

产品中心
癌症基因组图谱计划(The Cancer Genome Atlas , TCGA),对超过 20,000 份涵盖 33 种癌症类型(https://www.cancer.gov/ccg/research/genome-sequencing/tcga/studied-cancers)的原发癌及配对正常样本进行了分子特征分析。,是一个由美国国家癌症研究所(NCI)和国家人类基因组研究所(NHGRI)联合发起的大规模研究项目。TCGA的主要目标是通过全面分析不同类型癌症的基因组变化,来提高对癌症的理解并推动诊断、治疗和预防的进步。TCGA现在的数据均收录在 GDC (Genomic Data Commons) 中,可以通过网页 GDC Data Portal (https://portal.gdc.cancer.gov/)获得TCGA数据。
TCGAbiolinks (https://gdc.cancer.gov/content/tcgabiolinks) 能够通过其 GDC 应用程序编程接口(API)访问美国国家癌症研究所(NCI)的基因组数据共享平台(GDC),以搜索、下载并准备相关数据用于 R 语言分析。
if (!requireNamespace("BiocManager", quietly=TRUE))
install.packages("BiocManager")
BiocManager::install("TCGAbiolinks")
比如:搜索复发性多形性胶质母细胞瘤(GBM)和低级别胶质瘤(LGG)样本的所有 DNA 甲基化数据。
query <- GDCquery(
project = c("TCGA-GBM", "TCGA-LGG"),
data.category = "DNA Methylation",
platform = c("Illumina Human Methylation 450"),
sample.type = "Recurrent Tumor"
)
可以看到变量query打开是一个嵌套数据框,第一列是我们的查询结果,打开后是我们查询的样本信息,每一行是一个数据。其余列是我们的筛选参数,筛选参数有 9 个。


GDC 数据库中目前除了 TCGA 数据外,还有一些其他平台的数据,我们可以直接查看 GDC 数据库中有哪些 project.
library(tidyverse)
library(TCGAbiolinks)
# 查看 GDC 平台有哪些 project
TCGAbiolinks:::getGDCprojects() %>% view()
可以看到一共有 86 个 project。
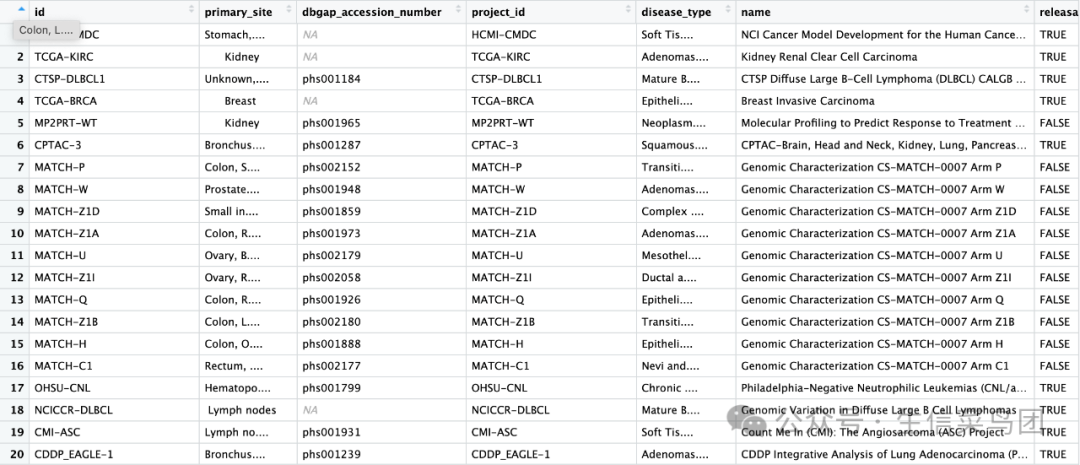
# 查看关注 project 有哪些 data.category
> project <- "TCGA-CHOL"
> TCGAbiolinks:::getProjectSummary(project)
$file_count
[1] 3028
$data_categories
file_count case_count data_category
1 981 51 Simple Nucleotide Variation
2 395 51 Sequencing Reads
3 222 51 Biospecimen
4 116 51 Clinical
5 617 51 Copy Number Variation
6 178 36 Transcriptome Profiling
7 135 36 DNA Methylation
8 30 30 Proteome Profiling
9 156 47 Somatic Structural Variation
10 198 41 Structural Variation
$case_count
[1] 51
$file_size
[1] 2.451147e+13
用于筛选待下载文件的数据类型
按访问权限类型筛选。可选值:受控(controlled)、开放(open).
按实验策略筛选。标准化数据包括:全外显子测序(WXS)、RNA 测序(RNA-Seq)、miRNA 测序(miRNA-Seq)、基因分型阵列(Genotyping Array)。
数据平台
有tissue.code, shortLetterCode, tissue.definition三种表示方式。
tissue.definition举例:
代表参与者及其样本的元数据。TCGA 每一个患者(case)均有一套标准的命名方式(https://docs.gdc.cancer.gov/Encyclopedia/pages/TCGA_Barcode/)。详细编码对照表报告在(https://gdc.cancer.gov/resources-tcga-users/tcga-code-tables)。
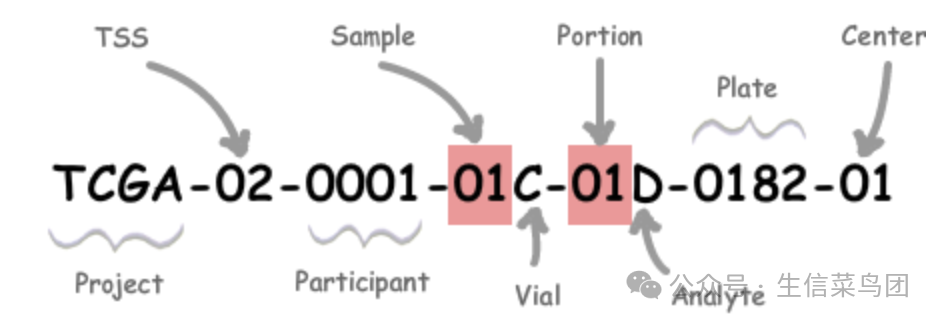
标签 | 标识符 | 值 | 值描述 | 可能的值 |
|---|---|---|---|---|
Project | 项目名称 | TCGA | TCGA项目 | TCGA |
TSS | 组织来源地 | 02 | 来自MD Anderson的GBM(脑肿瘤)样本 | |
Participant | 研究参与者 | 0001 | MD Anderson的GBM研究的第一位参与者 | 任意字母数字值 |
Sample | 样本类型 | 01 | 实体肿瘤 | 肿瘤类型范围从01-09,正常类型从10-19,控制样本从20-29。完整的样本代码参见代码表报告 |
Vial | 样本序列中的样本顺序 | C | 第三个小瓶 | A到Z |
Portion | 100-120毫克样本部分序列中的部分顺序 | 01 | 样本的第一部分 | 01-99 |
Analyte | 用于分析的分子类型 | D | 分析物是DNA样本 | |
Plate | 96孔板序列中的板顺序 | 0182 | 第182块板 | 4位字母数字值 |
Center | 接收分析样品的测序或表征中心 | 01 | Broad Institute GCC |
搜索所有结肠腺癌(TCGA-COAD)肿瘤患者中同时拥有 DNA 甲基化(HumanMethylation450k 平台)和基因表达数据的样本。
# 查询 DNA 甲基化数据
query_met <- GDCquery(
project = "TCGA-COAD",
data.category = "DNA Methylation",
platform = c("Illumina Human Methylation 450")
)
# 查询基因表达数据
query_exp <- GDCquery(
project = "TCGA-COAD",
data.category = "Transcriptome Profiling",
data.type = "Gene Expression Quantification",
workflow.type = "STAR - Counts"
)
# 获取所有具有 DNA 甲基化和基因表达的患者。
common.patients <- intersect(
substr(getResults(query_met, cols = "cases"), 1, 12),
substr(getResults(query_exp, cols = "cases"), 1, 12)
)
# 仅选择前 5 名患者信息
query_met <- GDCquery(
project = "TCGA-COAD",
data.category = "DNA Methylation",
platform = c("Illumina Human Methylation 450"),
barcode = common.patients[1:5]
)
# 仅选择前 5 名患者信息
query_exp <- GDCquery(
project = "TCGA-COAD",
data.category = "Transcriptome Profiling",
data.type = "Gene Expression Quantification",
workflow.type = "STAR - Counts",
barcode = common.patients[1:5]
)
搜索乳腺癌原始测序数据(“受控”)。
query <- GDCquery(
project = "TCGA-ACC",
data.category = "Sequencing Reads",
data.type = "Aligned Reads",
data.format = "bam",
workflow.type = "STAR 2-Pass Transcriptome"
)
query <- GDCquery(
project = "TCGA-ACC",
data.category = "Sequencing Reads",
data.type = "Aligned Reads",
data.format = "bam",
workflow.type = "STAR 2-Pass Genome"
)
TCGAbiolinks 提供了一些功能来从 GDC 下载并准备数据以供分析。主要通过两个函数实现。
GDCdownload 参数
传递给*GDCquery*函数的查询对象,用于指定要下载的数据集。GDCquery函数定义要下载的数据集,然后使用GDCdownload*来实际下载这些数据。GDCquery*生成,包含项目、数据类型和其他过滤条件。GDCprepare 参数
传递给*GDCquery*函数的查询对象,用于指定要准备的数据集。使用 TCGAbiolinks 下载 GDC 数据有两种方法:
client :此方法会生成一个 MANIFEST 文件,并通过 GDC 数据传输工具下载数据,该方法更为可靠,但相比 API 方法可能速度较慢。api :此方法利用 GDC 应用程序编程接口(API)下载数据。将生成一个 MANIFEST 文件,且下载的数据会被压缩为 tar.gz 格式。若文件数量和体积过大,可能导致压缩包过大,增加下载失败的概率。为此,我们引入了 files.per.chunk 参数,将文件分割为小块。例如,若 chunks.per.download 设为 10,则每个 tar.gz 内仅包含 10 个文件。SummarizedExperiment 对象包含三个可通过 SummarizedExperiment 包访问的主要矩阵:
colData(data) 访问:存储样本信息。TCGAbiolinks 会添加来自 TCGA 标志性论文的索引临床数据和亚型信息。assay(data) 访问:存储分子数据rowRanges(data) 访问:存储特征的元数据,包括其基因组范围。使用函数 GDCprepare 时,有一个名为 SummarizedExperiment 的参数,用于定义输出类型为 Summarized Experiment(默认选项)或数据框。要创建 Summarized Experiment 对象,使用基因组最新补丁版本的基因组位置对数据进行注释。此外,最新的 DNA 甲基化元数据可在以下网址获取:http://zwdzwd.github.io/InfiniumAnnotation
从数据库中搜索并下载两个样本数据
# Gene expression aligned against hg38
query <- GDCquery(
project = "TCGA-GBM",
data.category = "Transcriptome Profiling",
data.type = "Gene Expression Quantification",
workflow.type = "STAR - Counts",
barcode = c("TCGA-14-0736-02A-01R-2005-01", "TCGA-06-0211-02A-02R-2005-01")
)
GDCdownload(query = query)
data <- GDCprepare(query = query)
样本基因表达定量下载
query.exp.hg38 <- GDCquery(
project = "TCGA-GBM",
data.category = "Transcriptome Profiling",
data.type = "Gene Expression Quantification",
workflow.type = "STAR - Counts",
barcode = c("TCGA-14-0736-02A-01R-2005-01", "TCGA-06-0211-02A-02R-2005-01")
)
GDCdownload(query.exp.hg38)
expdat <- GDCprepare(
query = query.exp.hg38,
save = TRUE,
save.filename = "exp.rda"
)
最好的教程是官网:https://bioconductor.org/packages/devel/bioc/vignettes/TCGAbiolinks/inst/doc/index.html


