

产品中心
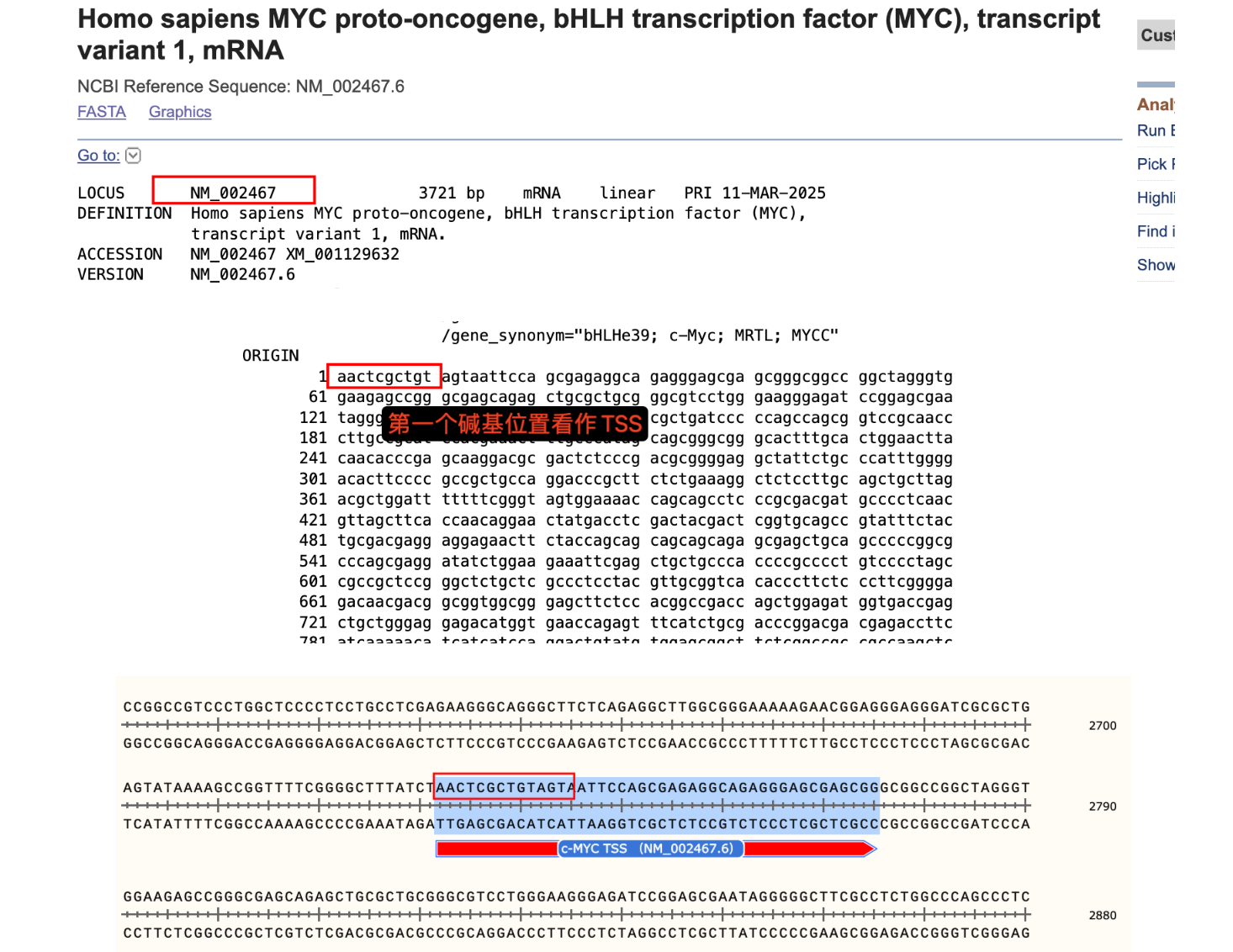
记录下从NCBI数据库中获取某基因序列和转录起始位点,以MYC基因为例
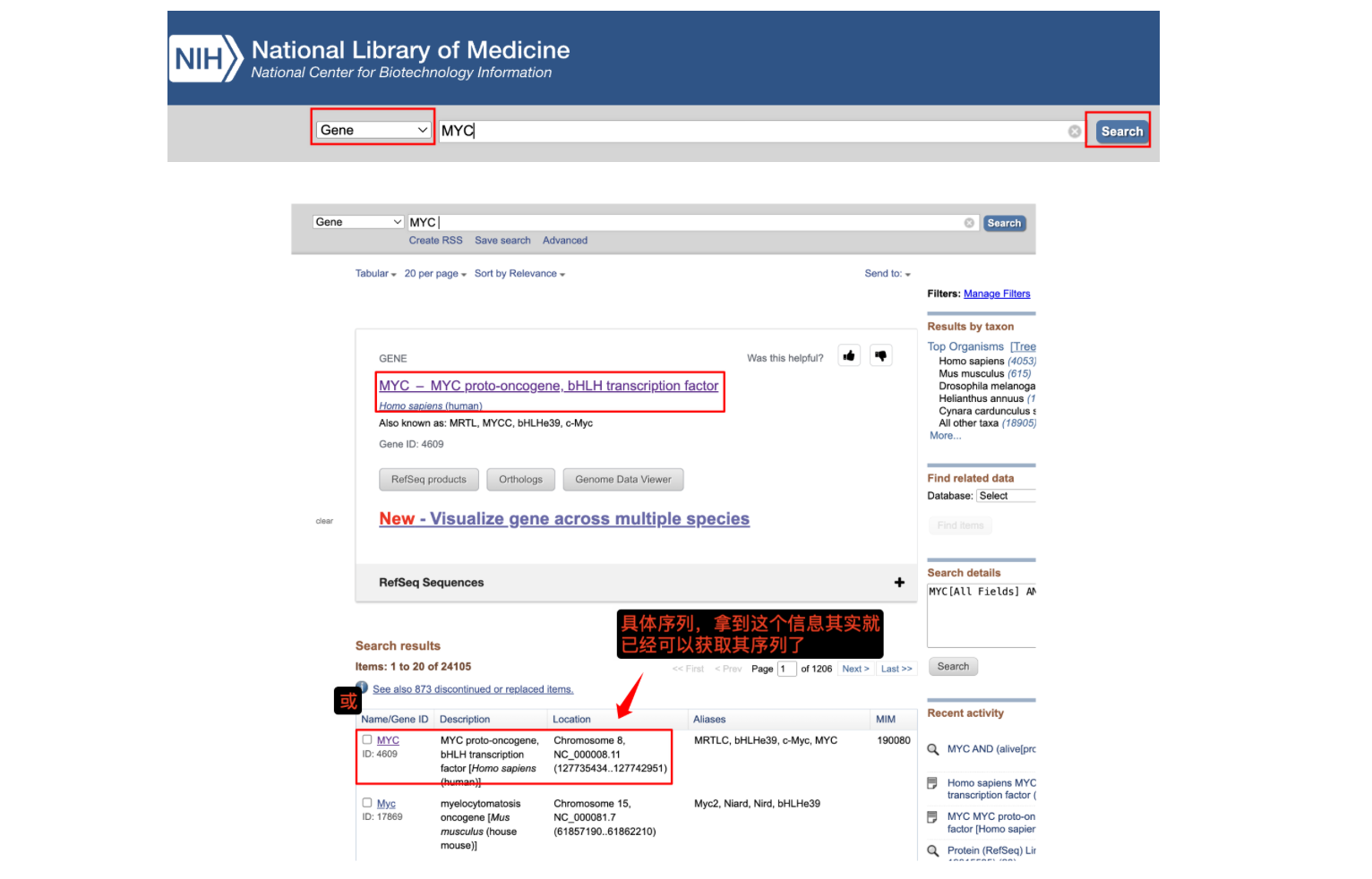
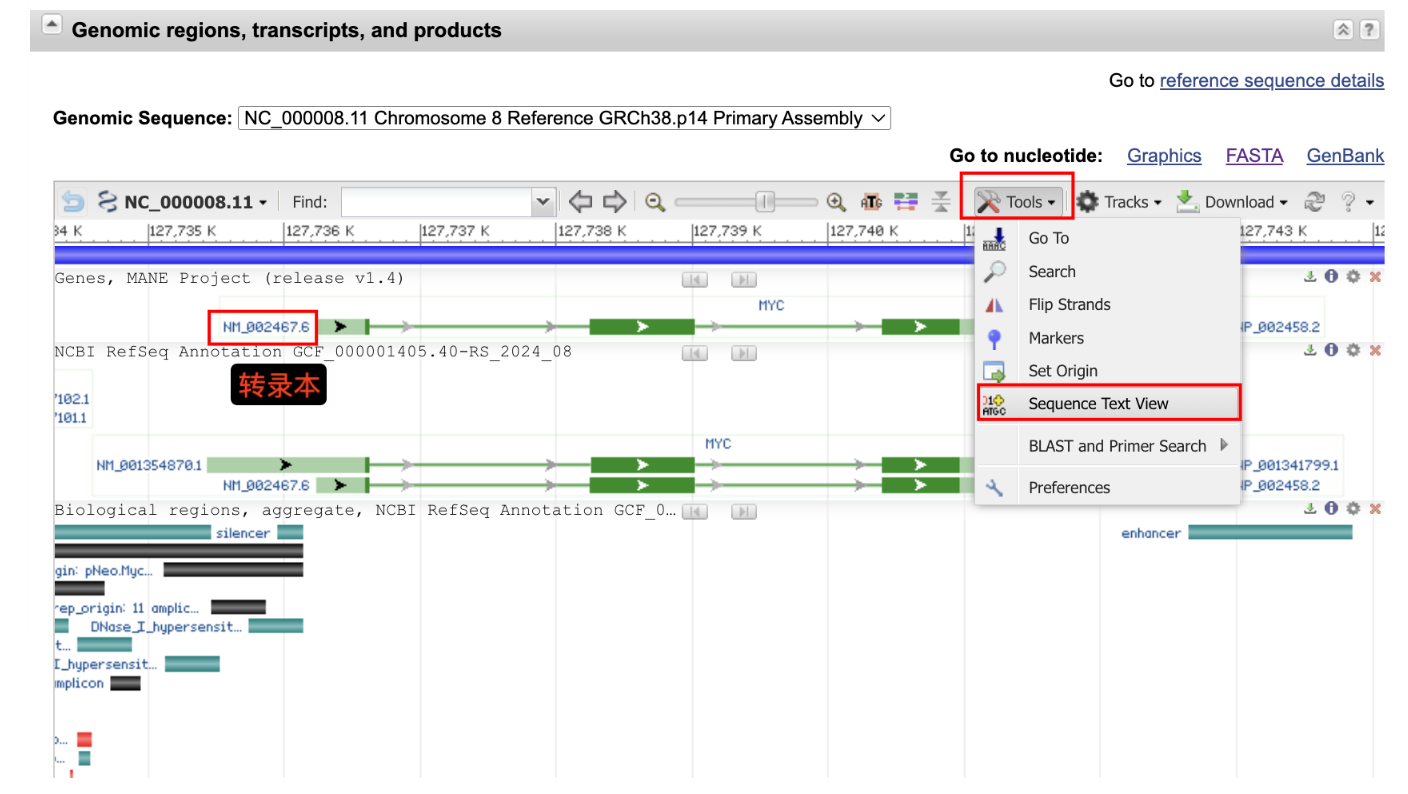
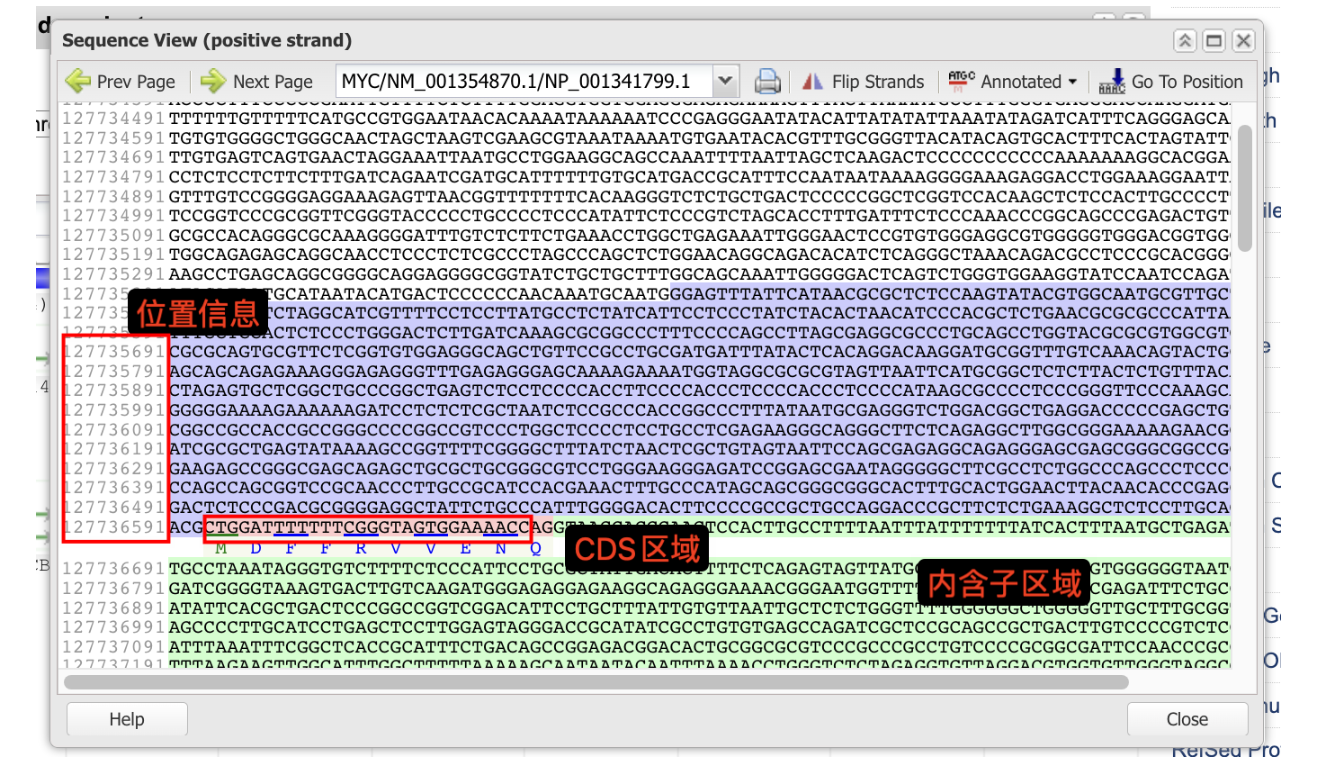
#序列涵盖
约2500bp ---- MYC TSS ---- MYC CDS----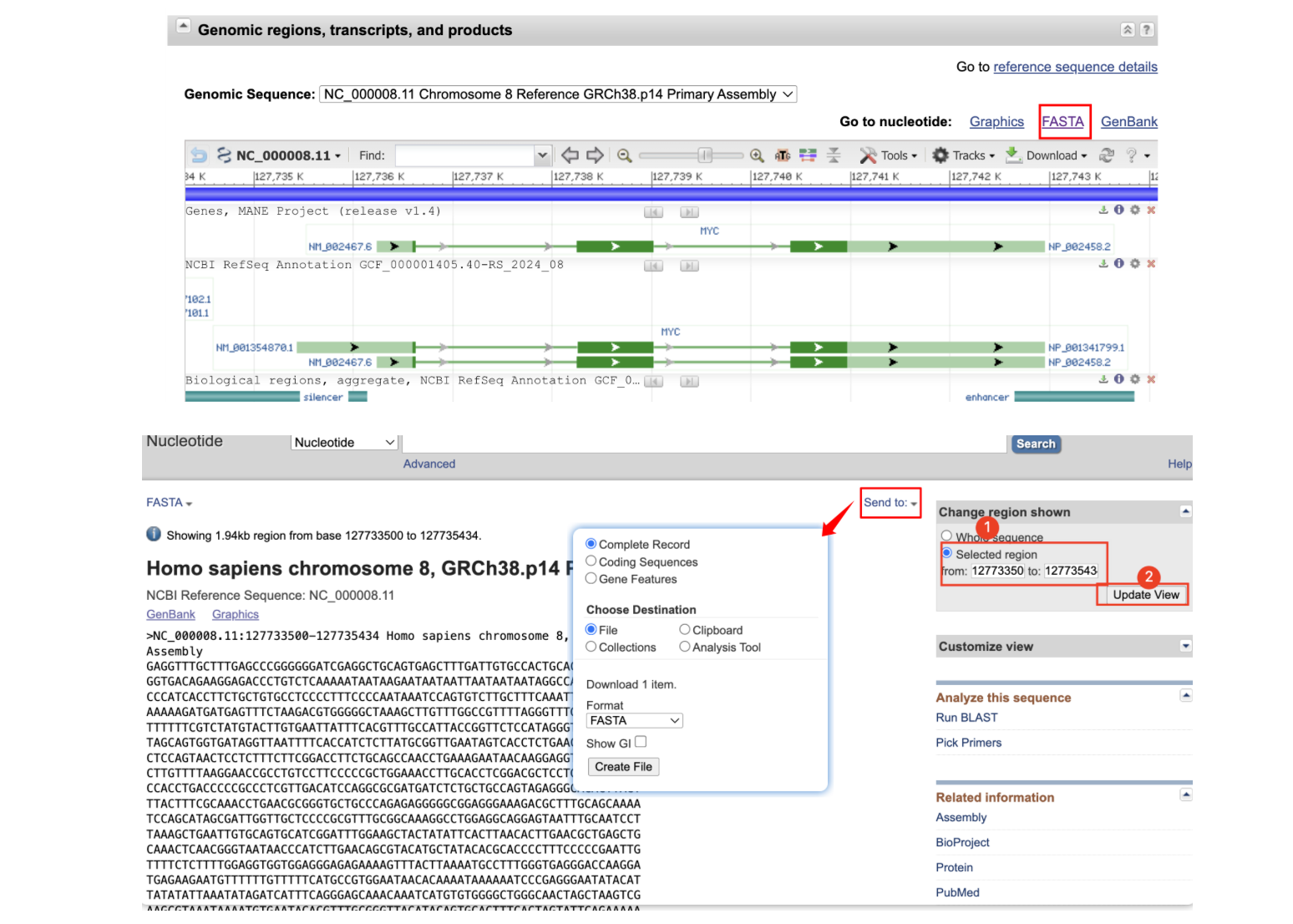
参考教程:


