

产品中心
一、Ollama 是什么?
Ollama 是一个开源的本地大模型部署工具,旨在简化大型语言模型(LLM)的运行和管理。通过简单命令,用户可以在消费级设备上快速启动和运行开源模型(如 Llama、DeepSeek 等),无需复杂配置。它提供 OpenAI 兼容的 API,支持 GPU 加速,并允许自定义模型开发。
二、核心命令速查表
运行 ollama help 可查看所有命令,以下是高频命令总结:
命令 | 作用描述 |
|---|---|
ollama serve | 启动 Ollama 服务(后台运行) |
ollama create | 通过 Modelfile 创建自定义模型 |
ollama run | 运行指定模型(如 ollama run llama3 --gpu) |
ollama list | 列出所有已下载模型 |
ollama ps | 查看正在运行的模型 |
ollama rm | 删除指定模型(如 ollama rm llama3) |
ollama pull | 从注册表拉取模型(如 ollama pull deepseek-r1:70b) |
ollama stop | 停止正在运行的模型 |
ollama show | 显示模型详细信息(如 ollama show qwen) |
三、模型存储路径优化
C:\Users\<用户名>\.ollama~/.ollamaOLLAMA_MODELS,路径设为 D:\ollama\models。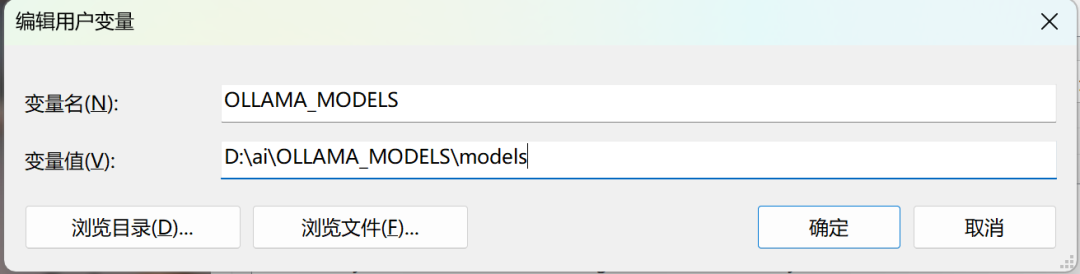
echo 'export OLLAMA_MODELS=/path/to/your/models' >> ~/.bashrc # 或 ~/.zshrc
source ~/.bashrc # 重新加载配置
四、模型管理:从下载到优化
官方模型:
ollama pull llama3 # 下载 Llama3 模型
自定义模型:
Modelfile 配置模板(示例):name: mymodel
template: qwen
path: /path/to/your/model.q4_K_M.gguf
ollama create mymodel -f Modelfile
终端交互:
ollama run --gpu mymodel # 启动 GPU 加速
输入问题后按 Ctrl+D 提交,等待模型响应。
API 调用:
Ollama 内置 OpenAI 兼容 API,通过 http://localhost:11434 访问:
curl http://localhost:11434/v1/models # 查看模型列表
curl -X POST "http://localhost:11434/v1/completions" -H "Content-Type: application/json" -d '{"model":"llama3", "prompt":"你好"}'
显存不足:
deepseek:1.5b)。q4_K_M 或 q3_K_L)。内存不足:
--verbose 参数监控资源消耗:ollama run deepseek-r1:70b --verbose
输出示例:total duration: 12m1.056s # 总耗时
load duration: 1.810s # 模型加载时间
eval rate: 2.09 tokens/s # 生成速度
五、常见问题与解决方案
现象:下载进度停滞在最后阶段。
解决:
Ctrl+C 取消下载 → 再次运行 `ollama pull <model>`
# 进度保留,后续速度可能恢复正常
Modelfile 配置错误(如路径或模板参数)。Modelfile 中的 TEMPLATE 和 stop 参数是否正确。--verbose 日志定位问题。命令:
ollama rm modelname # 删除指定模型
六、安全加固指南
默认风险:Ollama 默认监听 0.0.0.0:11434,可能暴露公网。
解决方案:
# 仅允许本地访问
export OLLAMA_HOST=127.0.0.1:11434
# 或通过环境变量设置
OLLAMA_HOST=127.0.0.1:11434 ollama serve
11434 端口的外部访问。七、总结与建议
DeepSeek 适合代码生成,Qwen 适合多语言)。

