

产品中心
【导读】
你可能已经听说过,YOLO 系列目标检测模型已经迭代到了 YOLOv13。
然而令人意外的是——无论在最新的科研论文里,还是各种真实落地的工业项目中,YOLOv5 和 YOLOv8 依旧是被频繁使用的主力模型。
这是不是有点“技术倒退”的味道?为什么大家不直接用最新的版本?今天我们就来聊聊这个表面“落后”背后的合理逻辑。
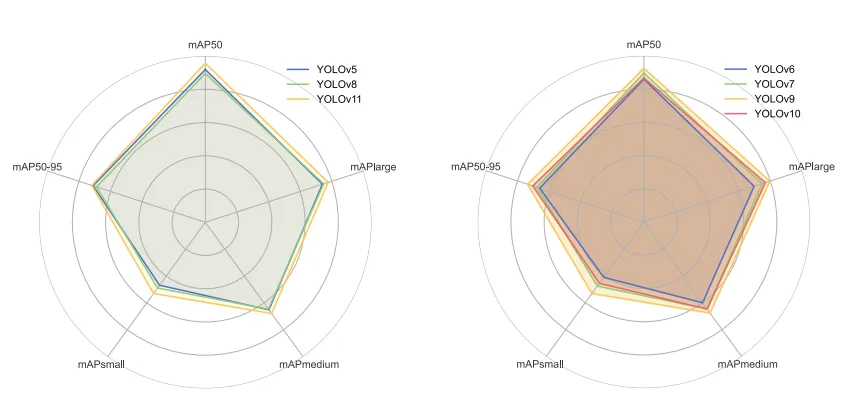
相比之下,YOLOv13、YOLOv12 等虽然看起来“版本号更高”,但往往处于刚发布的早期阶段:
代码尚不稳定、社区响应慢、部署支持不足,不适合直接落地。
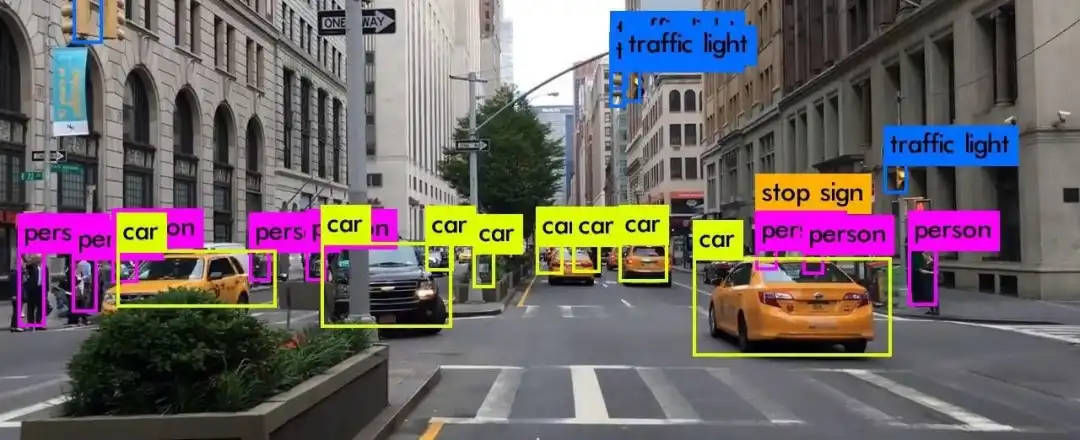
很多人对“最新模型”的想象,往往是基于学术角度:追求0.1%的精度提升。
但工程项目要考虑的,是整体性价比:
在这些场景下,YOLOv5 和 YOLOv8 的“小而强”特性,使它们拥有极大的优势。
YOLOv13 虽然在某些 benchmark 上表现亮眼,但可能模型更复杂、计算资源需求更高,并不适合边缘部署或大规模部署。
Ultralytics 为 YOLOv5 和 YOLOv8 提供了完整的官方支持:从数据集准备、模型训练,到推理部署、模型导出(如ONNX/TensorRT),都有开箱即用的工具。
而像 YOLOv12、v13 等模型,很多还停留在 GitHub 仓库,文档不全、代码配置繁琐、缺乏主流平台适配。
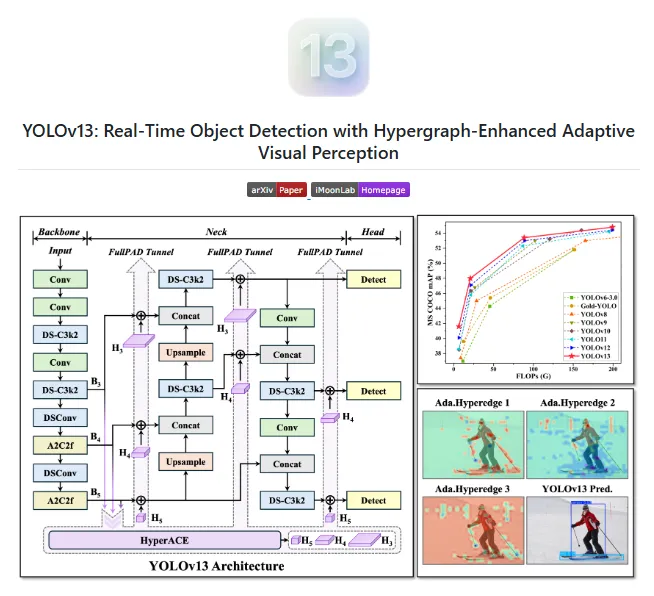
在学术论文中,YOLOv5 和 YOLOv8 已经成为“默认对照组”,被无数研究用作 baseline。


arxiv官网YOLOv5和YOLOv8搜索结果
这就意味着,如果你用这两个模型作为起点,不仅容易被 reviewer 理解,实验结果也更容易和他人进行比较。
而如果你一上来就用 YOLOv13,可能评审还要花时间去理解模型结构、代码实现、训练细节,影响论文接受效率。
换句话说,YOLOv5/v8 是一套“学术通用语言”,而 YOLOv13 还只是“尝试方言”。
在真正的项目落地中,模型的选择很少是“谁最新”或者“谁更炫”,而是:
如果 YOLOv5 已经能将检测精度做到 95%,那 YOLOv13 哪怕能再提 1%,但部署难度、算力成本、维护复杂度都更高,工程上往往是不划算的。
所以,越来越多企业、研究者、开发者达成了一个共识:
与其追逐“前沿”,不如用好“成熟”。
YOLOv13 当然好,它代表了目标检测的研究方向正在不断前进。
但从实际应用的角度看,YOLOv5 和 YOLOv8 依旧是目前“最值得用”的版本。
它们兼顾性能、速度、成本与生态,适合教学、科研和商业落地,是目标检测领域真正的“黄金一代”。
如果你也想快速体验目标检测模型的魅力,或者正在寻找部署级别的解决方案,不妨试试在 Coovally 平台上试一试——一键上手,从不折腾。


