

产品中心
大家好,我是 Ai 学习的老章
本文一起学习一下大模型中经常看到的一个参数——Temperature
Temperature: 用于调整随机从生成模型中抽样的程度,因此每次“生成”时,相同的提示可能会产生不同的输出。温度为 0 将始终产生相同的输出。温度越高随机性越大!主要用于控制创造力。
大模型中的 temperature 参数用于控制模型输出的随机性和创造性。
较高的 temperature 值会增加输出的随机性,产生更多样化的结果,但也可能降低预测准确性。
较低的 temperature 值则会使输出更确定、更保守,更倾向于产生重复和更可预测的输出。
设置 temperature 时需要在随机性和准确性之间找到平衡。在测试大模型时,可以通过改变 temperature 的值来评估模型在不同情境下的表现,比如在创意生成、代码编写等任务中,观察其生成结果的变化。
除了 Temperature 这个最常被讨论的参数,我们还会经常看到以下参数:
top_p :限制被考虑的标记范围。若设为 0.5,则仅考虑累计概率不超过 50% 的最高概率标记。top_k :同样限制被考虑的标记,仅考虑概率最高的前 k 个标记。frequency_penalty : 根据生成文本中新词出现的频率对其进行惩罚。可设置为负值以鼓励重复。presence_penalty : 若新词已出现在已生成文本中,则对其进行惩罚。可设置为负值以鼓励重复。repetition_penalty : 该参数被记录为根据新词是否已在生成文本或提示中出现过而进行惩罚的参数。开源权重与开源数据集的模型[1]
模型名称 | temperature | top_p | top_k | 备注 |
|---|---|---|---|---|
deepseek-ai/DeepSeek-V3-0324 | 0.3 | 无 | 无 | 官方推荐 0.3,但部分基准测试使用 0.7。 |
deepseek-ai/DeepSeek-R1-0528 | 0.6 | 0.95 | 无 | 模型卡和论文均推荐此配置。 |
microsoft/phi-4 | 无 (报告用 0.5) | 无 | 无 | 官方无推荐,但技术报告多用 temperature=0.5。 |
microsoft/Phi-4-reasoning | 0.8 | 0.95 | 50 | 模型卡明确指定所有参数。 |
mistralai/Mistral-Small-3.2-24B-Instruct-2506 | 0.15 | 无 | 无 | API 返回的旧版默认值与模型卡不符。 |
mistralai/Devstral-Small-2505 | 不明确 (示例用 0.15) | 无 | 无 | 示例代码用 0.15,但 API 默认值为 0.0。 |
mistralai/Magistral-Small-2506 | 0.7 | 0.95 | 无 | 模型卡明确推荐,与 API 默认值一致。 |
qwen3 系列 | 思考: 0.6非思考: 0.7 | 思考: 0.95非思考: 0.8 | 20 | 官方为不同模式提供明确参数建议。 |
THUDM/GLM-Z1-32B-0414 | 0.6 | 0.95 | 40 | 模型卡明确指定所有参数。 |
模型名称 | temperature | top_p | top_k | 备注 |
|---|---|---|---|---|
google/gemma-3-27b-it | 1.0 | 0.96 | 64 | 参数来自非官方确认,但已写入配置文件。 |
meta-llama/Llama-4-Scout-17B-16E-Instruct | 0.6 | 0.9 | 无 | 参数来自配置文件,模型卡未提及。 |
关键结论与建议

The Effect of Sampling Temperature on Problem Solving in Large Language Models[2],这篇论文主要探讨了采样温度对大型语言模型(LLMs)解决问题能力的影响,具体内容如下:
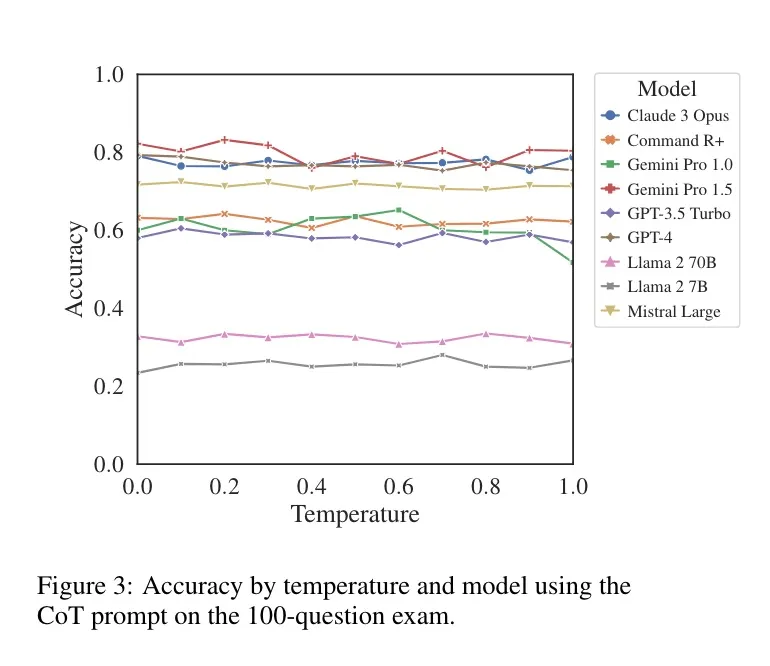
Is Temperature the Creativity Parameter of Large Language Models?[3],这篇论文发现:
这篇论文:Exploring the Impact of Temperature on Large Language Models:Hot or Cold?[4],系统研究了大语言模型中temperature 参数(0-4.0 范围)对六种核心能力(因果推理、创造力、上下文学习、指令遵循、机器翻译、摘要生成)的影响,发现其对不同能力和模型规模(小 1B-4B、中 6B-13B、大 40B-80B)的影响差异显著:小模型对温度更敏感,高温易导致性能骤降;大模型在高温下更稳健。例如,机器翻译在小模型中性能波动可达 192.32%,而大模型仅 76.86%。研究提出基于 BERT 的温度选择器,在 SuperGLUE 数据集上显著提升中小模型性能,并验证了 FP16 与 4-bit 量化下温度效应的一致性。
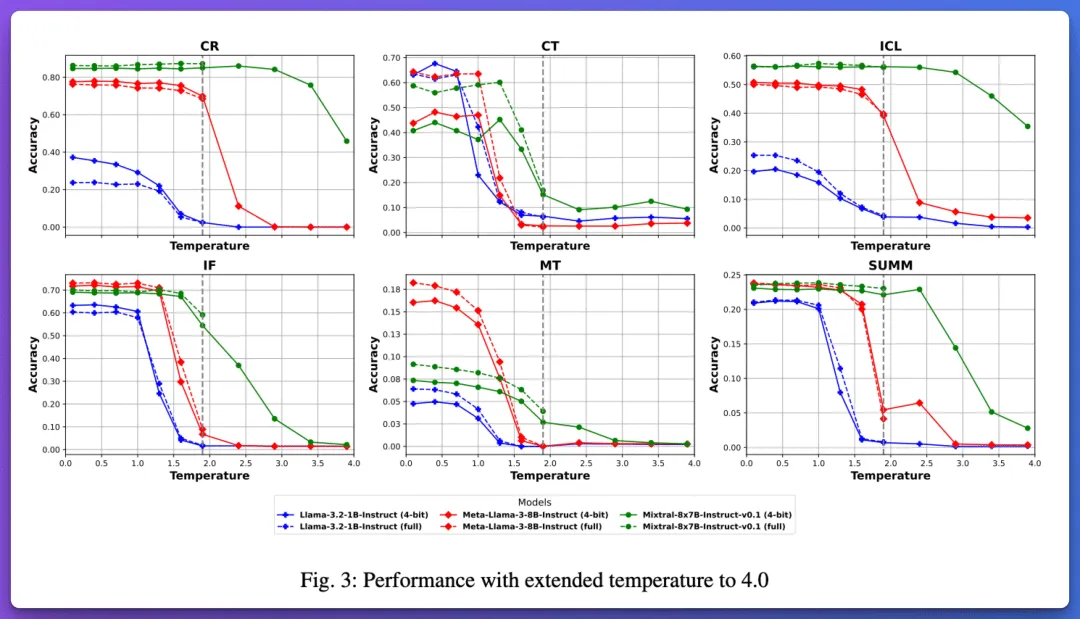
核心结果:
参考资料
[1]
开源权重与开源数据集的模型: https://muxup.com/2025q2/recommended-llm-parameter-quick-reference
[2]
The Effect of Sampling Temperature on Problem Solving in Large Language Models: https://arxiv.org/pdf/2402.05201
[3]
Is Temperature the Creativity Parameter of Large Language Models?: https://arxiv.org/pdf/2405.00492
[4]
Exploring the Impact of Temperature on Large Language Models:Hot or Cold?: https://www.themoonlight.io/file?url=https%3A%2F%2Farxiv.org%2Fpdf%2F2506.07295


