

产品中心
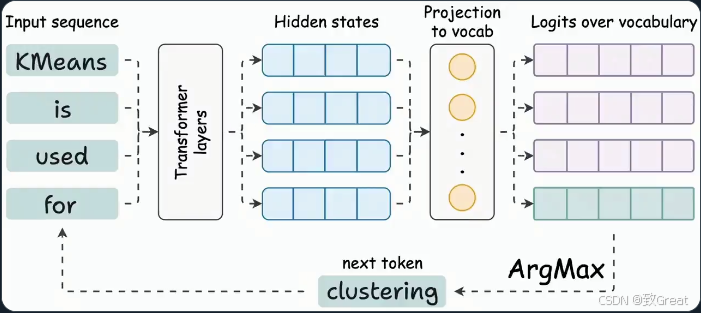
LLM 用于推理的时候就是不断基于前面的所有 token 生成下一个 token。
假设现在已经生成了
个 token,用
表示。在下一轮,LLM 会生成
,注意他们的前
个 token 是一样的:
再下一步也是相似的:
概括来说,每一轮用上一轮的输出当作新的输入让 LLM 预测,一般这个过程会持续到输出达到提前设定的最大长度或者 LLM 自己生成了特殊的结束 token。
? 信息 LLM 的推理过程很好理解,但是这个简单的实现存在一个问题——存在不少的重复计算导致计算效率不是很高 ?
只需要看 LLM 的连续两次前向传播推理计算就很容易理解为什么说存在重复计算了。
比如考虑下面这一步:
LLM 的输入是
,先来看最后一个 token
,它的 query 方向量会和前面的每个 token 以及自己产生的 key 方向量计算:
然后看后一步:
LLM 的输入是
,看最后一个 token
,它的 query 方向量会和前面的每个 token 以及自己产生的 key 方向量计算:
此时考虑
的前一个 token
,它也要参与这次的计算:
可以看到,这个计算完全和上一轮的计算重复,对于在
之前的 token 也是这个问题。我们需要重新计算
的所有 key 方向量和 value 方向量,而这些值的值其实是不会变的 ?。
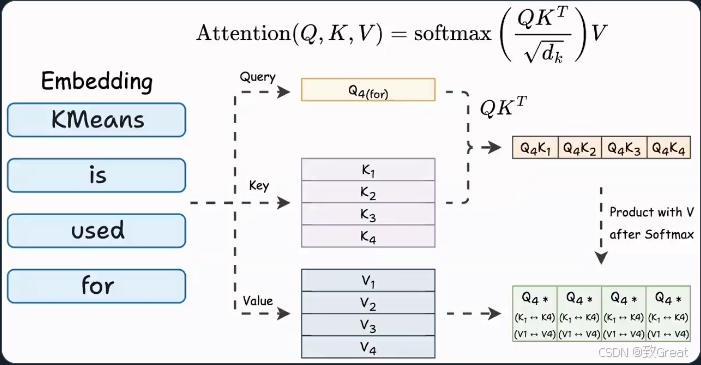
在注意力阶段(Softmax计算):
此外:
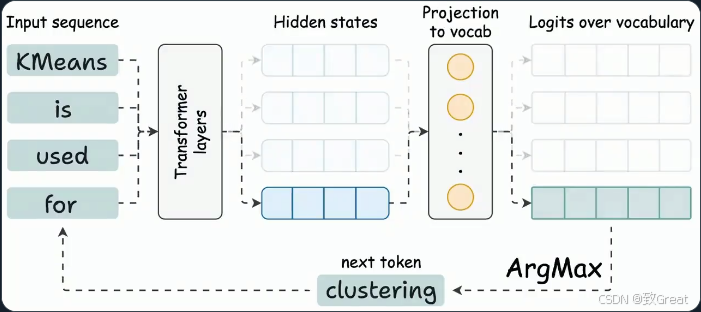
我们可以发现
要生成新 token,网络中的每个注意操作只需要:
当我们生成新 token 时:
这称为 KV 缓存!
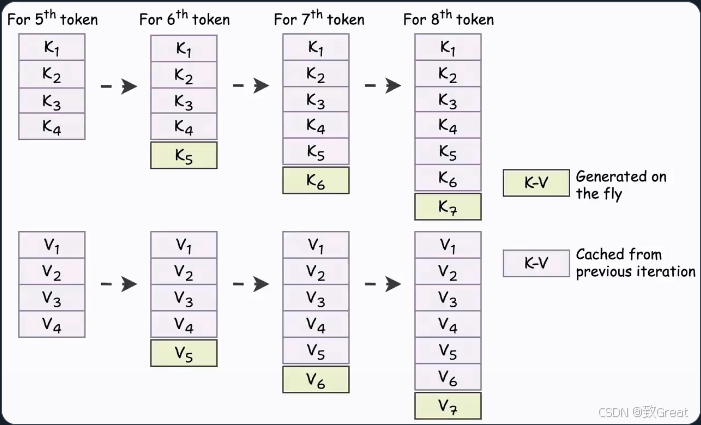
具体工作流程如下:
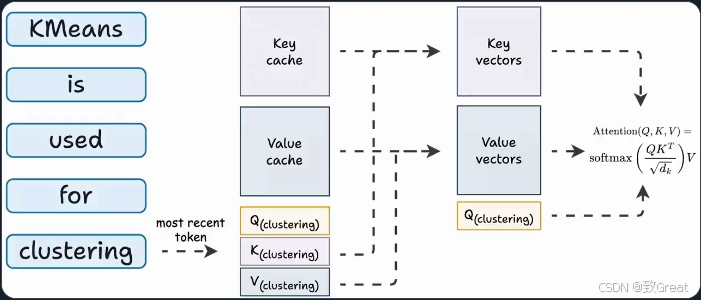
尽管 KV 缓存加速了推理,但它也占用了大量内存。例如:
简单来说,用了KV Cache可以支持更多用户,提高效率 →但是同时也会占用更多内存,以空间换时间。
整体动态图如下:
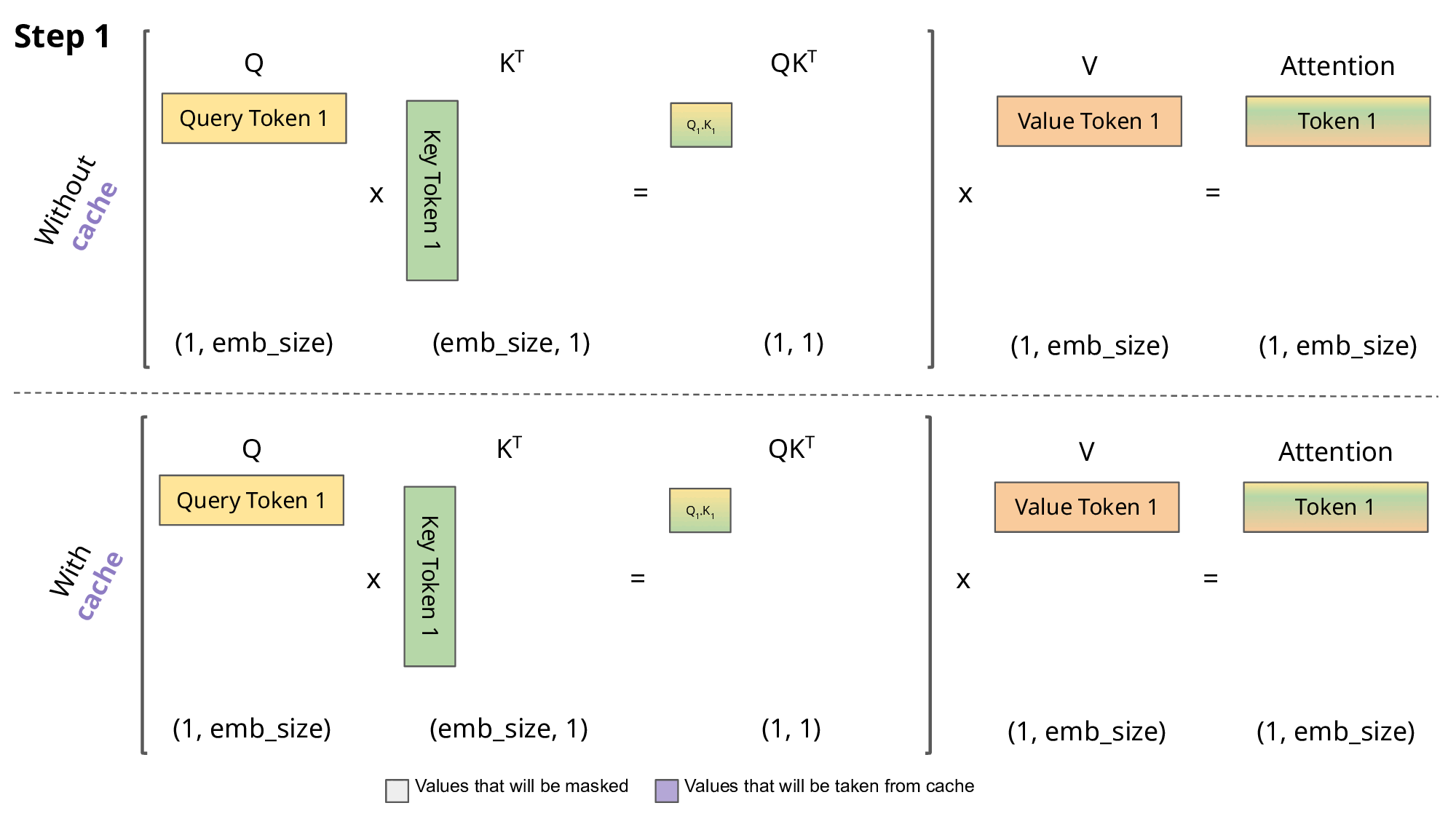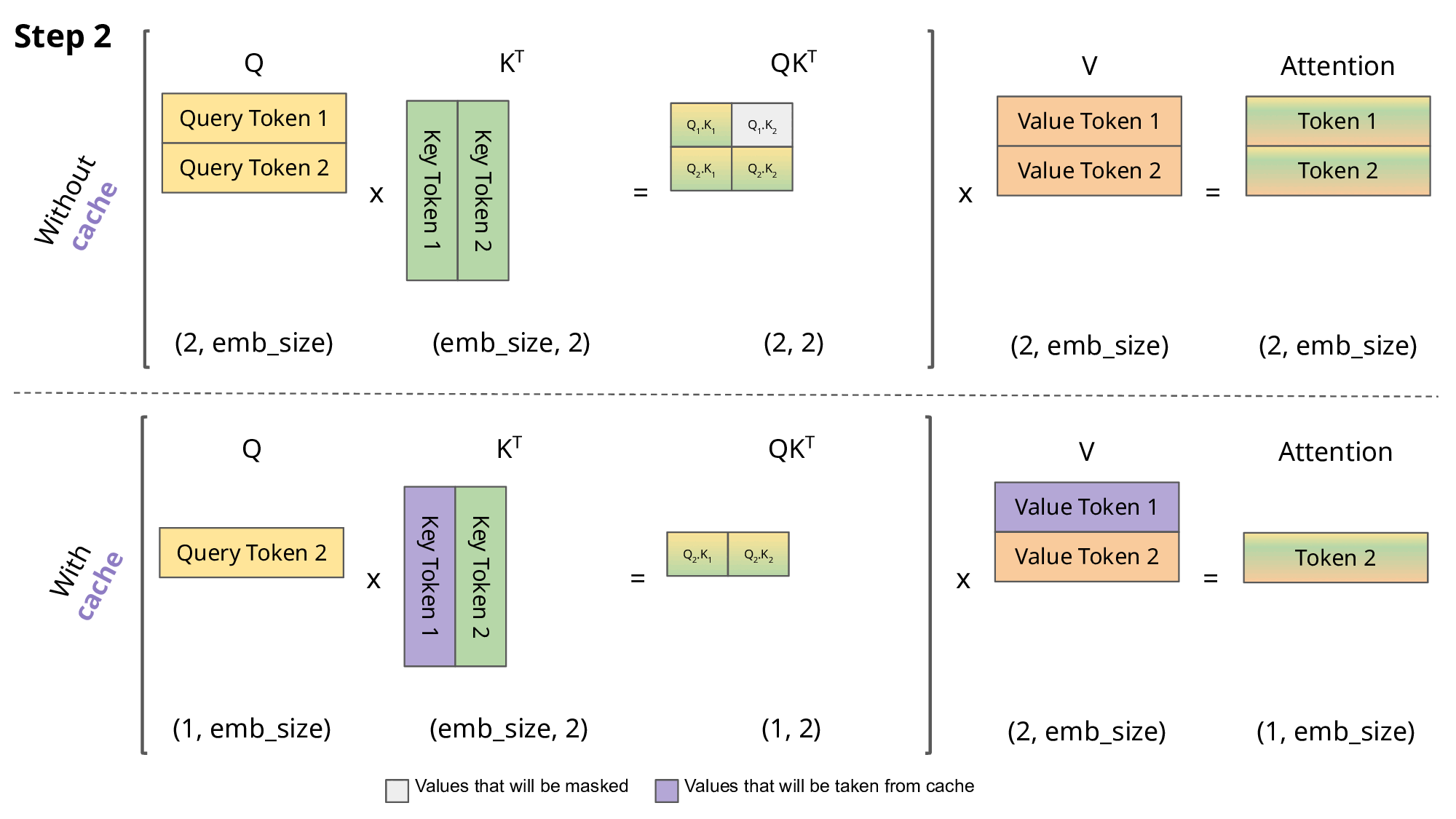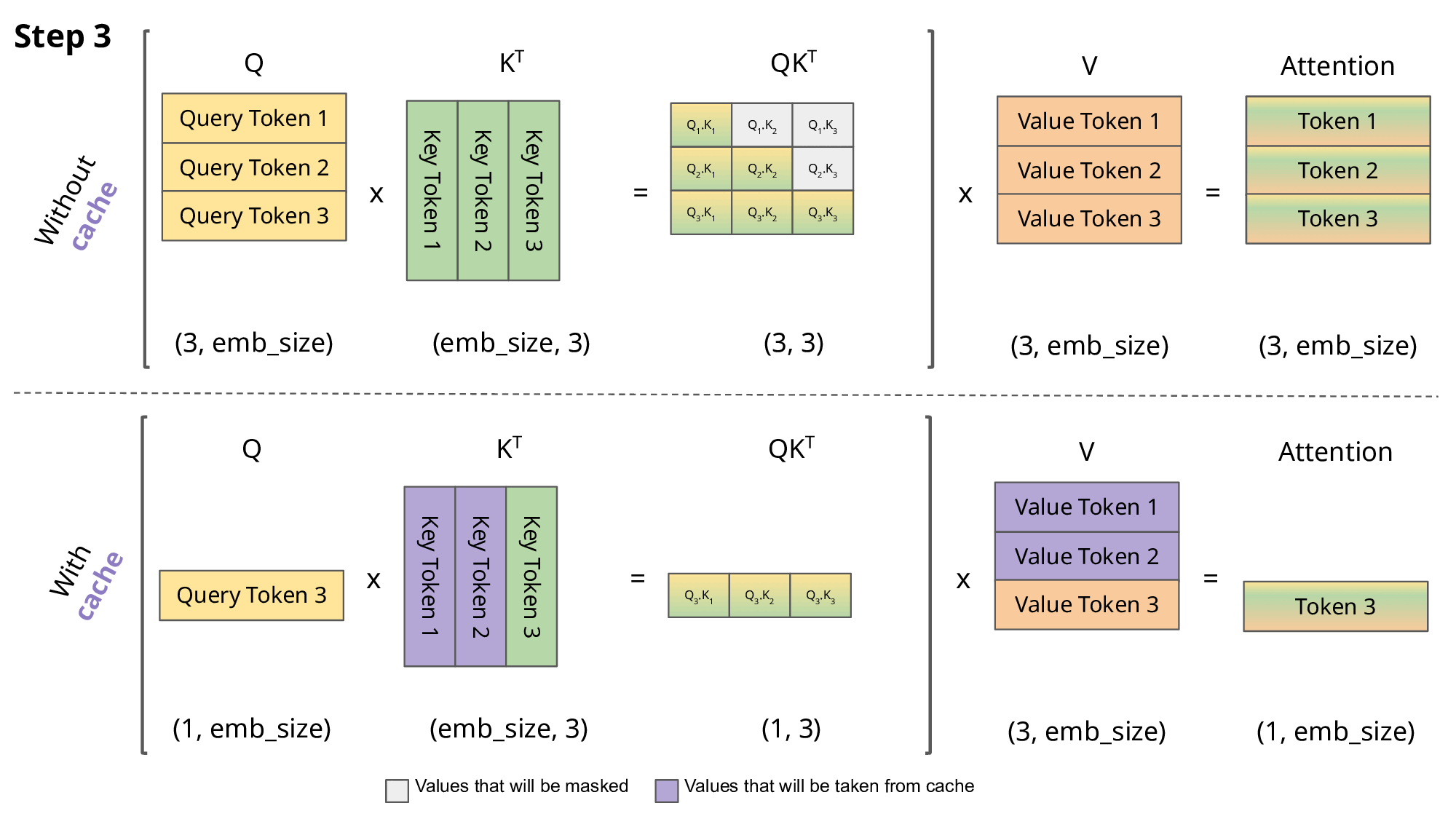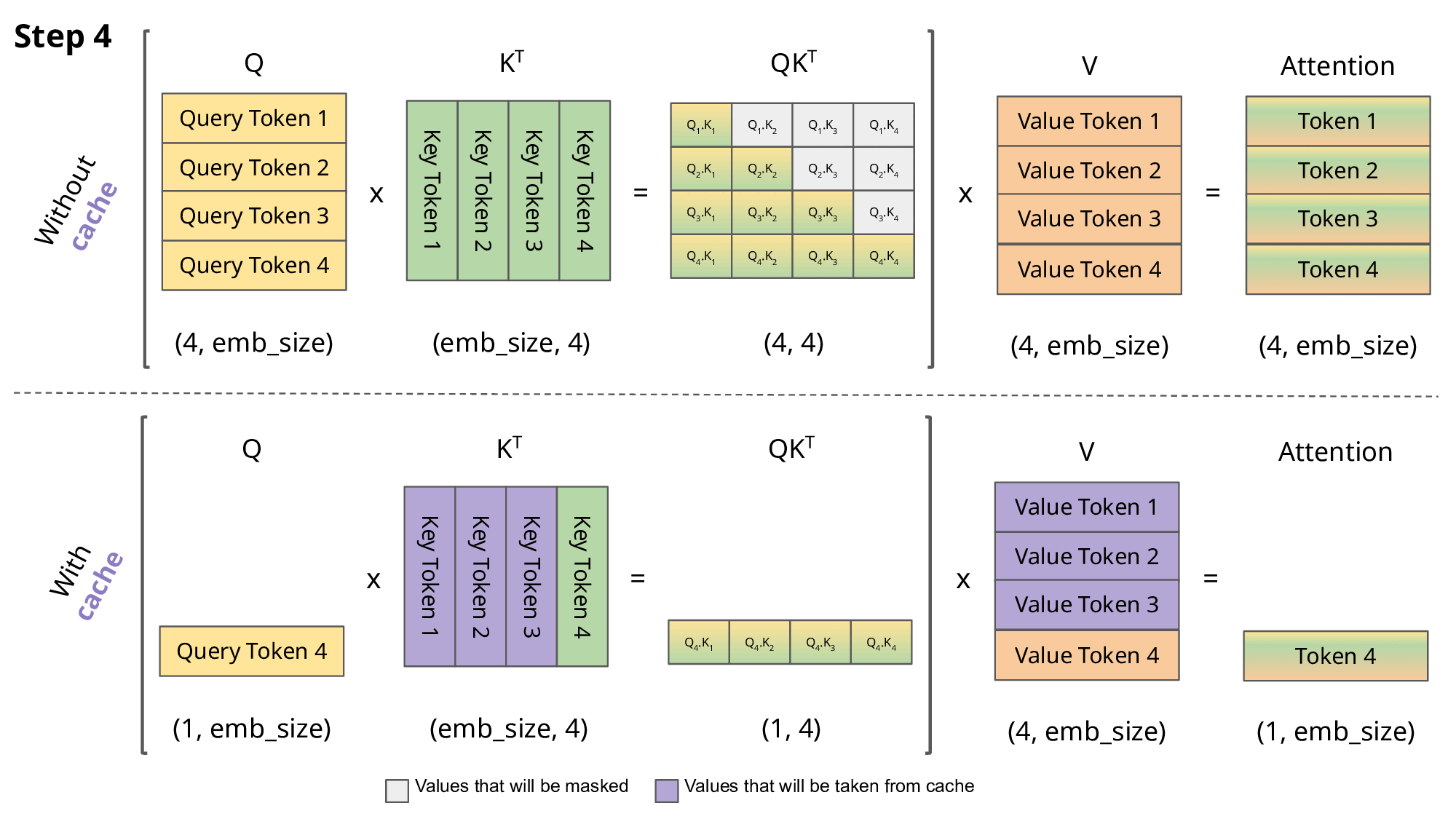
在Transformer架构中,KV Cache是一种关键的性能优化机制。它通过缓存已计算的Key和Value矩阵,避免在自回归生成过程中重复计算,从而显著提升推理效率。这种机制类似于人类思维中的短期记忆系统,使模型能够高效地利用历史信息。
KV Cache 作为 Transformer 架构中的关键性能优化机制,通过巧妙的缓存设计显著提升了模型的推理效率。其工作原理主要体现在三个核心维度:
KV 缓存是加速 LLM 推理的关键技术之一。通过减少重复计算,它显著提升了生成速度,但也带来了内存占用的挑战。理解其工作原理有助于更好地优化和部署大语言模型。


