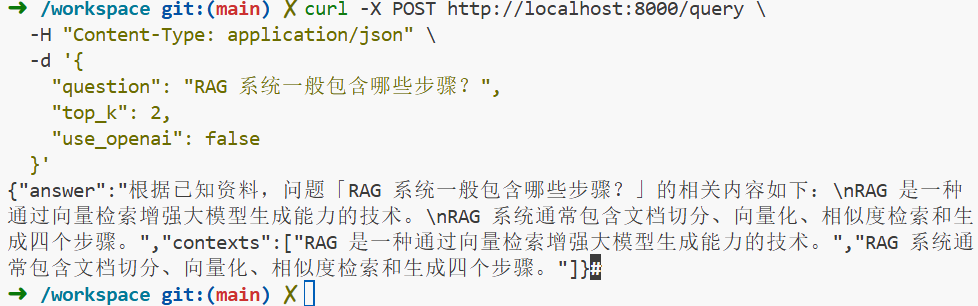
如果你看到 contexts 里是你刚刚 ingest 的内容 那么恭喜你:RAG 核心链路 100% 打通
这个部分放在评论区大家可以讨论讨论
docker run -it --rm \
-e OPENAI_API_KEY=sk-xxxx \
-p 8000:8000 \
rag-qa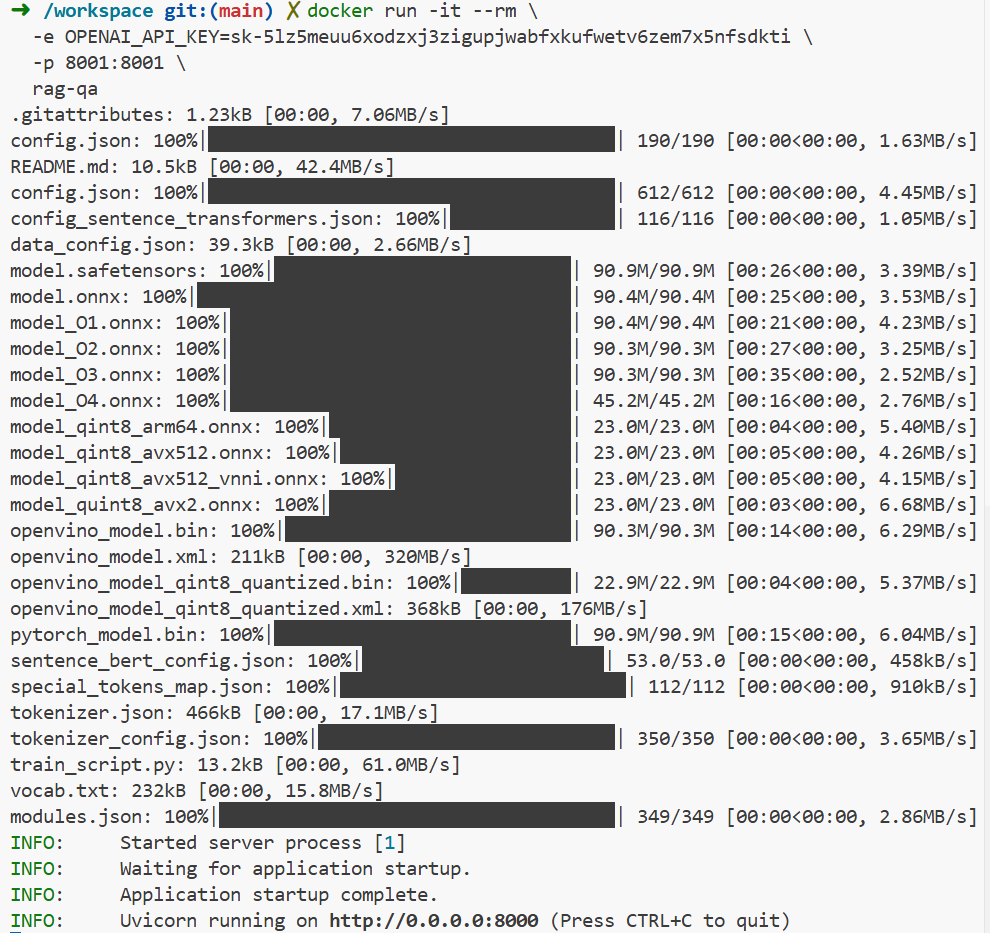
curl -X POST http://localhost:8000/query \
-H "Content-Type: application/json" \
-d '{
"question": "什么是 RAG?",
"use_openai": true
}'app/retriever.py(支持持久化)import numpy as np
import faiss
import os
import pickle
class FaissRetriever:
def __init__(self):
self.base_dir = "/app/data"
self.faiss_dir = os.path.join(self.base_dir, "faiss")
self.index_path = os.path.join(self.faiss_dir, "index.faiss")
self.texts_path = os.path.join(self.faiss_dir, "texts.pkl")
os.makedirs(self.faiss_dir, exist_ok=True)
self._load_or_build()
def _load_or_build(self):
if os.path.exists(self.index_path) and os.path.exists(self.texts_path):
print("✅ 加载已有 FAISS 索引")
self.index = faiss.read_index(self.index_path)
with open(self.texts_path, "rb") as f:
self.texts = pickle.load(f)
else:
print("⚠️ 未发现索引,开始首次构建")
self._build()
def _build(self):
from sentence_transformers import SentenceTransformer
self.embed_model = SentenceTransformer("sentence-transformers/all-MiniLM-L6-v2")
# 示例文档(你后面可以换成真实文档)
self.texts = [
"RAG 是 Retrieval Augmented Generation",
"RAG 结合了向量检索与大语言模型",
"Docker 用于容器化部署 AI 服务"
]
# ? 关键修复点在这里
embeddings = self.embed_model.encode(self.texts)
# ? 显式转 numpy + float32
embeddings = np.array(embeddings).astype("float32")
dim = embeddings.shape[1]
self.index = faiss.IndexFlatL2(dim)
self.index.add(embeddings)
# ? 一定要落盘
faiss.write_index(self.index, self.index_path)
with open(self.texts_path, "wb") as f:
pickle.dump(self.texts, f)
print("✅ FAISS 索引构建完成并已保存")
def search(self, query: str, top_k: int = 3):
query_vec = self.embed_model.encode([query])
query_vec = np.array(query_vec).astype("float32")
distances, indices = self.index.search(query_vec, top_k)
return [self.texts[i] for i in indices[0]]mkdir -p data/faiss
docker run -it --rm \
-p 8000:8000 \
-v $(pwd)/data:/app/data \
rag-qa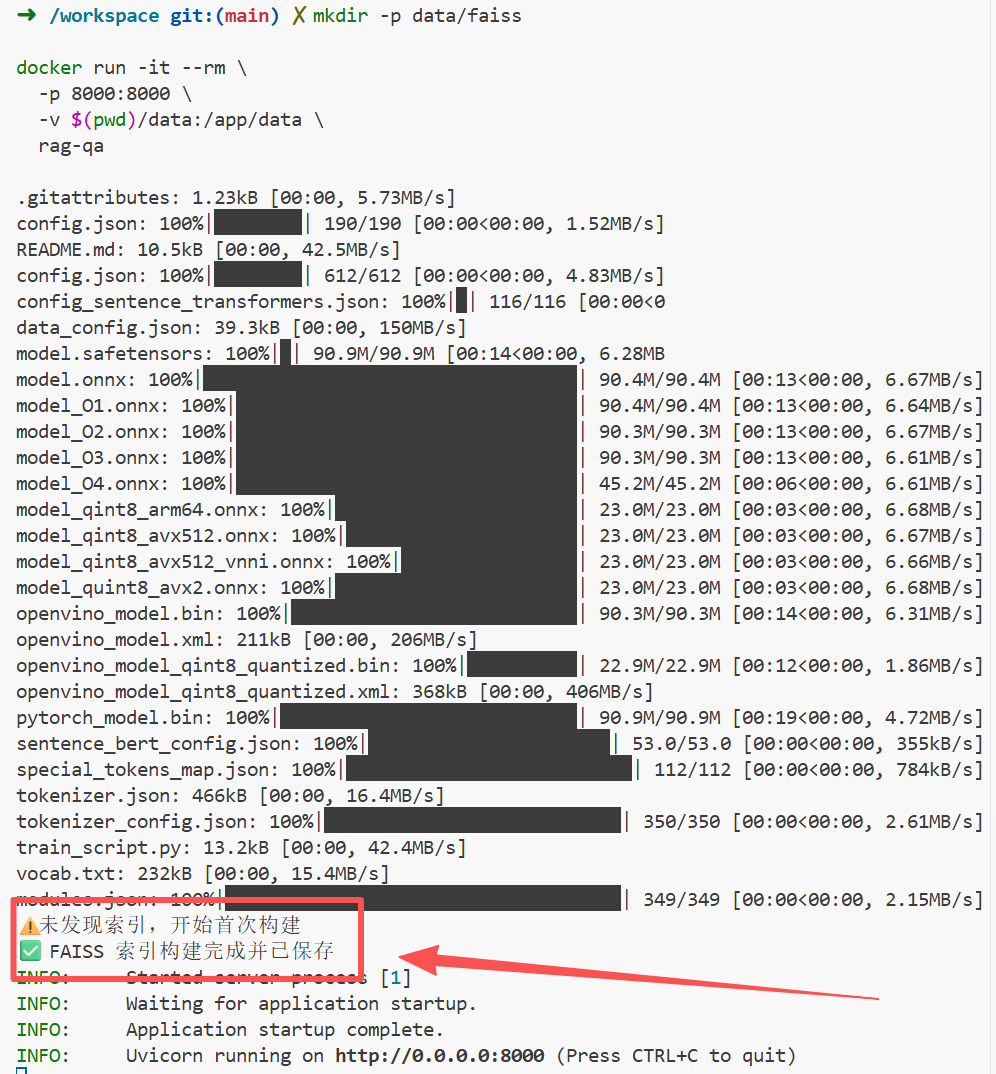
如果你不挂载 volume,容器一删索引就没了
这是你是否做对的“唯一标准”
并且宿主机必须有下面两个文件:

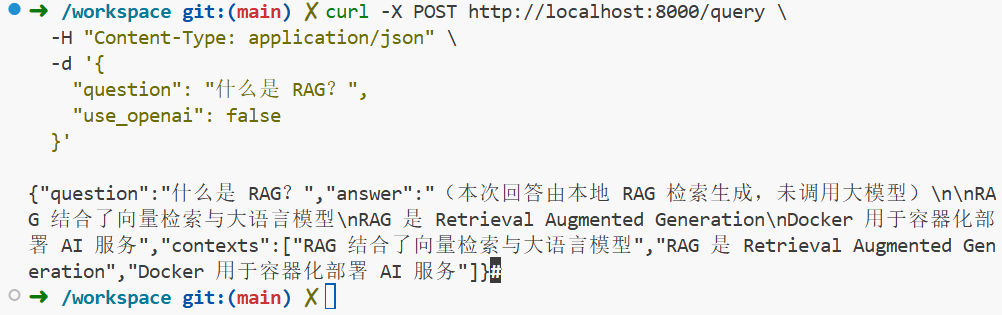
curl -X POST http://localhost:8000/query \
-H "Content-Type: application/json" \
-d '{
"question": "什么是 RAG?",
"use_openai": false
}'
随后我们在创建一个自动化的.cnb.yml文件,让他帮我们自动构建环境。
这个文件是什么?有什么用?解答:CNB 的“自动化剧本”
# .cnb.yml
$:
vscode:
- docker:
# 使用 CNB 官方默认开发镜像(已包含 code-server + docker cli)
image: cnbcool/default-dev-env:latest
# 声明需要的服务
services:
- vscode
- docker
# 开发环境启动后自动执行的步骤
stages:
# 1️⃣ 查看当前工作目录(确认代码已挂载)
- name: show-workspace
script: |
echo "==== Workspace Files ===="
pwd
ls -al
# 2️⃣ 构建 RAG Docker 镜像
- name: build-rag-image
script: |
echo "==== Build RAG Docker Image ===="
docker build -t rag-qa .
# 3️⃣ 启动容器(后台运行)
- name: run-rag-container
script: |
echo "==== Run RAG Container ===="
docker rm -f rag-qa-container || true
docker run -d \
--name rag-qa-container \
-p 8000:8000 \
rag-qa
# 4️⃣ 等待服务启动并做健康检查
- name: health-check
script: |
echo "==== Health Check ===="
sleep 5
curl http://localhost:8000/health本文详细展示了如何从零开始搭建一个基于 FastAPI + FAISS + Sentence-Transformers 的 RAG 问答系统,涵盖:
本地准备与先决条件:确保 Git、Docker 和可选 OpenAI API 可用。
项目结构与关键文件:保持清晰目录与模块划分,便于扩展与维护。
本地测试流程:构建 Docker 镜像、运行容器、健康检查、向系统喂知识、发起问答。
可选接入 OpenAI:在 RAG 检索基础上增强自然语言回答能力。
向量持久化方案:FAISS 索引落盘与宿主机挂载示例,保证容器重启不丢失数据。
自动化构建示例:CNB .cnb.yml 提供自动化构建、启动、健康检查流程。
通过本文,你可以快速构建一个可用、可扩展、可自动化部署的 RAG 系统,且保留灵活的 LLM 接入选项,适合研发、教学和轻量生产环境。


