产品中心
现代智能体(Agent)——从无人机、机器人,到自主驾驶系统和工业机器人——其智能能力越来越依赖于多种传感器的联合感知:
摄像头 / 多目视觉
激光雷达
毫米波雷达
IMU
温湿度、压力、触觉传感器
网络侧传感器(V2X、IoT)
这些传感器各有优势,但也各有不一致性与噪声源。智能体如果不能将它们进行有效融合,就无法在复杂环境中保持稳定表现。
在我过去参与机器人落地项目的经验中,多源传感器之间的时钟漂移、采样频率不同、物理安装偏移以及噪声差异,几乎是所有新团队都会踩的坑。而真正的难点不在于“读数据”,而在于:
如何让多源异构数据在时间、空间、语义维度上实现对齐?
为此,我们需要一套系统的数据融合技术栈。
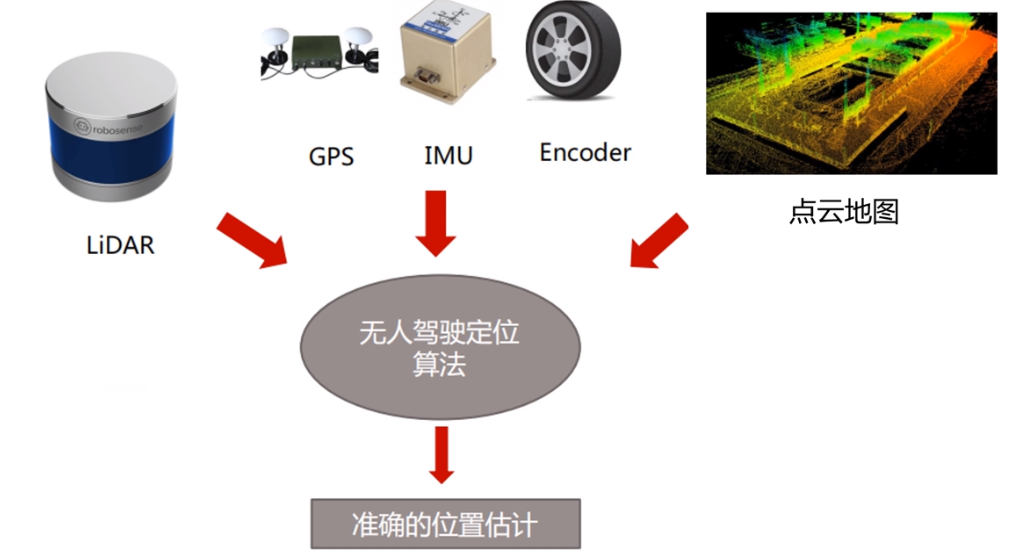
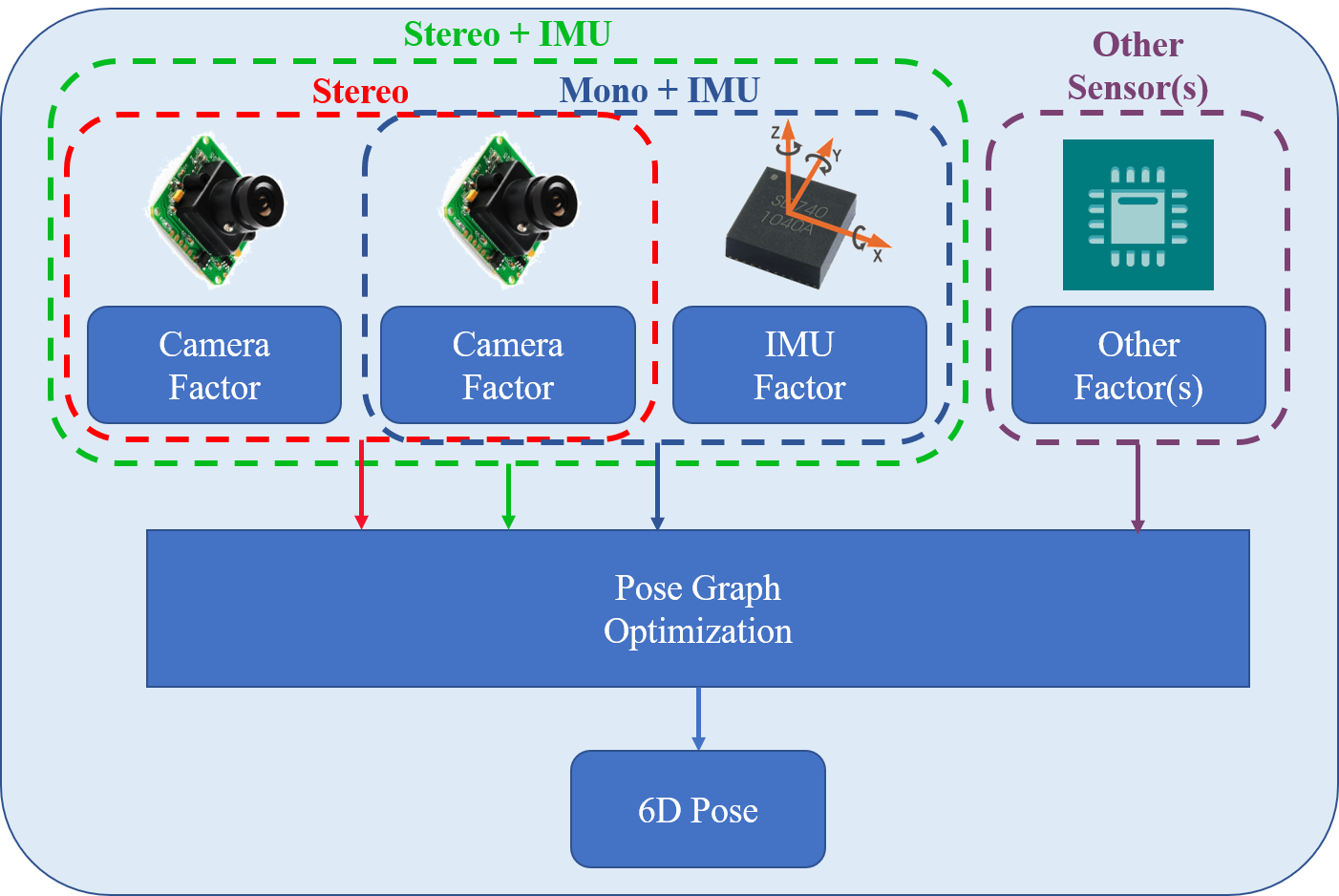
现实系统中,不同传感器很少能做到真正同步。典型问题包括:
摄像头 30FPS vs 激光雷达 10Hz
ROS 下不同设备的 timestamp 精度不统一
设备时钟偏移(drift)导致 1 小时后可产生 >100ms 偏差
一个实战经验是:不要信任传感器内部时间戳,尽可能使用系统同步时间。
每个传感器的安装位置不同,必须通过标定得到坐标变换关系(extrinsic)。
常见困难:
相机标定不准 → 视觉与雷达无法对齐
IMU 偏置未校准 → 位姿漂移
车辆底盘坐标系与传感器坐标系不一致
标定的误差往往比算法本身更致命。
例如:
LiDAR 给你点云
摄像头给你像素
IMU 给你加速度 & 角速度
毫米波雷达给你距速
V2X 给你结构化信息
如何从中统一抽象出可融合的信息实体是真正考验工程能力的地方。
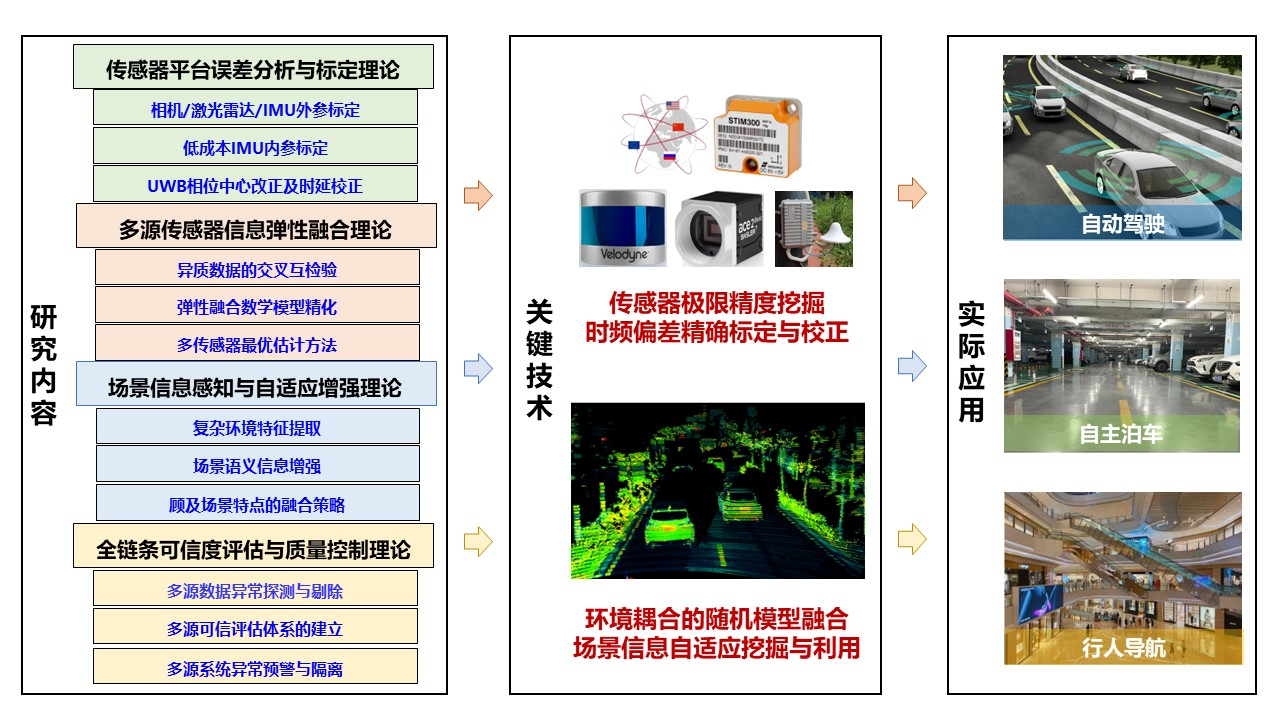
我通常将时空对齐拆成三个步骤:时间校准 → 坐标变换 → 轨迹/语义对齐。
常见处理方式:
适用于连续传感器(如 IMU、轮速计)
def interpolate_by_timestamp(data, new_timestamps):
# data: [(t, value)]
result = []
for t in new_t in new_timestamps:
# 找到 t 左右两个采样点
prev, nxt = find_interval(data, t)
ratio = (t - prev.t) / (nxt.t - prev.t)
value = prev.v * (1 - ratio) + nxt.v * ratio
result.append((t, value))
return result
这是工程中最常用的方法,足够轻量,不需要数学模型支撑。
如果传感器间有系统延迟,可以做:
对齐触发事件(trigger timestamp)
基于特征的时间延迟估计
例如,相机拍到激光雷达反射板时,可用事件时间求 delay。
当设备没有硬件同步线时,通常用 VIO 常见的办法:
通过观察相机轨迹和 IMU 积分轨迹匹配来反推时间偏移
实验表明:可校准到 <1ms
这种方法较“工程”,但实战非常有效。

最终目标是将所有传感器转换到一个世界坐标系:
LiDAR → Base → Map
Camera → Base → Map
IMU → Base → Map
以 ROS 为例,通常会维护一套 TF tree。
常用于 VIO 系统:
基于角速度估计相机视野变化
通过优化求解外参(R、T)
工程常用:
用棋盘格 + 点云平面
或使用 targetless 的线/面结构
例如无人车多线束融合,需要同时求解所有 LiDAR 相对位姿,常用 ICP 进行粗对齐 + 优化精对齐。
一般将数据融合分成三层:
Low-level :传感器层融合(滤波、对齐)
Mid-level :特征层融合(点云 + 视觉 + IMU)
High-level :语义/决策层融合(轨迹、检测、地图)
下面给一个最常用的工程融合范式:IMU + Camera 视觉惯性融合(VIO)。
以下代码演示一个工程原型:将 IMU 积分轨迹与视觉估计轨迹融合(并非完整 VIO,但展示流程)。
import numpy as np
def integrate_imu(imu):
pos = np.zeros(3)
vel = np.zeros(3)
R = np.eye(3)
last_t = imu[0]['t']
for m in imu[1:]:
dt = m['t'] - last_t
last_t = m['t']
acc = np.array(m['acc'])
gyro = np.array(m['gyro'])
# 简化积分示例
vel += acc * dt
pos += vel * dt
return pos, vel
def align_visual_imu(visual_track, imu_track):
aligned = []
imu_t = [m['t'] for m in imu_track]
for frame in visual_track:
t = frame['t']
# 找到最接近的 IMU ts
idx = np.argmin(np.abs(np.array(imu_t) - t))
aligned.append({
"t": t,
"visual_pos": frame["pos"],
"imu_pos": imu_track[idx]["pos"]
})
return aligned
def fuse_position(v, i, w_v=0.7, w_i=0.3):
return v * w_v + i * w_i
for pair in aligned_data:
fused = fuse_position(pair["visual_pos"], pair["imu_pos"])
print("t:", pair["t"], "fused_pos:", fused)
虽然这个示例非常简化,但真实工程中的 VIO、SLAM、激光-视觉融合,最终都绕不开时间对齐、坐标变换与特征融合这三个核心步骤。
以下是我真实遇到的经验总结,通常比理论更有实用价值。
很多团队花大量时间在深度模型调优,但系统误差、时间误差才是最要命的问题。
> 真实项目中,数据对齐做好后,效果往往自然就能提升 30% 以上。
融合并不是越复杂越好。
原则:从能贡献信息的传感器开始融合,而不是所有传感器全堆上。
尤其是相机外参,一旦偏差超过 2°,系统性能立刻崩溃。
我曾见过某无人车团队因为相机外参固定螺丝松动,整个感知模块每天都“人格分裂”。
不要使用纯仿真数据来调融合算法。
真实传感器的噪声是非高斯、非稳定的,远比工程师想象中“脏得多”。

智能体的数据融合,是建构“世界模型”的第一步,也是最容易被忽略的底层基础。
这套技术体系本质上解决三个问题:
时间对齐:让所有数据在同一时间线上
空间统一:让所有数据进入同一坐标系
语义融合:让多源信息共同描述同一世界
未来,随着具身智能体的发展,多模态融合将变得更加关键——不仅融合传感器,还要融合大模型的语义理解,真正让系统做到“可解释、可推理”。
如果你正在做机器人、无人机、自主驾驶、工业智能体,以上方法几乎一定能帮你避开常见陷阱。