

产品中心
【导读】
2025年已过半,AI领域依旧风起云涌。就在大家还在研究多模态和大模型融合时,YOLOv13 的发布再次把目标检测领域推上热搜,但目标检测,这个曾经被视为CV领域“基础中的基础”,如今也在被频繁问到:“还值得做吗?”但真是这样吗?其实除了 YOLO,还有 DETR、RT-DETR、DINO、Grounding DINO 等一批极具潜力的新模型正悄悄发力。今天我们就来聊聊 2025 年还能不能做目标检测,顺便盘一盘那些你可能还没关注的新方向。
先说最近热度最高的 YOLOv13。作为目标检测界的“王者系列”,YOLO 的每一次更新都牵动着开发者神经。
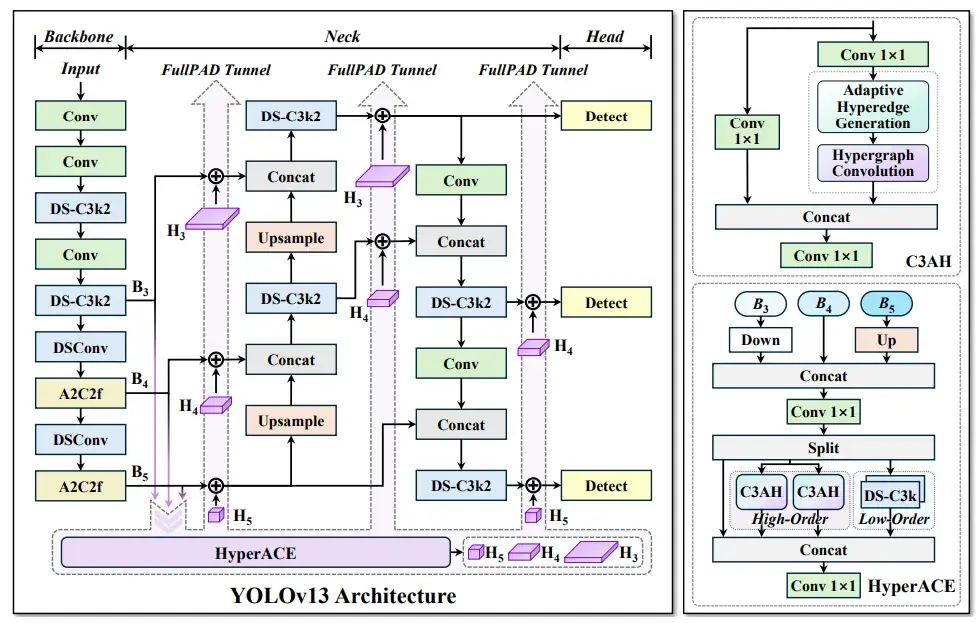
引入 Flash Attention,提高推理效率,特别适配显存紧张场景
但问题在于:YOLO 系列已经被研究得非常透彻,不管是结构、训练技巧还是优化策略,都有海量论文/教程覆盖,“从中做创新”的空间越来越小。
YOLO 代表的是经典CNN检测范式,而 DETR(Detection Transformer) 则是另一个流派——以 Transformer 架构为核心,彻底改变了检测逻辑。
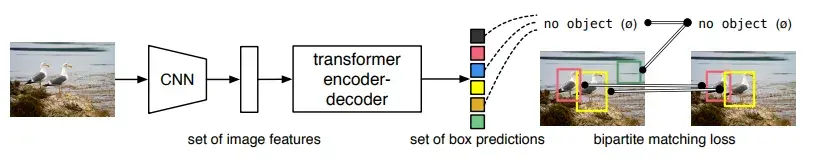
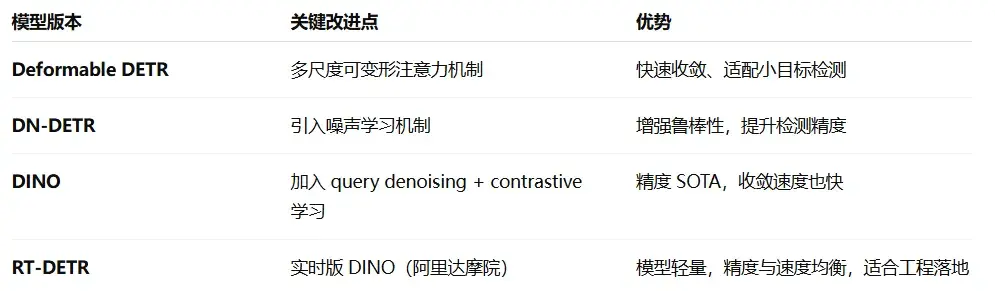
不过最初的 DETR 训练慢、收敛慢,实际应用受限。于是很多增强版相继诞生:
目标检测的新趋势之一,就是从“纯视觉”向“多模态”迈进。Grounding DINO 就是这个趋势下的明星模型。
它的最大亮点是:图文联合检测能力。

你可以输入一句话:“图中有黄色卡车”,它就能从图片中标出黄色卡车,而不是只识别固定类别。
如果你正在探索多模态、Agent、LLM 视觉插件等方向,Grounding DINO 是非常值得深入研究的目标检测模型。
除了 YOLO 和 DETR,还有一些模型可能没那么“出圈”,但在实际应用中非常靠谱:
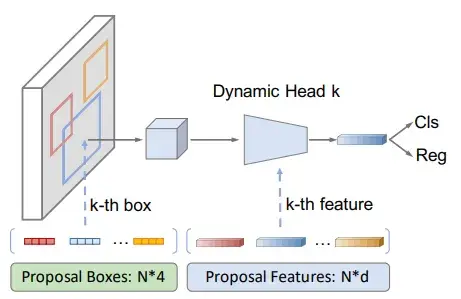
核心思想:用固定数量的可学习 proposal boxes(而不是密集滑窗)来进行目标预测,从而大幅减少计算开销。
简单说,它让检测变得“更聪明”:不是全图密集搜索,而是用少量“聪明提问”找到目标。
主要特性:
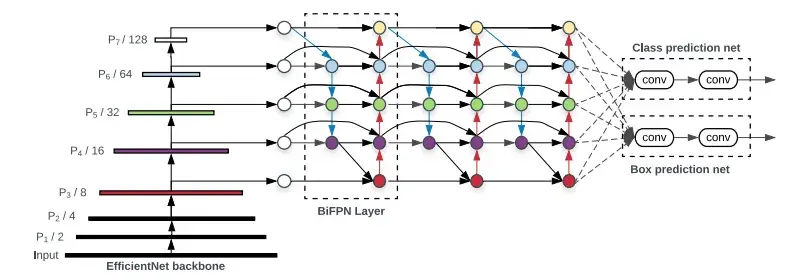
核心思想:通过高效的 BiFPN(双向特征金字塔网络)结构 + 统一的复合缩放方法,实现模型大小与性能的平衡。
EfficientDet = 高效特征提取器 + 灵活伸缩的骨干网络,适合不同硬件部署。
主要特性:
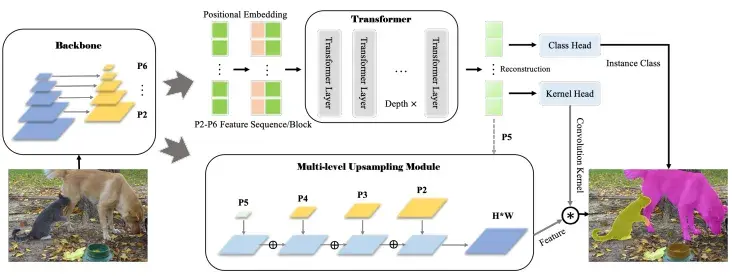
核心思想:将目标检测与实例分割统一在一个 Transformer 框架下,消除两阶段带来的误差累积。
不再先框目标再掩码分割,而是直接用 Transformer 建立 instance 级表示。
主要特性:
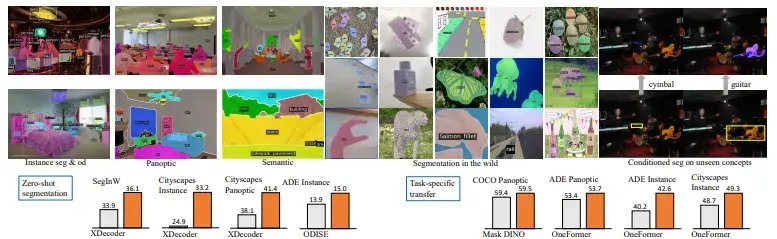
核心思想:将目标检测任务接口化,与大型语言模型(如 GPT、LLaVA)进行协作;支持 Zero-shot/Multimodal/Prompt-based 检测。
检测任务不再是分类框,而是“感知+语言”的交互过程。
OpenSeeD(Open-Vocabulary Scene DEtection):
UniDet:
很多人觉得目标检测“做不动了”,本质上是因为:
但我们必须看到的是:
目标检测正在向以下方向进化:
2025 年,目标检测依然是计算机视觉中最实用的任务之一。从自动驾驶、工业质检到医疗成像、安全安防,目标检测是很多 AI 应用系统的“感知核心”。
但如果你还在沿用 YOLOv5 + COCO 数据集写代码,那确实会感到“没啥好做”。
只有跳出传统,拥抱多模态、大模型、低资源、实际场景应用,目标检测才会焕发新生。


