

产品中心
知识蒸馏(Knowledge Distillation,KD)作为深度学习领域中的一种模型压缩技术,主要用于将大规模、复杂的神经网络模型(即教师模型)压缩为较小的、轻量化的模型(即学生模型)。在实际应用中,这种方法有助于减少模型的计算成本和内存占用,同时保持相对较高的性能和准确率。本文将详细介绍知识蒸馏的原理、C++实现代码、以及其在实际项目中的应用。
知识蒸馏最初由Hinton等人提出,目的是解决大型模型在部署时的资源消耗问题。其基本思想是通过让一个较小的模型学习较大模型的预测分布来获得类似的表现。蒸馏过程包括两个主要模型:
知识蒸馏的核心思想是在训练学生模型时,不仅仅依赖于传统的硬标签(Hard Labels),而是使用教师模型的软标签(Soft Labels)。这些软标签包含了教师模型对输入的概率分布信息,从而帮助学生模型更好地学习知识。
教师模型的输出通常是一个分类任务中的概率分布。例如,对于一个有3个类别的分类问题,教师模型的输出可能是 [0.7, 0.2, 0.1],这代表教师模型对输入属于类别1、类别2和类别3的概率。这种分布通常比硬标签(例如 [1, 0, 0])提供了更多的信息,尤其是对于模棱两可的样本。
通过引入温度参数(Temperature Parameter,T),可以控制教师模型输出的软标签分布。温度越高,概率分布越平滑,从而提供更多的关于各个类别的相对信息。温度较低时,软标签分布更接近硬标签。
在知识蒸馏中,损失函数通常由两部分组成:
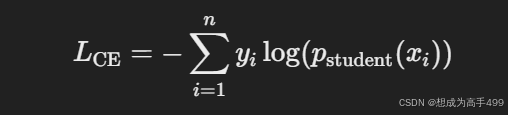
其中,yi是第 i 个样本的真实标签,Pstudent(xi)是学生模型对该样本的预测概率。
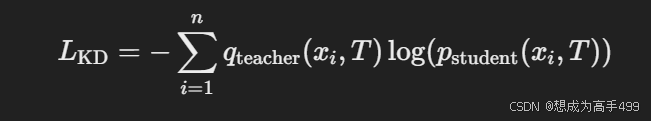
其中,T是温度参数,qteacher(xi,T)是教师模型在温度 TTT 下的输出概率分布,Pstudent(xi,T)是学生模型在相同温度下的预测。
最后,总损失函数 LLL 是标准交叉熵损失和蒸馏损失的加权和:

其中,α是用于调节两者权重的超参数。

首先,需要安装并配置libtorch,然后可以开始搭建代码框架。
#include <torch/torch.h>
#include <iostream>
// 定义一个简单的教师模型
struct TeacherNet : torch::nn::Module {
torch::nn::Linear fc1{nullptr}, fc2{nullptr}, fc3{nullptr};
TeacherNet() {
fc1 = register_module("fc1", torch::nn::Linear(784, 128));
fc2 = register_module("fc2", torch::nn::Linear(128, 64));
fc3 = register_module("fc3", torch::nn::Linear(64, 10));
}
torch::Tensor forward(torch::Tensor x) {
x = torch::relu(fc1->forward(x));
x = torch::relu(fc2->forward(x));
x = torch::log_softmax(fc3->forward(x), /*dim=*/1);
return x;
}
};
// 定义一个学生模型
struct StudentNet : torch::nn::Module {
torch::nn::Linear fc1{nullptr}, fc2{nullptr};
StudentNet() {
fc1 = register_module("fc1", torch::nn::Linear(784, 64));
fc2 = register_module("fc2", torch::nn::Linear(64, 10));
}
torch::Tensor forward(torch::Tensor x) {
x = torch::relu(fc1->forward(x));
x = torch::log_softmax(fc2->forward(x), /*dim=*/1);
return x;
}
};
int main() {
// 初始化模型
auto teacher = std::make_shared<TeacherNet>();
auto student = std::make_shared<StudentNet>();
// 假设我们有一些输入数据
torch::Tensor input = torch::randn({64, 784}); // 64个样本,每个样本784维
torch::Tensor hard_labels = torch::randint(0, 10, {64}); // 硬标签
// 教师模型的输出 (soft labels)
torch::Tensor teacher_output = teacher->forward(input);
// 学生模型的输出
torch::Tensor student_output = student->forward(input);
// 定义温度
float temperature = 3.0;
// 使用softmax调整教师输出的概率分布(加温度)
torch::Tensor teacher_soft_labels = torch::softmax(teacher_output / temperature, 1);
torch::Tensor student_soft_output = torch::softmax(student_output / temperature, 1);
// 定义损失函数
auto kd_loss = torch::nn::functional::kl_div(student_soft_output.log(), teacher_soft_labels, {}, Reduction::BatchMean);
std::cout << "蒸馏损失: " << kd_loss.item<float>() << std::endl;
return 0;
}在这段代码中,我们首先定义了一个简单的教师模型和一个较小的学生模型,二者都是使用全连接层(Linear)构成的。然后,通过教师模型对输入进行前向传播,生成软标签(概率分布)。学生模型则根据这些软标签进行训练。
关键部分是损失计算:我们使用了KL散度损失(KL-Divergence),并且将教师模型的输出概率通过温度参数调整,使其更加平滑。最后,将学生模型的输出和教师模型的软标签进行对比,以此来训练学生模型。
知识蒸馏技术广泛应用于各种需要压缩模型的场景,尤其是在资源有限的环境下,例如:
温度参数 TTT 在知识蒸馏中起着重要的作用,它用于控制教师模型输出的软标签分布。较高的温度 TTT 会让教师模型的输出分布变得更平滑,即对每个类别的概率预测更加模糊。这种情况下,学生模型可以学习到更为丰富的信息,包括错误类别的概率分布。
优化温度参数的方法:
在知识蒸馏中,损失函数通常由两部分组成:一个是标准交叉熵损失(用于拟合真实标签),另一个是蒸馏损失(用于学习教师模型的输出分布)。权重参数 α\alphaα 用于调节这两部分损失的影响。
优化策略:
教师模型通常是较大的、复杂的网络,而学生模型则是较小的、轻量化的网络。在设计学生模型时,可以考虑以下几点:
在深度学习中,数据增强可以提高模型的泛化能力。在知识蒸馏过程中,通过数据增强可以让学生模型学习更加多样化的输入模式,增强其对不同数据分布的适应性。
常用的数据增强方法包括:
传统的知识蒸馏方法通常只关注模型输出层的蒸馏,即教师模型与学生模型的预测结果之间的蒸馏。然而,在深层神经网络中,中间层的特征也包含了大量有用的信息。通过对中间层的特征进行蒸馏,学生模型可以更好地学习教师模型的表示能力。
优化方法:
除了学生模型,教师模型本身的设计和训练策略也会影响蒸馏效果。选择一个更强的教师模型,往往可以使学生模型学习到更有用的知识。
优化策略:
在标准的知识蒸馏过程中,教师模型是固定的,学生模型根据教师模型的输出进行学习。但实际上,学生模型也可以反过来影响教师模型的训练,称为互学习(Mutual Learning)。
互学习方法:
对抗蒸馏是知识蒸馏与生成对抗网络(GAN)结合的一种新方法,目标是通过对抗训练,使学生模型在学习教师模型知识的同时能够生成更真实、更接近教师模型的输出。
优化策略:
通常,知识蒸馏使用整个训练集来训练学生模型,但在某些情况下,并非所有数据样本对学生模型的学习同等重要。某些难度较大的样本可能对提高学生模型的泛化能力更有帮助。
优化策略:
在知识蒸馏过程中,优化训练过程可以进一步提升学生模型的性能:
知识蒸馏是一种有效的模型压缩技术,通过优化温度参数、损失函数权重、中间层特征对齐、数据增强等多种手段,可以显著提高学生模型的性能。此外,结合对抗训练、互学习等新技术,还可以进一步提升蒸馏效果。
这些优化策略可以根据实际情况进行组合应用,具体的效果取决于任务的复杂度、数据集的特征以及模型的设计。通过反复实验和调参,可以找到适合特定任务的最佳蒸馏策略。


