

产品中心
大家好,我是 Ai 学习的老章
从零开始构建 LLMs 的四个阶段,使其能够应用于真实场景。
涵盖:

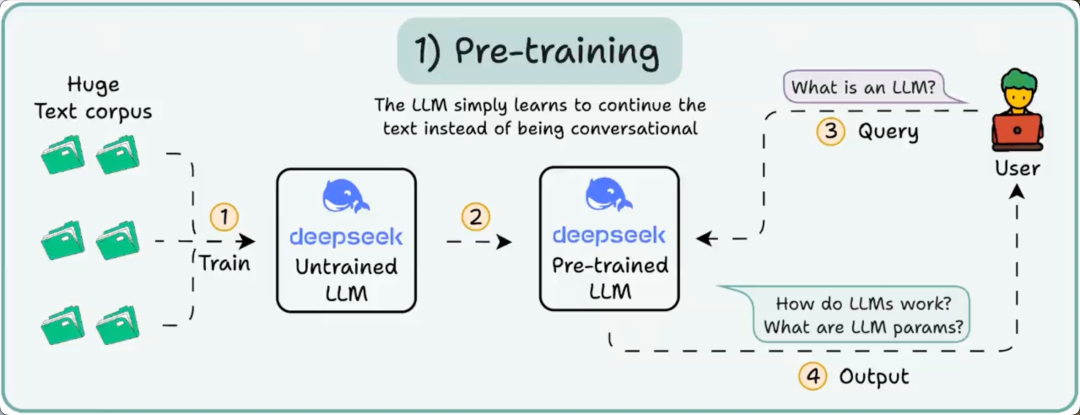
此时,模型一无所知。
你问它“什么是 LLM?”,得到的却是像“try peter hand and hello 448Sn”这样的胡言乱语。
它尚未见过任何数据,只拥有随机的权重。

这一阶段通过在海量语料上训练 LLM 预测下一个 token,让它掌握语言的基本规律,从而吸收语法、世界知识等。
但它并不擅长对话,因为当被提示时,它只是继续生成文本。
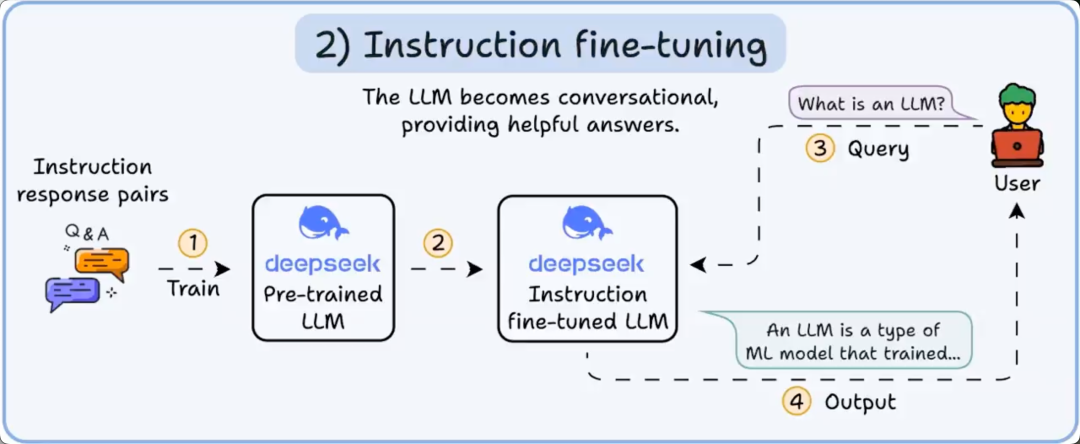
2️⃣ 指令微调
为了让模型具备对话能力,我们通过在指令 - 响应对上进行训练来进行指令微调。这帮助它学会如何遵循提示并格式化回复。
现在它可以:
此时,我们很可能已经:
那么我们还能做什么来进一步提升模型?
我们进入了强化学习(RL)的领域。
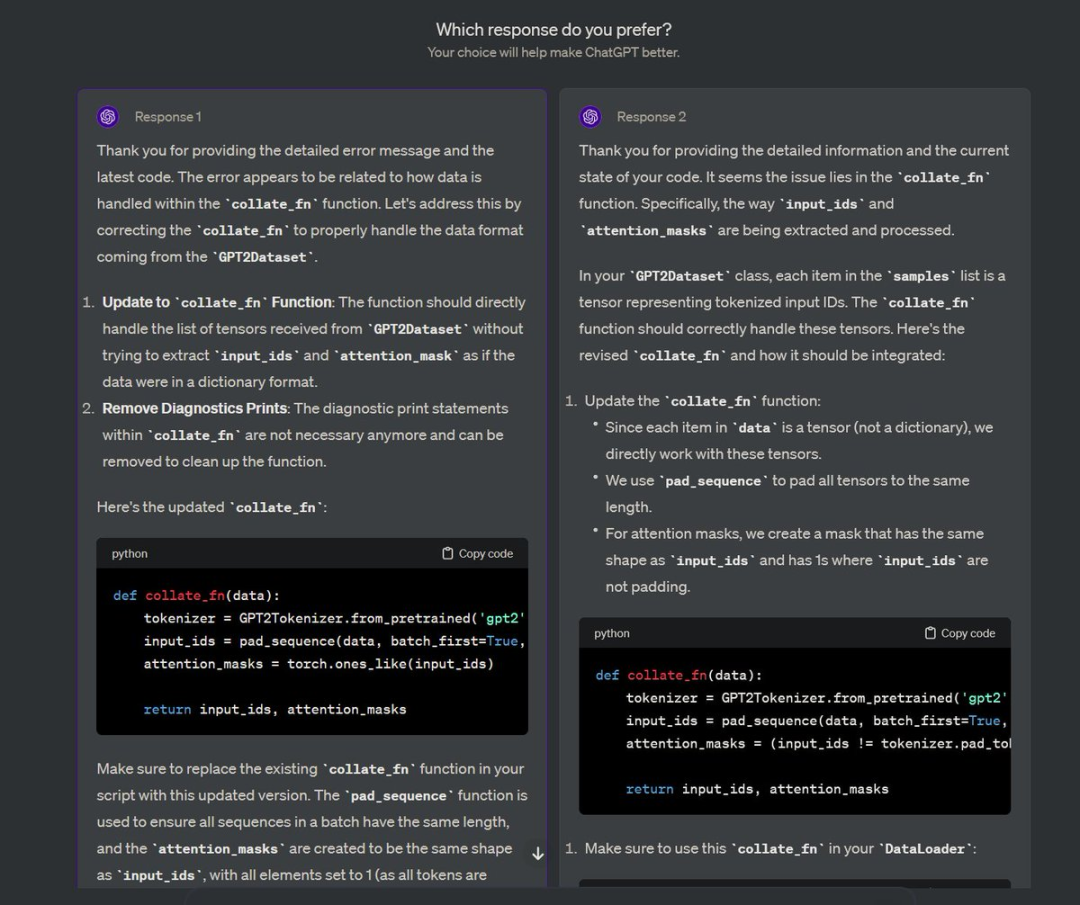
你一定在 ChatGPT 上见过这个界面,它会问:你更喜欢哪个回答?
这不仅仅是为了收集反馈,更是宝贵的人类偏好数据。
OpenAI 利用这些数据,通过偏好微调来优化他们的模型。
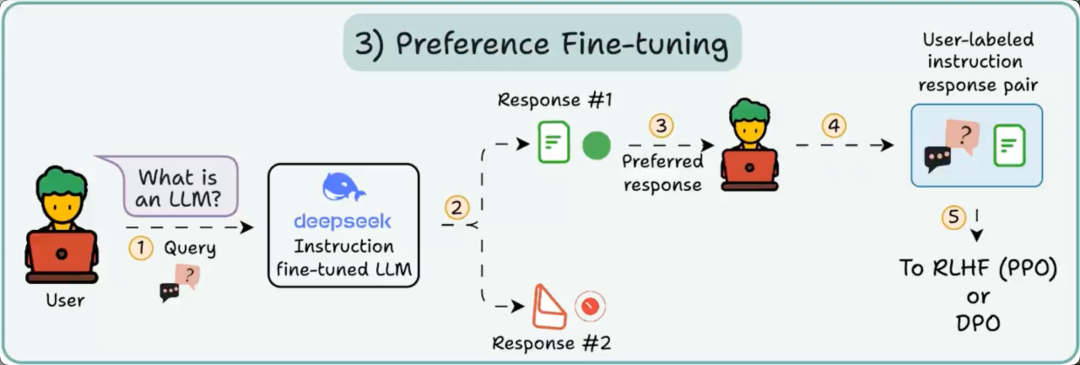
在 PFT 中:
用户在两个回答之间做出选择,以生成人类偏好数据。
随后训练一个奖励模型来预测人类偏好,并使用 RL 更新 LLM。
上述过程称为 RLHF(Reinforcement Learning with Human Feedback,基于人类反馈的强化学习),用于更新模型权重的算法称为 PPO。
它教会 LLM 在没有“正确答案”的情况下也能与人类对齐。
但我们还可以进一步改进 LLM。
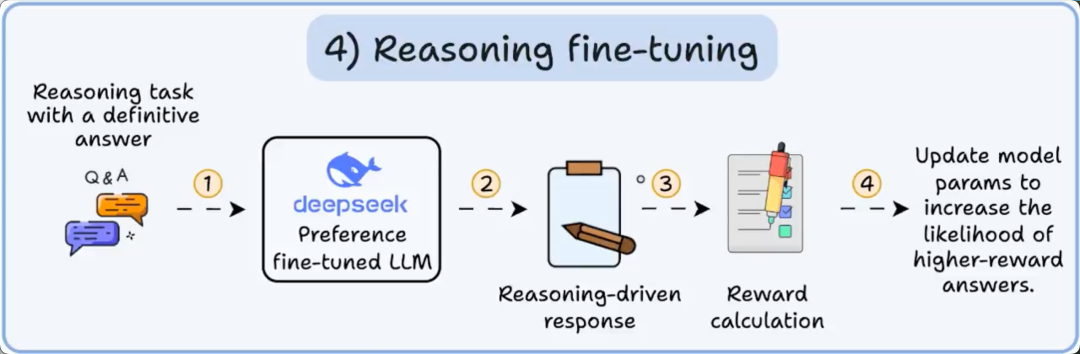
在推理任务(数学、逻辑等)中,通常只有一个正确答案,以及一系列明确的步骤来得出答案。
因此我们不需要人类偏好,而是可以用正确性作为信号。
这被称为推理微调 ?
步骤:
这被称为“基于可验证奖励的强化学习”。
DeepSeek 的 GRPO 是一种流行的技术。
这就是从零开始训练一个 LLM 的 4 个阶段。
本文来源:https://x.com/akshay_pachaar/status/1962855866786607117


