

产品中心
YOLOv13 的创新点主要体现在以下几个方面:
超图自适应相关性增强机制 HyperACE
全流程聚合 - 分发范式 FullPAD
基于深度可分离卷积的轻量化模块
博主简介
AI小怪兽,YOLO骨灰级玩家,1)YOLOv5、v7、v8、v9、v10、11、v12、v13优化创新,轻松涨点和模型轻量化;2)目标检测、语义分割、OCR、分类等技术孵化,赋能智能制造,工业项目落地经验丰富;

1.YOLOv13介绍

论文:[2506.17733] YOLOv13: Real-Time Object Detection with Hypergraph-Enhanced Adaptive Visual Perception摘要—YOLO 系列模型因其卓越的准确性和计算效率在实时目标检测领域占据主导地位。然而,无论是 YOLO11 及更早版本的卷积架构,还是 YOLOv12 引入的基于区域的自注意力机制,都仅限于局部信息聚合和成对相关性建模,缺乏捕捉全局多对多高阶相关性的能力,这限制了在复杂场景下的检测性能。本文提出了一种准确且轻量化的 YOLOv13 目标检测器。为应对上述挑战,我们提出了一种基于超图的自适应相关性增强(HyperACE)机制,通过超图计算自适应地利用潜在的高阶相关性,克服了以往方法仅基于成对相关性建模的限制,实现了高效的全局跨位置和跨尺度特征融合与增强。随后,我们基于 HyperACE 提出了全链路聚合与分配(FullPAD)范式,通过将相关性增强特征分配到整个网络,有效实现了全网的细粒度信息流和表征协同。最后,我们提出用深度可分离卷积代替常规的大核卷积,并设计了一系列块结构,在不牺牲性能的前提下显著降低了参数量和计算复杂度。我们在广泛使用的 MS COCO 基准测试上进行了大量实验,结果表明,我们的方法在参数更少、浮点运算量更少的情况下达到了最先进性能。具体而言,我们的 YOLOv13-N 相比 YOLO11-N 提升了 3.0% 的 mAP,相比 YOLOv12-N 提升了 1.5% 的 mAP。
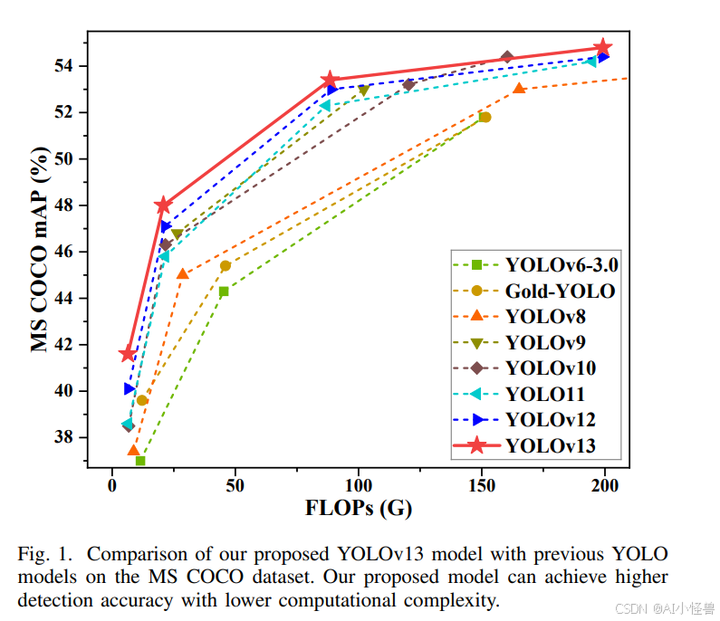
为应对上述挑战,我们提出了 YOLOv13,一款新颖的实时突破性端到端目标检测器。我们的 YOLOv13 模型将传统的基于区域的成对交互建模拓展到全局高阶关联建模,使网络能够感知跨空间位置和尺度的深层语义关联,从而在复杂场景下显著提升检测性能。具体而言,为克服现有方法中手工设计的超边构造导致的鲁棒性和泛化能力局限,我们提出了一种新颖的基于超图的自适应关联增强机制 HyperACE。HyperACE 将多尺度特征图中的像素作为顶点,并采用可学习的超边构造模块自适应地挖掘顶点间的高阶关联。随后,利用具有线性复杂度的消息传递模块,借助高阶关联有效聚合多尺度特征,实现复杂场景的有效视觉感知。此外,HyperACE 还整合了低阶关联建模,以实现完整的视觉感知。基于 HyperACE,我们提出了一种全新的 YOLO 架构,即包含全链路聚合与分配范式的 FullPAD。我们提出的 FullPAD 利用 HyperACE 机制聚合骨干网络提取的多级特征,然后将增强关联的特征分配到骨干网络、颈部和检测头中,以实现整个链路的细粒度信息流和表征协同,显著改善梯度传播并提升检测性能。最后,为在不牺牲性能的前提下减小模型尺寸并降低计算成本,我们提出了一系列基于深度可分离卷积的轻量化特征提取模块。通过用深度可分离卷积模块替换大核普通卷积模块,可实现更快的推理速度和更小的模型尺寸,从而在效率和性能之间取得更佳平衡。为验证所提模型的有效性和效率,我们在广泛使用的 MS COCO 基准测试上进行了大量实验。定量和定性实验结果表明,我们的方法在保持轻量化的同时超越了所有先前的 YOLO 模型及变体。特别是 YOLOv13-N/S 相比 YOLOv12-N/S 和 YOLO11-N/S,分别实现了 1.5%/0.9% 和 3.0%/2.2% 的 mAP 提升。消融实验进一步证明了所提各模块的有效性。
我们的贡献总结如下: 1)我们提出了 YOLOv13,一款卓越的实时端到端目标检测器。我们的 YOLOv13 模型利用自适应超图来探索潜在的高阶关联,并基于高阶关联的有效信息聚合与分配,实现准确且鲁棒的检测。 2)我们提出了 HyperACE 机制,借助自适应超图计算捕捉复杂场景中潜在的高阶关联,实现基于关联指导的特征增强。我们提出了 FullPAD 范式,以在整个链路中实现多尺度特征的聚合与分配,增强信息流和表征协同。我们提出了一系列基于深度可分离卷积的轻量化模块,以替代大核普通卷积模块,显著减少了参数数量和计算复杂度。 3)我们在 MS COCO 基准测试上进行了大量实验。实验结果表明,我们的 YOLOv13 在保持轻量化的同时,实现了最先进的检测性能。
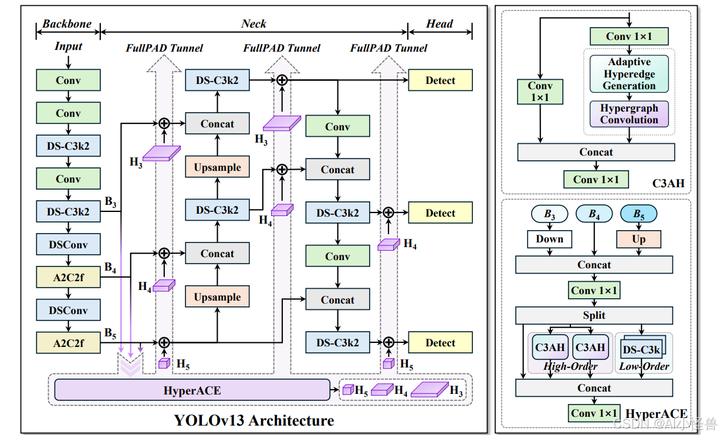
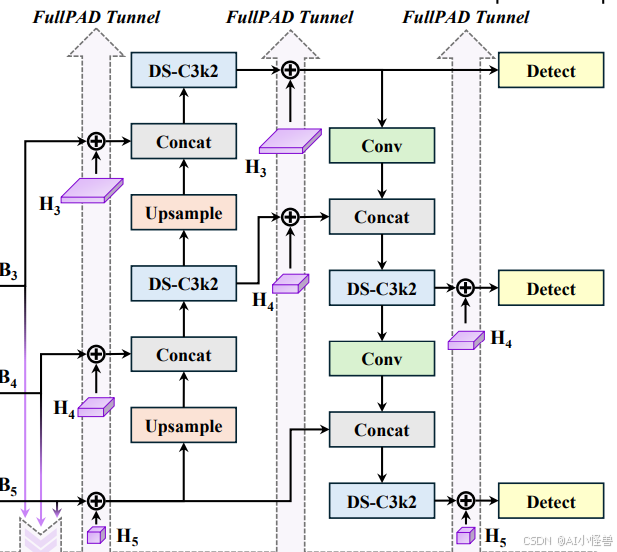
以往的 YOLO 系列遵循 “骨干网络 → 颈部网络 → 检测头” 的计算范式,这本质上限定了信息流的充分传输。相比之下,我们的模型通过超图自适应关联增强(HyperACE)机制,实现全链路特征聚合与分配(FullPAD),从而增强传统的 YOLO 架构。因此,我们提出的方法在整个网络中实现了细粒度的信息流和表征协同,能够改善梯度传播并显著提升检测性能。具体而言,如图 2 所示,我们的 YOLOv13 模型首先使用类似以往工作的骨干网络提取多尺度特征图 B1、B2、B3、B4、B5,但其中的大核卷积被我们提出的轻量化 DS-C3k2 模块取代。然后,与传统 YOLO 方法直接将 B3、B4 和 B5 输入颈部网络不同,我们的方法将这些特征收集并传递到提出的 HyperACE 模块中,实现跨尺度跨位置特征的高阶关联自适应建模和特征增强。随后,我们的 FullPAD 范式利用三个独立通道,将关联增强后的特征分别分配到骨干网络与颈部网络的连接处、颈部网络的内部层以及颈部网络与检测头的连接处,以优化信息流。最后,颈部网络的输出特征图被传递到检测头中,实现多尺度目标检测。
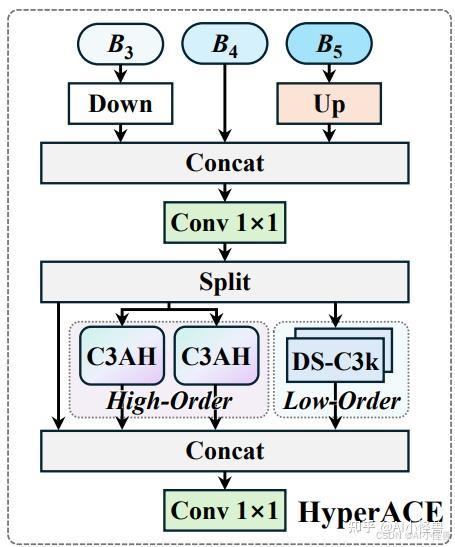
为实现高效且鲁棒的跨尺度跨位置关联建模和特征增强,我们提出了一种基于超图的自适应关联增强机制。如图 2 所示,HyperACE 包含两个核心组件,即基于 C3AH 模块的全局高阶感知分支,该分支利用自适应超图计算以线性复杂度建模高阶视觉关联,以及基于 DS-C3k 模块的局部低阶感知分支。在接下来的子部分中,我们将分别介绍自适应超图计算、C3AH 模块以及 HyperACE 的整体设计。
1)自适应超图计算:为高效、有效地建模视觉特征的高阶关联,并实现关联指导的特征聚合与增强,我们提出了一种新颖的自适应超图计算范式。与传统超图建模方法不同,后者使用手动预定义的参数基于特征相似性构造超边,而我们的方法则自适应地学习每个顶点在每个超边中的参与度,使这种计算范式更加鲁棒和高效。传统超图计算范式更适用于包含明确连接关系的非欧几里得数据(例如社交网络),而我们的自适应超图计算范式更有利于计算机视觉任务。
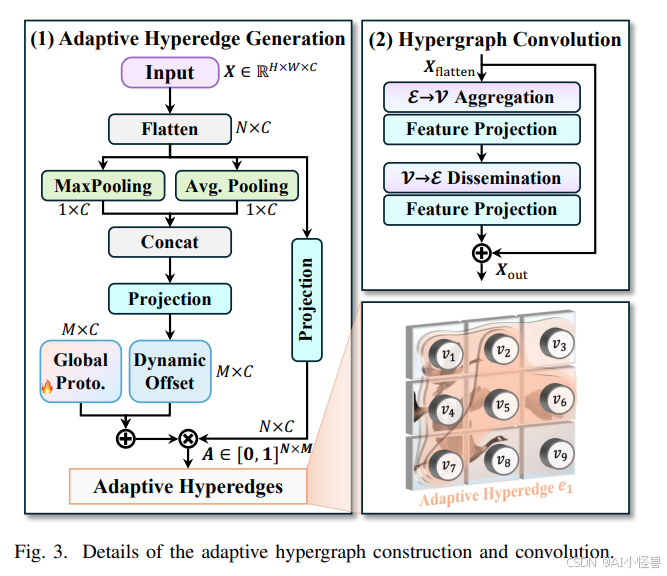
为充分利用 HyperACE 获得的关联增强特征,我们进一步引入了 FullPAD 范式。具体而言,FullPAD 从骨干网络收集多尺度特征图并将其传入 HyperACE,然后通过不同的 FullPAD 通道将增强后的特征重新分配到整个链路的各个位置,如图 2 所示。这种设计实现了细粒度的信息流和表征协同,显著改善了梯度传播并提升了检测性能。
在我们提出的 YOLOv13 中,我们采用大核深度可分离卷积(DSConv)作为基本单元来设计一系列轻量化的特征提取模块,如图 4 所示,这显著减少了参数数量和计算复杂度,同时没有降低模型性能。
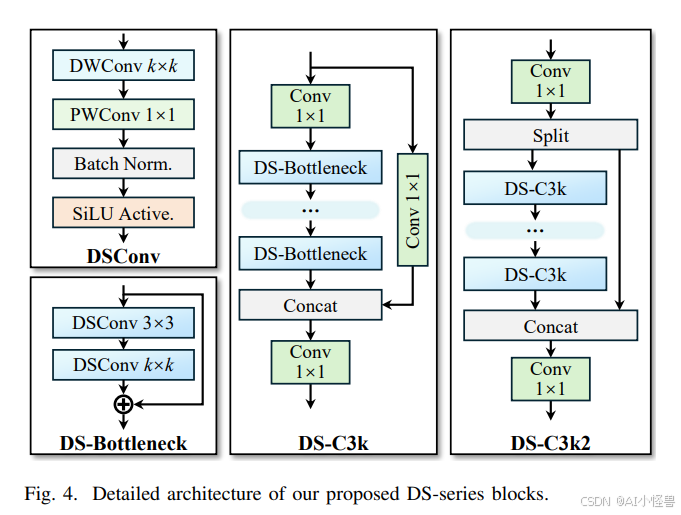
DSConv(深度可分离卷积)模块首先应用标准的深度可分离卷积层来提取特征,然后利用批量归一化和 SiLU 激活函数来获得输出,即:
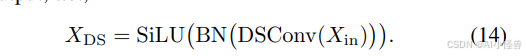
如图 2 所示,我们提出的 YOLOv13 模型在骨干网络和颈部网络中广泛使用 DS-C3k2 模块作为基本的特征提取单元。在 HyperACE 中,我们采用 DS-C3k 模块作为低阶特征提取器。这种设计在所有 YOLOv13 模型尺寸中实现了高达 30% 的参数减少和高达 28% 的 GFLOPs(十亿浮点运算次数)减少。通过使用我们提出的 YOLOv13 模型,视觉特征中的潜在关联得以自适应地建模,并且通过在整个链路中充分传播关联增强特征,可以在复杂场景中实现准确且高效的目标检测。
表 I 显示了在 MS COCO 数据集上的量化比较结果。我们提出的方法与之前的 YOLO 系列模型进行了比较。如上所述,我们的 YOLOv13 模型与最新的 YOLO11 和 YOLOv12 模型在相同的 GPU 上进行训练,而现有方法则使用其官方代码和训练参数进行训练。从表中可以看出,我们 YOLOv13 模型的所有变体在保持轻量化的同时均实现了最先进的性能。具体而言,与之前的 YOLOv12 模型相比,我们的 YOLOv13 模型在 Nano、Small、Large 和 Extra-Large 模型上分别将 APval50:95 提高了 1.5%、0.9%、0.4% 和 0.4%,并将 APval50:95 提高了 1.8%、1.0%、0.9% 和 0.9%。此外,与基于 ViT 的方法相比,我们的 YOLOv13 模型在参数更少、计算复杂度更低的情况下也能实现更好的检测精度。与 RT-DETRv2-R18 相比,我们的 YOLOv13-S 模型将 APval50:95 提高了 0.1%,同时将参数数量减少了 55.0%,将 FLOPs 减少了 65.3%。此外,从表中可以看出,我们的方法在轻量级变体中具有更显著的优势,例如 Nano 模型。这也是 YOLO 系列模型的核心目标,即更准确、更快、更轻。这是因为我们提出的 HyperACE 机制能够更充分地挖掘复杂场景中的多对多关联。作为传统自注意力机制的高阶版本,HyperACE 利用高阶关联作为指导,在低参数数量和计算复杂度的情况下实现准确的特征增强。这些量化比较结果证明了我们提出的 YOLOv13 模型的有效性。
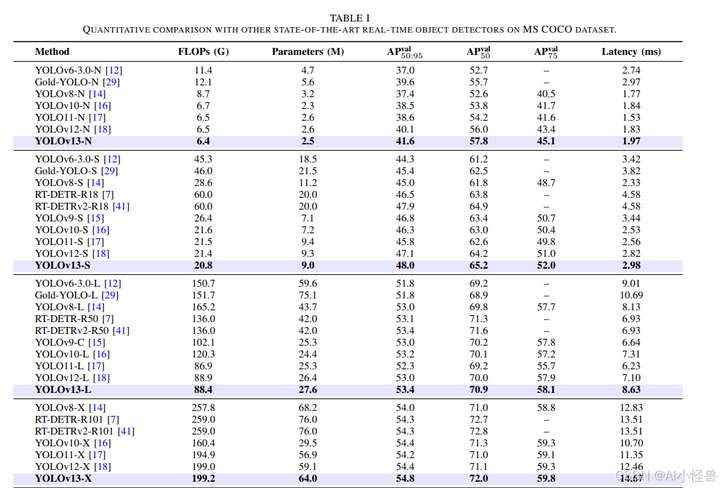
图 5 展示了在 MS COCO 数据集上的定性比较结果。我们提出的 YOLOv13 模型与现有的 YOLOv10[16]、YOLO11[17] 和 YOLOv12[18] 模型进行了比较。从图中可以看出,我们的 YOLOv13 模型在复杂场景中能够实现更准确的检测性能。具体而言,如图 5 左侧最后一行所示,我们的 YOLOv13-N 模型能够在复杂的多目标场景中准确检测物体。相比之下,之前的模型会遗漏像碗和花瓶这样的小物体。这是由于我们提出的 HyperACE 能够在多个相关物体之间建立高阶关联,从而在复杂场景中准确检测多个目标。如右侧第二行所示,只有我们的方法成功检测到了花瓶后面的植物,这是一种具有挑战性的情况。直观来看,花瓶和植物之间的关联性很强,这导致植物出现的概率很高。我们的方法可以通过挖掘这种潜在关联来实现准确检测。如右侧第三行所示,我们的方法能够准确检测运动员持有的网球拍,而之前的方法要么遗漏了它,要么错误地检测到了阴影。这些定性结果证明了我们提出的方法的有效性。

ultralytics/cfg/models/v13/yolov13.yaml
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov13n.yaml' will call yolov13.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # Nano
s: [0.50, 0.50, 1024] # Small
l: [1.00, 1.00, 512] # Large
x: [1.00, 1.50, 512] # Extra Large
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2, 1, 2]] # 1-P2/4
- [-1, 2, DSC3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2, 1, 4]] # 3-P3/8
- [-1, 2, DSC3k2, [512, False, 0.25]]
- [-1, 1, DSConv, [512, 3, 2]] # 5-P4/16
- [-1, 4, A2C2f, [512, True, 4]]
- [-1, 1, DSConv, [1024, 3, 2]] # 7-P5/32
- [-1, 4, A2C2f, [1024, True, 1]] # 8
head:
- [[4, 6, 8], 2, HyperACE, [512, 8, True, True, 0.5, 1, "both"]]
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [ 9, 1, DownsampleConv, []]
- [[6, 9], 1, FullPAD_Tunnel, []] #12
- [[4, 10], 1, FullPAD_Tunnel, []] #13
- [[8, 11], 1, FullPAD_Tunnel, []] #14
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 12], 1, Concat, [1]] # cat backbone P4
- [-1, 2, DSC3k2, [512, True]] # 17
- [[-1, 9], 1, FullPAD_Tunnel, []] #18
- [17, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 13], 1, Concat, [1]] # cat backbone P3
- [-1, 2, DSC3k2, [256, True]] # 21
- [10, 1, Conv, [256, 1, 1]]
- [[21, 22], 1, FullPAD_Tunnel, []] #23
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 18], 1, Concat, [1]] # cat head P4
- [-1, 2, DSC3k2, [512, True]] # 26
- [[-1, 9], 1, FullPAD_Tunnel, []]
- [26, 1, Conv, [512, 3, 2]]
- [[-1, 14], 1, Concat, [1]] # cat head P5
- [-1, 2, DSC3k2, [1024,True]] # 30 (P5/32-large)
- [[-1, 11], 1, FullPAD_Tunnel, []]
- [[23, 27, 31], 1, Detect, [nc]] # Detect(P3, P4, P5)超图自适应相关性增强机制 HyperACE
class HyperACE(nn.Module):
"""
Hypergraph-based Adaptive Correlation Enhancement (HyperACE).
This is the core module of YOLOv13, designed to model both global high-order correlations and
local low-order correlations. It first fuses multi-scale features, then processes them through parallel
branches: two C3AH branches for high-order modeling and a lightweight DSConv-based branch for
low-order feature extraction.
Attributes:
c1 (int): Number of input channels for the fuse module.
c2 (int): Number of output channels for the entire block.
n (int, optional): Number of blocks in the low-order branch. Defaults to 1.
num_hyperedges (int, optional): Number of hyperedges for the C3AH branches. Defaults to 8.
dsc3k (bool, optional): If True, use DSC3k in the low-order branch; otherwise, use DSBottleneck. Defaults to True.
shortcut (bool, optional): Whether to use shortcuts in the low-order branch. Defaults to False.
e1 (float, optional): Expansion ratio for the main hidden channels. Defaults to 0.5.
e2 (float, optional): Expansion ratio within the C3AH branches. Defaults to 1.
context (str, optional): Context type for C3AH branches. Defaults to "both".
channel_adjust (bool, optional): Passed to FuseModule for channel configuration. Defaults to True.
Methods:
forward: Performs a forward pass through the HyperACE module.
Examples:
>>> import torch
>>> model = HyperACE(c1=64, c2=256, n=1, num_hyperedges=8)
>>> x_list = [torch.randn(2, 64, 64, 64), torch.randn(2, 64, 32, 32), torch.randn(2, 64, 16, 16)]
>>> output = model(x_list)
>>> print(output.shape)
torch.Size([2, 256, 32, 32])
"""
def __init__(self, c1, c2, n=1, num_hyperedges=8, dsc3k=True, shortcut=False, e1=0.5, e2=1, context="both", channel_adjust=True):
super().__init__()
self.c = int(c2 * e1)
self.cv1 = Conv(c1, 3 * self.c, 1, 1)
self.cv2 = Conv((4 + n) * self.c, c2, 1)
self.m = nn.ModuleList(
DSC3k(self.c, self.c, 2, shortcut, k1=3, k2=7) if dsc3k else DSBottleneck(self.c, self.c, shortcut=shortcut) for _ in range(n)
)
self.fuse = FuseModule(c1, channel_adjust)
self.branch1 = C3AH(self.c, self.c, e2, num_hyperedges, context)
self.branch2 = C3AH(self.c, self.c, e2, num_hyperedges, context)
def forward(self, X):
x = self.fuse(X)
y = list(self.cv1(x).chunk(3, 1))
out1 = self.branch1(y[1])
out2 = self.branch2(y[1])
y.extend(m(y[-1]) for m in self.m)
y[1] = out1
y.append(out2)
return self.cv2(torch.cat(y, 1))代码位置ultralytics/nn/modules/block.py
全流程聚合 - 分发范式 FullPAD
添加图片注释,不超过 140 字(可选)
class FullPAD_Tunnel(nn.Module):
"""
A gated fusion module for the Full-Pipeline Aggregation-and-Distribution (FullPAD) paradigm.
This module implements a gated residual connection used to fuse features. It takes two inputs: the original
feature map and a correlation-enhanced feature map. It then computes `output = original + gate * enhanced`,
where `gate` is a learnable scalar parameter that adaptively balances the contribution of the enhanced features.
Methods:
forward: Performs the gated fusion of two input feature maps.
Examples:
>>> import torch
>>> model = FullPAD_Tunnel()
>>> original_feature = torch.randn(2, 64, 32, 32)
>>> enhanced_feature = torch.randn(2, 64, 32, 32)
>>> output = model([original_feature, enhanced_feature])
>>> print(output.shape)
torch.Size([2, 64, 32, 32])
"""
def __init__(self):
super().__init__()
self.gate = nn.Parameter(torch.tensor(0.0))
def forward(self, x):
out = x[0] + self.gate * x[1]
return out代码位置ultralytics/nn/modules/block.py
基于深度可分离卷积的轻量化模块
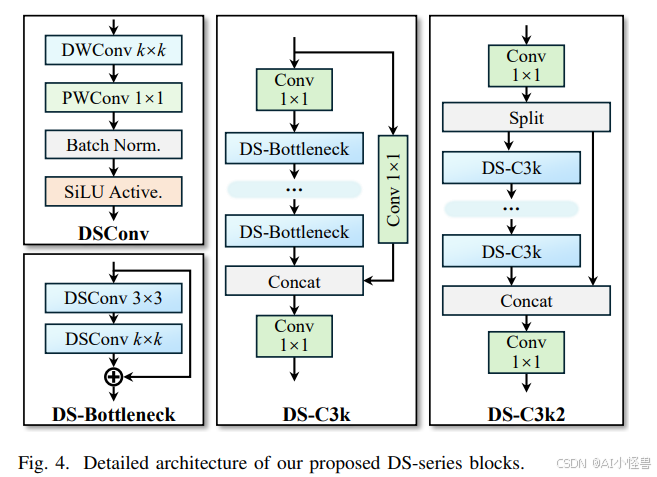
class DSC3k2(C2f):
"""
An improved C3k2 module that uses lightweight depthwise separable convolution blocks.
This class redesigns C3k2 module, replacing its internal processing blocks with either DSBottleneck
or DSC3k modules.
Attributes:
c1 (int): Number of input channels.
c2 (int): Number of output channels.
n (int, optional): Number of internal processing blocks to stack. Defaults to 1.
dsc3k (bool, optional): If True, use DSC3k as the internal block. If False, use DSBottleneck. Defaults to False.
e (float, optional): Expansion ratio for the C2f module's hidden channels. Defaults to 0.5.
g (int, optional): Number of groups for grouped convolution (passed to parent C2f). Defaults to 1.
shortcut (bool, optional): Whether to use shortcut connections in the internal blocks. Defaults to True.
k1 (int, optional): Kernel size for the first DSConv in internal blocks. Defaults to 3.
k2 (int, optional): Kernel size for the second DSConv in internal blocks. Defaults to 7.
d2 (int, optional): Dilation for the second DSConv in internal blocks. Defaults to 1.
Methods:
forward: Performs a forward pass through the DSC3k2 module (inherited from C2f).
Examples:
>>> import torch
>>> # Using DSBottleneck as internal block
>>> model1 = DSC3k2(c1=64, c2=64, n=2, dsc3k=False)
>>> x = torch.randn(2, 64, 128, 128)
>>> output1 = model1(x)
>>> print(f"With DSBottleneck: {output1.shape}")
With DSBottleneck: torch.Size([2, 64, 128, 128])
>>> # Using DSC3k as internal block
>>> model2 = DSC3k2(c1=64, c2=64, n=1, dsc3k=True)
>>> output2 = model2(x)
>>> print(f"With DSC3k: {output2.shape}")
With DSC3k: torch.Size([2, 64, 128, 128])
"""
def __init__(
self,
c1,
c2,
n=1,
dsc3k=False,
e=0.5,
g=1,
shortcut=True,
k1=3,
k2=7,
d2=1
):
super().__init__(c1, c2, n, shortcut, g, e)
if dsc3k:
self.m = nn.ModuleList(
DSC3k(
self.c, self.c,
n=2,
shortcut=shortcut,
g=g,
e=1.0,
k1=k1,
k2=k2,
d2=d2
)
for _ in range(n)
)
else:
self.m = nn.ModuleList(
DSBottleneck(
self.c, self.c,
shortcut=shortcut,
e=1.0,
k1=k1,
k2=k2,
d2=d2
)
for _ in range(n)
)代码位置ultralytics/nn/modules/block.py
链接:https://github.com/iMoonLab/yolov13
环境配置
wget https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.3/flash_attn-2.7.3+cu11torch2.2cxx11abiFALSE-cp311-cp311-linux_x86_64.whl
conda create -n yolov13 python=3.11
conda activate yolov13
pip install -r requirements.txt
pip install -e .如何训练
from ultralytics import YOLO
model = YOLO('yolov13n.yaml')
# Train the model
results = model.train(
data='coco.yaml',
epochs=600,
batch=256,
imgsz=640,
scale=0.5, # S:0.9; L:0.9; X:0.9
mosaic=1.0,
mixup=0.0, # S:0.05; L:0.15; X:0.2
copy_paste=0.1, # S:0.15; L:0.5; X:0.6
device="0,1,2,3",
)
# Evaluate model performance on the validation set
metrics = model.val('coco.yaml')
# Perform object detection on an image
results = model("path/to/your/image.jpg")
results[0].show()如何验证
from ultralytics import YOLO
model = YOLO('yolov13{n/s/l/x}.pt') # Replace with the desired model scale

