

产品中心
【导读】
YOLO 系列从 v1 一路进化到 v13,始终在追求更快、更准、更轻的目标检测模型。而刚刚发布的 YOLOv13,不仅性能全系领先,还带来了“超图”这个硬核概念 —— 帮助模型在复杂场景中“看得更远、看得更懂”。本篇就带你快速理解它的创新点和实战表现!
就在6月21日,由清华大学、太原理工大学、北京理工大学、深圳大学、香港科技大学(广州)、西安交通大学等高校组成的联合研究团队正式发布了 YOLOv13 模型。

论文标题: YOLOv13: Real-Time Object Detection with Hypergraph-Enhanced Adaptive Visual Perception 论文链接: https://arxiv.org/abs/2506.17733
该模型在继承 YOLO 系列实时检测优点的基础上,引入了超图增强、高阶语义建模、轻量化结构重构等一系列新机制,在 MS COCO 和 Pascal VOC 等主流数据集上实现了全面领先,展现出更强的泛化能力与部署实用性。
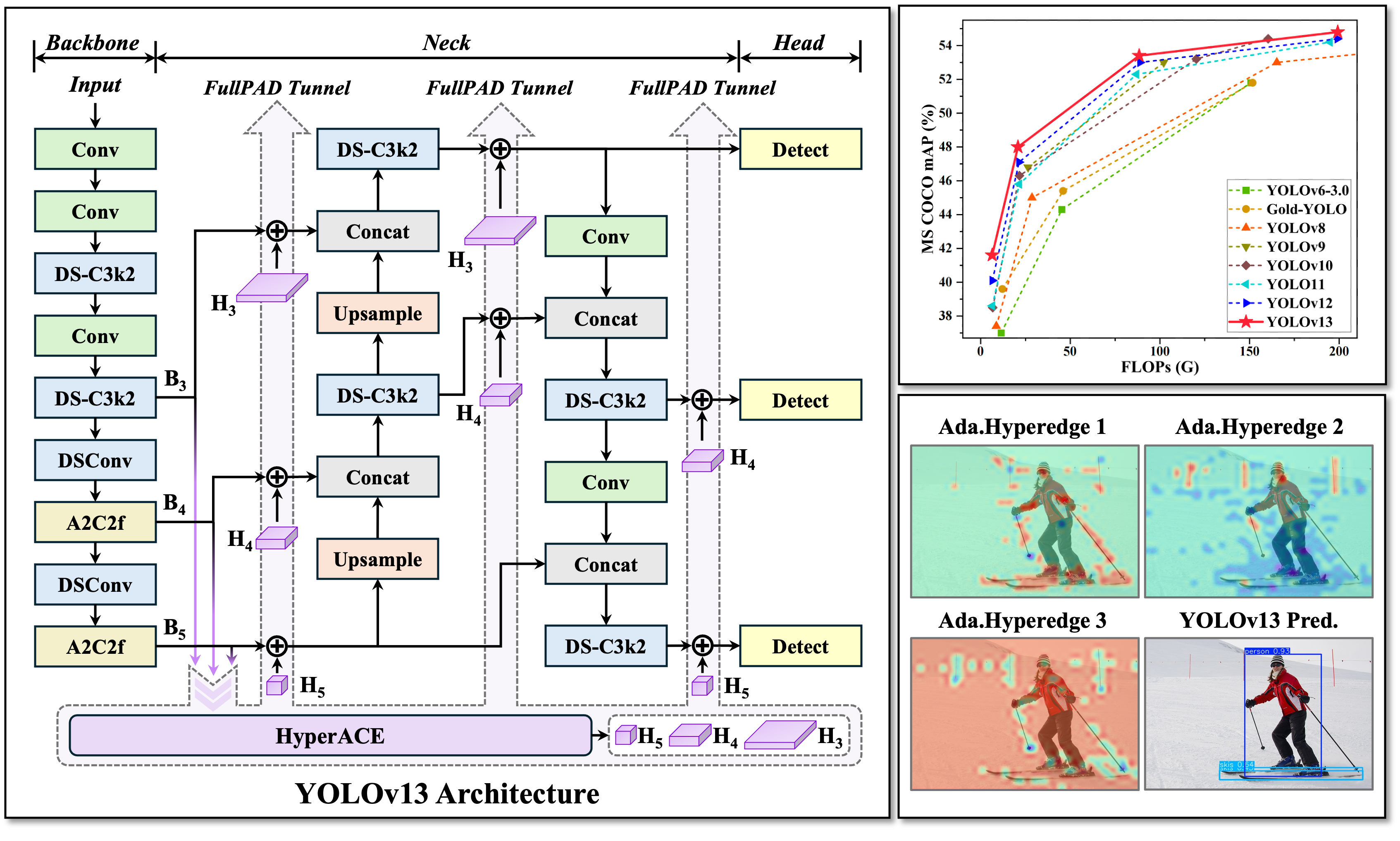
根据论文,YOLOv13 在 MS COCO 和 Pascal VOC 两大数据集上实现了全面领先:
在结构介绍之前,我们先来做个快速总结,看看 YOLOv13 的三大关键升级:
用超图机制(HyperACE),替代以往只能处理局部关联的卷积和自注意力,让模型能识别出多个物体之间复杂的潜在关系。
通过全流程信息分发(FullPAD),让增强后的特征流通到 YOLO 的各个部分(Backbone、Neck、Head),实现更细致的特征融合。
采用了大量深度可分离卷积(DSConv),大幅减少模型参数和计算量,特别适合边缘设备部署。
一句话总结:YOLOv13 不是小改,而是一次架构级的“重构+轻量融合”大更新。
传统 YOLO 系列,无论是卷积提取局部特征,还是 v12 中引入的自注意力增强局部区域,都有个短板:只能建模点对点(pairwise)的相关性。
但在复杂场景下,多个物体之间存在潜在的组合关系,比如:

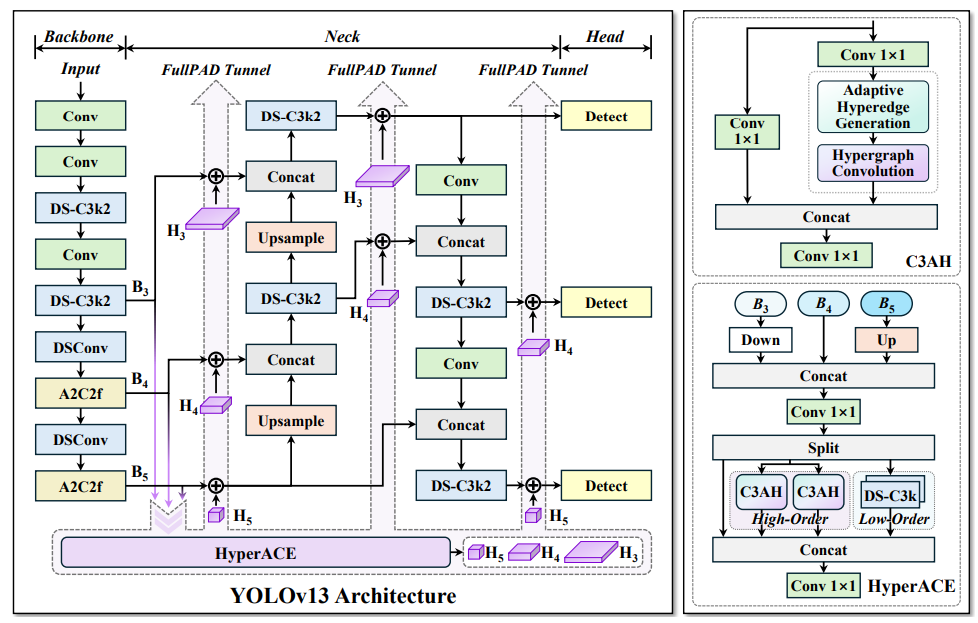
YOLOv13 引入了HyperACE(超图自适应相关增强机制),通过可学习的超边(Hyperedge)构建方式,让模型自动发掘这些“多对多”的语义关系,突破了“只能点对点”的限制。
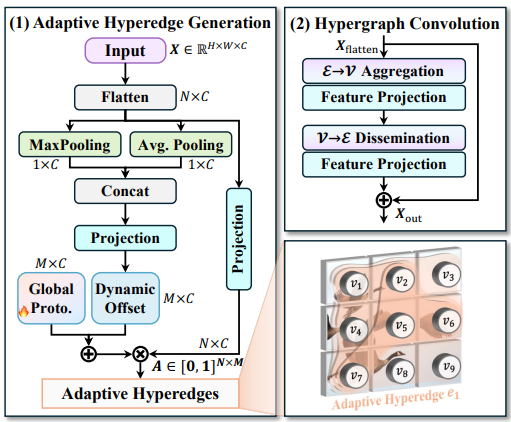
这种方式带来几点显著优势:
✅ 检测遮挡物体、小目标更准确
✅ 适应复杂场景更强,比如交通、室内、体育等
✅ 模型更具解释性,可视化结果显示了特征间真实的多阶联系
YOLOv13 不再满足于传统的 “Backbone → Neck → Head” 三段式信息流。
它设计了一个新的全流程信息增强机制 FullPAD(Full-Pipeline Aggregation and Distribution):
这就像为模型建立了一套“高速公路网”,信息不再是单向线性流动,而是网状协同工作。
实际效果如何?如下图所示:
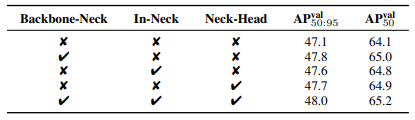
每一处 FullPAD 的加入都能带来性能提升,最终组合效果最好。
性能提升还不够,YOLOv13 也非常注重模型的实用性,特别是部署在边缘设备或低算力平台时。
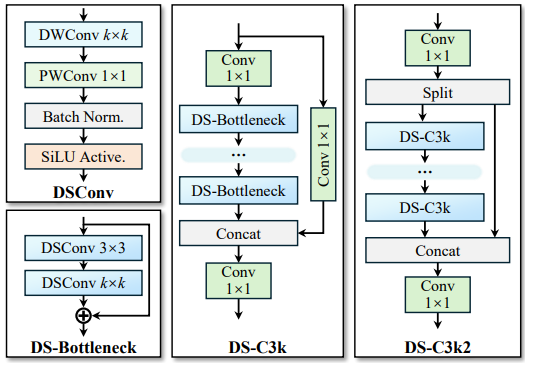
为此,它提出了多种基于 Depthwise Separable Conv 的轻量模块:
对比来看:
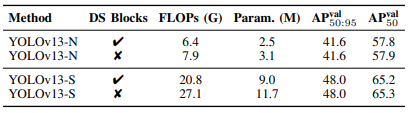
性能持平,算力成本降低近 20%,特别适合推理侧部署。
不止精度提升,参数和算力都下降,进一步验证架构优化不是堆料,而是真实有效。
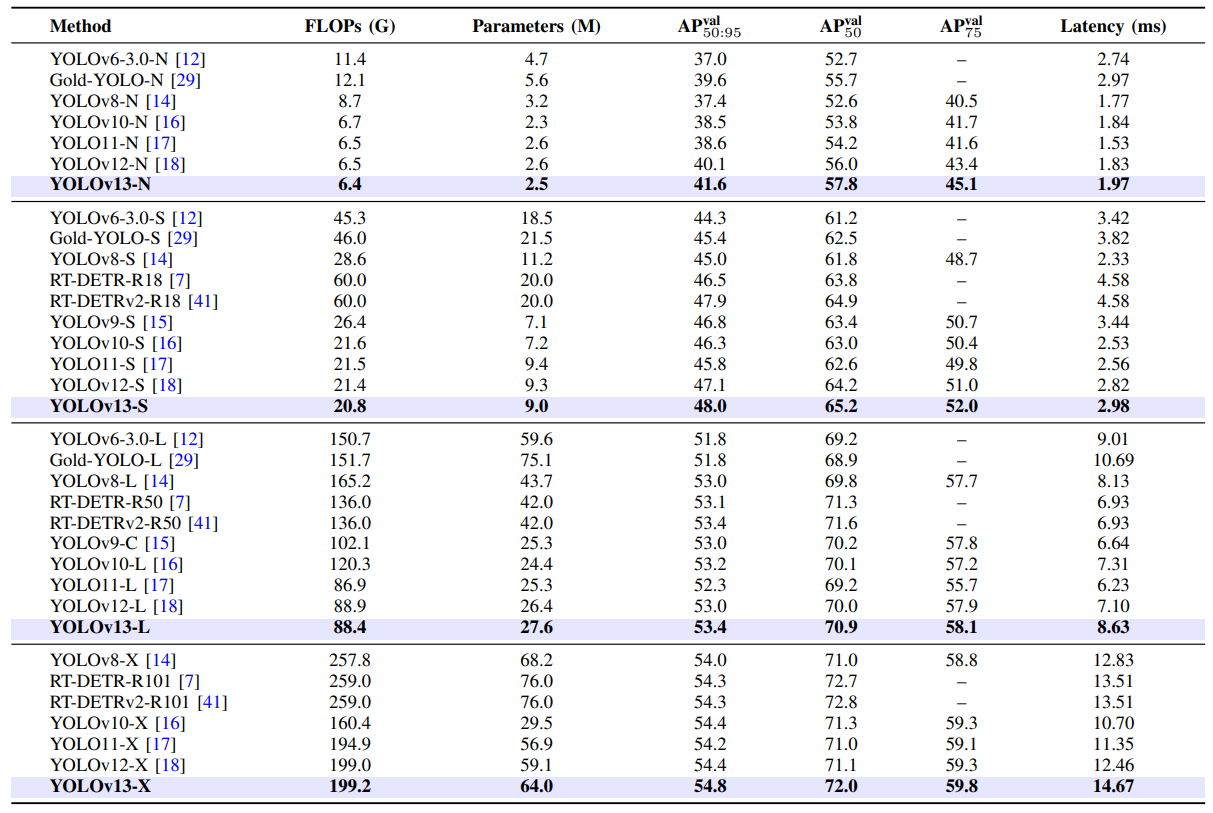

YOLOv13 的优秀不仅体现在 COCO 数据集,在跨域测试中依然出色:
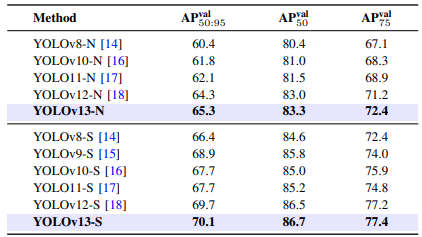
说明 YOLOv13 更懂“举一反三”,不仅学得好,也泛得开。
YOLOv13 是一次“结构级的飞跃”。它把高阶相关建模真正带进了实时检测任务里,并通过轻量优化和全流程融合机制,把速度、精度和部署成本三者做到了真正意义上的平衡。
未来,如果你想做目标检测模型优化、端侧部署,或者需要一个“复杂场景也能应对”的强大检测模型,YOLOv13 一定是你绕不开的一环。


