

产品中心

本篇文章深入分析了大模型微调的底层逻辑与关键技术,细致介绍了包括全参数微调(Full Parameter Fine Tuning)、LoRA、QLoRA、适配器调整(Adapter Tuning)与提示调整(Prompt Tuning)在内的5种主流方法。文章将详细讨论每种策略的核心原理、优势劣势与最佳适用场景,旨在帮助您依据计算资源与数据规模与性能要求与部署成本,在面对如何为您的特定任务从众多微调方案中选择最高效、最经济的技术路径时,做出最明智的决策。
在探索具体方法之前,我们首先需要建立一个清晰的认知框架,理解大模型微调在整个AI模型生命周期中所扮演的角色。我们可以将大模型的诞生与成长简化为两个关键阶段:
此阶段如同为模型进行一次“通识教育”,它通过在浩瀚无垠的互联网文本上进行自监督学习,从而掌握语言的语法结构、基本常识与逻辑推理能力。这个过程产出的是一个能力广泛的基座模型,例如LLaMA或ChatGLM,它如同一位学识渊博的“通才”,但其知识尚未针对任何特定任务进行打磨。
在预训练之后,微调阶段则承担了“专业培养”的职责。它使用高质量、小规模、有标注的特定领域数据集,对基座模型进行针对性的再训练。此过程旨在让模型适应具体的任务要求或学会遵循人类的指令风格,其产出物是精通某一领域的专家模型,例如专攻法律咨询、医疗问答或遵循人类指令的对话助手,从而完成从“通才”到“专才”的关键转变。
直观上,大模型微调即是指通过输入特定领域或任务的数据,并有选择性地调整模型参数的技术过程。其根本目的,是为了优化模型在特定功能上的性能,使其行为与输出能完美地适应真实的业务场景与用户需求。例如,我们可以将一个通用的中文基座模型,通过在高质量的法律条文和案例数据集上进行微调,使其化身为一个能够精准回答法律问题、分析案件的法律助手。这个过程,就是大模型微调价值的直接体现。
微调的重要性在于它能够“激活”基座模型的潜在能力,为其“装备”上精细化、专业化的功能。没有微调,大模型就像一件未开刃的神兵,空有材质而缺乏锋芒。以 ChatGPT 的诞生为例。其强大的对话能力并非仅仅源于预训练,更关键的是通过后续的指令微调,才学会了理解并遵从人类复杂的指令意图。我们可以用一个贴切的类比来理解:预训练好的基座模型好比一个功能强大的操作系统(如Windows),它本身具备通用能力,而微调则像是为这个系统安装专业的软件插件(如Photoshop用于图像处理,CAD用于工程设计)。通过加载特定的“功能模块”,在不改变系统核心的前提下,实现了对特定任务的深度支持与灵活适配,这正是其价值的核心所在。
要深入理解各类微调方法的工作原理,我们首先需要深入审视其赖以生存的土壤——Transformer架构。我们所讨论的5种微调方法,本质上都是对这个基础架构中自注意力机制与前馈神经网络等核心组件的参数进行优化的不同策略。理解这些组件的功能,就如同外科医生熟悉人体解剖结构一样,能帮助我们清晰地看到后续的微调方法是如何精准地"动刀"的。
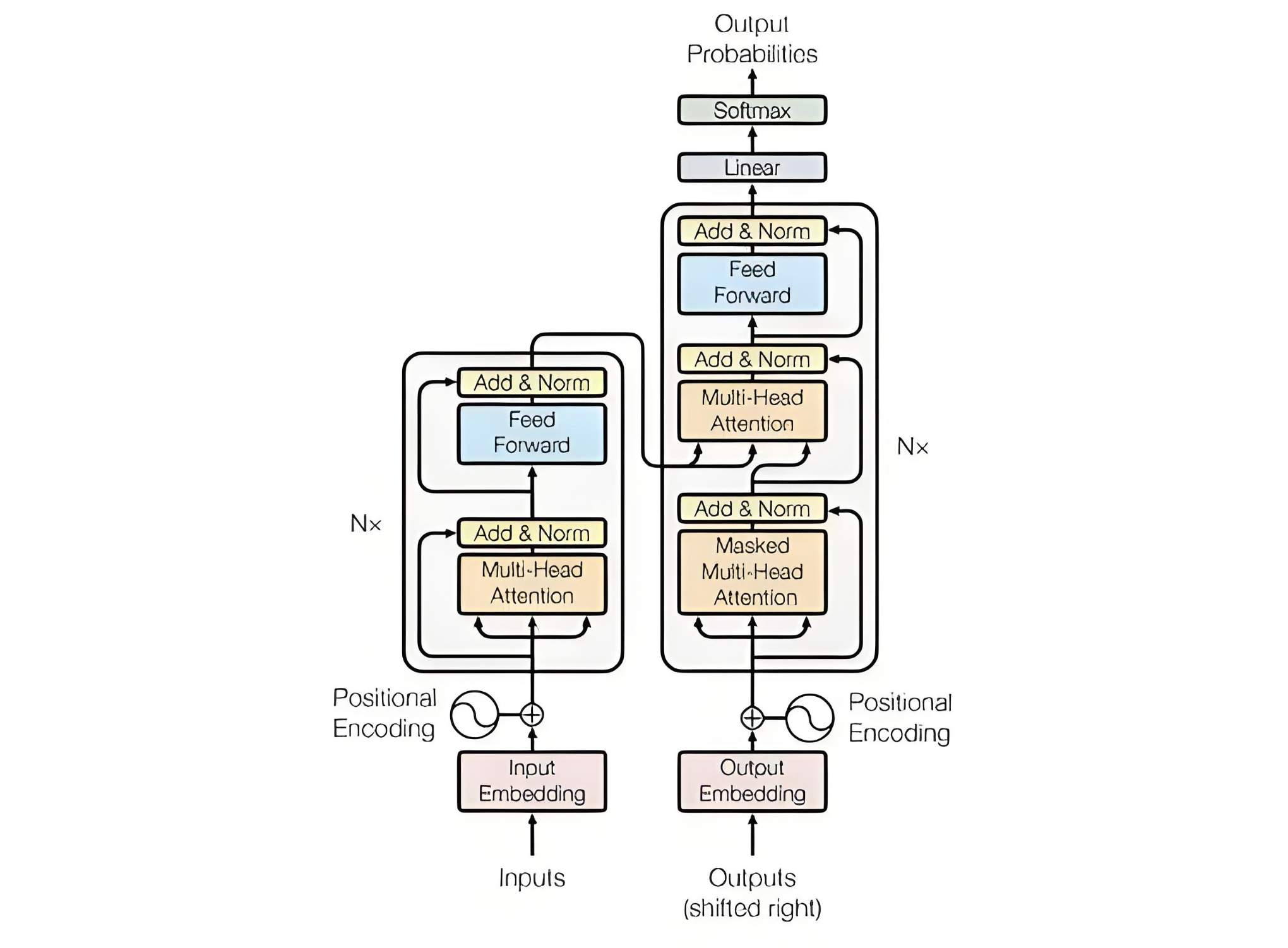
模型的起点是输入嵌入层,它负责将输入的单词或符号序列转化为一串能够表征语义信息的高维向量。由于Transformer的自注意力机制本身不具备序列顺序感知能力,位置编码作为一个独立的模块,其作用是为这些嵌入向量注入每个词的位置信息,确保模型能够理解“我吃鱼”和“鱼吃我”之间的词序差异。
编码器层是Transformer的核心处理单元,通常由N个相同的层堆叠而成。每一层都包含两个关键子层:多头自注意力机制(Multi-Head Attention)和前馈神经网络(Feed Forward),这些子层通过精妙的设计协同工作,逐步提取和精炼输入序列的表示。
多头自注意力机制堪称Transformer架构的灵魂。它通过并行计算多个注意力头,使模型能够同时从不同的表示子空间学习信息。每个注意力头都可以专注于不同类型的依赖关系,有的可能关注语法结构,有的则可能聚焦语义关联,共同构成了丰富的上下文理解能力。
注意力层后面跟着残差连接和层归一化(Add & Norm),有助于防止深层网络中的梯度消失问题,并稳定训练过程。
前馈神经网络作为编码器层的第二个子层,是一个完全连接的网络。它通常包含两个线性变换和一个非线性激活函数,负责对自注意力层的输出进行进一步的特征提取和转换,增强模型的表达能力。
与编码器对应的是解码器,它同样由N个相同层堆叠而成,但结构更为复杂。每个解码器层包含三个子层:掩蔽的多头自注意力机制(Masked Multi-Head Attention)、多头交叉注意力机制和前馈神经网络(Feed Forward)。
首先,掩蔽多头自注意力机制通过掩蔽操作,确保模型在生成当前词时只能看到它之前的词,这是实现顺序生成的关键。
接着,多头交叉注意力层登场,它以解码器上一层的输出作为Query,以编码器的最终输出作为Key和Value,帮助解码器在生成每个词时都能有选择地聚焦于输入序列中最相关的部分。
最后,同样是一个前馈神经网络进行收尾处理。值得注意的是,编码器和解码器中的每一个子层后面,都紧跟着残差连接与层归一化,这一经典设计极大地稳定了深度网络的训练过程。
解码器的最终输出会送入输出层。首先经过一个线性层,其功能是将解码器输出的隐藏状态向量映射到整个词汇表大小的维度上。随后,Softmax函数将这些分数转换为一个清晰的概率分布,模型便根据这个分布来选择最有可能的下一个词,从而生成最终的输出序列。
这个精密的架构是所有现代大模型的蓝图。理解了它,我们就能清晰地看到:全参数微调会更新从嵌入层到输出层的全部参数;而LoRA等方法,则像是针对自注意力等核心“器官”进行的精准、微创手术。
在深入理解Transformer架构之后,我们便可以开始系统地审视在其之上进行"精修"的各种技术手段。本文将重点介绍五种具有代表性的微调方法,它们共同勾勒出从传统到前沿的技术演进脉络。
从宏观层面看,大模型微调方法可分为两大阵营:全面微调(Fine-tuning)和参数高效微调(Parameter-Efficient Fine-Tuning,PEFT)。全面微调旨在更新模型的所有参数,虽能达到极高的性能上限,但计算成本和资源需求巨大。而参数高效微调则通过仅优化模型中的一小部分参数,在保持性能相当的同时,大幅降低了计算开销和存储需求。正是凭借其卓越的效率和可承受的资源消耗,参数高效微调已成为当前学术界与工业界的主流选择。

全参数微调(Full Parameter Fine Tuning)是一种"深度重塑"式的模型优化,通过更新预训练模型的所有参数来适应下游任务。
LoRA(Low-Rank Adaptation)是一种“精准打补丁”式的微调,通过注入可训练的低秩矩阵间接更新权重,而无需改动原始参数。
QLoRA(Quantized Low-Rank Adaptation)是LoRA的“量化增强版”,通过将预训练模型量化为4位精度,进一步压低了微调的内存门槛。
适配器调整(Adapter Tuning)是一种“模块化插件”式的微调,通过在Transformer层中串行插入小型神经网络模块来适应新任务。
提示调整(Prompt Tuning)是一种“润物细无声”的微调,不改变模型自身,而是通过优化输入提示词的嵌入表示来引导模型输出。
在这些方法中,LoRA与适配器调整的对比尤为值得关注。两者的核心区别在于,LoRA侧重于以旁路方式修改现有权重,而适配器调整侧重于插入新的序列化处理模块。前者在推理效率上更具优势(无额外层),后者在多任务学习和管理上更为直观。LoRA更适合追求极致性能和效率的生产场景,适配器调整则在需要频繁切换任务的学术研究环境中表现更优。
从技术演进的角度看,QLoRA是针对LoRA在显存消耗方面的缺陷改进而来,它通过引入4位量化、双重量化及分页优化器等方式,使得微调超大模型所需的显存大幅降低,解决了资源有限的开发者难以触碰大模型的根本问题。
除上述方法外,还有像IA³(通过缩放激活值来微调)、BitFit(仅偏置项微调)等新兴技术,也因其独特的思路和更极致的效率值得探索。然而,LoRA及其变体因其在效果、效率和易用性上的绝佳平衡,目前仍是参数高效微调领域最受推崇和实践验证的方案。
综上所述,大模型微调是连接通用基座模型强大能力与具体业务需求的关键桥梁。通过五种主流方法,我们看到了从全参数微调到参数高效微调的清晰技术演进路径,每种方法都在效率与效果之间提供了不同的平衡点。
在实际应用中,我们建议遵循三维决策框架:首先明确任务目标,其次评估数据规模与质量,最后结合可用计算资源进行技术选型。无论选择哪种方法,都需要警惕过拟合风险,始终将模型的泛化能力放在首位。

作为这一领域的积极参与者,LLaMA-Factory Online为开发者提供了完善的微调解决方案,支持LLaMA、ChatGLM、Qwen、Baichuan等近百种主流模型,集成了LoRA、QLoRA、适配器等多种高效微调算法,并通过可视化界面大幅降低了使用门槛。无论是希望在单张GPU上微调70B模型的研究者,还是需要快速适配业务场景的工程师,都能从中获得有力支持。
未来,大模型微调技术将继续向着更高效、更自动化的方向演进。参数效率将进一步提升,自动化工作流将更加完善,我们期待与开发者共同推动大模型技术在更多场景的落地应用,让每个人都能轻松享受大模型定制带来的技术红利。
作为一名深耕大模型微调领域多年的技术架构师,我深知“纸上得来终觉浅”。在见证了上百个微调项目的成功与失败后,我深刻认识到,拥有一个清晰的学习路径和经过验证的实战资源是多么关键。
为此,我特意整理了全套《大模型微调实战进阶宝典》,这份资料凝聚了我多年的实战经验,其中包含:
这份价值399元的精华资料,现在免费分享给前100位读者。无论你是刚刚接触大模型的初学者,还是希望深化实践经验的资深工程师,这套资料都将为你提供从理论到实践的完整指导。
扫描下方二维码即可保证100%免费领取,愿你能用它,快速撬动大模型在你业务中的巨大价值!



