

产品中心
机器学习(MachineLearning),作为计算机科学的子领域,是人工智能领域的重要分支和实现方式。
使机器模仿人类的学习来获取知识。在图像处理中有许多应用,如卷积神经网络(CNN)等在图像处理中具有天然的优势;LSTM之类的深度学习方法可以基于股票价格波动的特征和可量化的市场数据进行股票价格的实时预测,可用于股票市场和高频交易等其他领域中。
监督学习是从标记的训练数据中学习并建立模型,然后基于该模型预测未知的样本。其中,模型的输入是某个样本数据的特征,而函数的输出是与该样本相对应的标签。
常见的监督学习算法:回归分析、统计分析和分类。
分类:包括逻辑回归,决策树,KNN,随机森林,支持向量机,朴素贝叶斯等机器学习算法;
预测:包括线性回归,KNN,GradientBoosting和AdaBoost等机器学习算法。
该类算法的输入样本不需要标记,而是自动地从样本中学习这种特征以实现预测。
常见的无监督学习算法:聚类和关联分析
在人工神经网络中,自组织映射(SOM)和适应性共振理论(ART)是最常见的无监督学习算法。
支持向量机(Support Vector Machine,SVM)是一种用于分类和回归的监督学习算法,特别适用于分类问题。它的核心思想是找到一个最优超平面,将不同类别的数据分开,并最大化类别之间的边界(即“间隔”)。对于线性可分的数据,SVM通过寻找一个超平面来实现分类;对于线性不可分的数据,SVM通过核函数将数据映射到高维空间,使其在高维空间中线性可分。
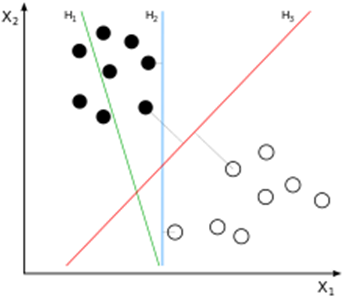

在n维空间中,超平面是一个n-1维的子空间,用于分隔数据。对于新的、未知的样本,SVM可以根据它们与超平面的相对位置来判断其所属类别。
其中w是权重,b是截距,训练数据就是训练得到权重和截距。
直线方程为:y=ax+b
也即:x2=ax1+b
移项后:ax1−x2+b=0
写成向量形式:[a−1][x1x2]+b=0 ,即:wTx+b=0 ,其中,w=[w1,w2]T,x=[x1,x2]T
推广到二维空间:ω=[ω1,ω2,⋯,ωn]Tx=[x1,x2,⋯,xn]T
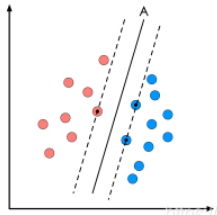
超平面与最近数据点之间的距离。SVM的目标是最大化这个间隔。
离超平面最近的数据点,它们决定了超平面的位置。
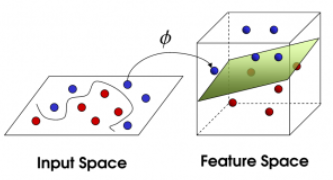
当数据线性可分时,SVM能够直接在原始特征空间中寻找一个最优的超平面,这个超平面能够将不同类别的数据分隔开来,并且保证不同类别之间的间隔最大化;若非线性可分,传统的线性超平面无法有效地区分不同类别的数据。为了解决这个问题,SVM引入了核函数的概念。
用于将数据映射到高维空间的函数,常见的核函数包括线性核、多项式核和径向基函数(RBF)核。
线性SVM、非线性SVM
间隔最大化(Margin Maximization)
核心思想:SVM的目标是找到一个超平面,使得该平面到最近样本点(支持向量)的距离最大。这种间隔最大化策略旨在提高模型的鲁棒性,减少过拟合风险。
数学表达:对于线性可分数据,超平面表示为 到超平面的距离为∣w⋅xi+b∣/∥w∥ 。最大化间隔等价于最小化∥w∥
(即优化问题转化为最小化 12∥w∥2),同时满足约束yi(w⋅xi+b)≥1 (所有样本正确分类)。
适用场景:处理线性可分数据。
优化问题: minw,b 12∥w∥2
核技巧(Kernel Trick):通过非线性映射ϕ(x) 将数据投影到高维空间,使其在高维空间中线性可分。核函数K(xi,xj)=ϕ(xi)⋅ϕ(xj) 避免了显式计算高维映射,直接在原始空间计算内积。
常见核函数:
多项式核:K(xi,xj)=(xi⋅xj+c)d
高斯核(RBF):K(xi,xj)=exp(−γ∥xi−xj∥2)
Sigmoid核:K(xi,xj)=tanh(αxi⋅xj+c)
优化问题的对偶形式:通过拉格朗日乘数法将原问题转化为对偶问题,核函数自然融入:
本科高等数学中学习过拉格朗日乘数法,用于求解在一定约束条件下的极值问题。
令拉格朗日函数L(x,λ)=f(x)+∑lk=1λkhk(x),利用必要条件找到可能的极值点:
在优化理论中,KKT(Karush-Kuhn-Tucker)条件是一组必须满足的条件,以便一个点成为凸优化问题的局部最小值,特别是对于有不等式约束的问题。




# 导入必要的库
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
import joblib # 用于保存/加载模型
# 1. 加载数据集(以乳腺癌数据集为例)
data = datasets.load_breast_cancer()
X, y = data.data, data.target
# 2. 数据预处理
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 标准化特征(SVM对特征尺度敏感)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 3. 创建SVM模型
# 线性SVM
linear_svm = SVC(kernel='linear', C=1.0) # C为惩罚参数
# 非线性SVM(使用高斯核RBF)
rbf_svm = SVC(kernel='rbf', gamma=0.1, C=1.0) # gamma控制核函数的宽度
# 4. 训练模型
linear_svm.fit(X_train, y_train)
rbf_svm.fit(X_train, y_train)
# 5. 模型评估
def evaluate_model(model, X_test, y_test):
y_pred = model.predict(X_test)
print(f"Accuracy: {accuracy_score(y_test, y_pred):.4f}")
print("\nClassification Report:")
print(classification_report(y_test, y_pred))
print("\nConfusion Matrix:")
print(confusion_matrix(y_test, y_pred))
print("===== 线性SVM性能 =====")
evaluate_model(linear_svm, X_test, y_test)
print("\n===== 非线性SVM(RBF核)性能 =====")
evaluate_model(rbf_svm, X_test, y_test)
# 6. 保存模型(可选)
joblib.dump(linear_svm, 'linear_svm_model.pkl')
joblib.dump(rbf_svm, 'rbf_svm_model.pkl')
# 7. 加载模型并进行预测(示例)
loaded_model = joblib.load('linear_svm_model.pkl')
sample_data = scaler.transform([X_test[0]]) # 注意对新数据标准化
prediction = loaded_model.predict(sample_data)
print(f"\n预测结果: {prediction[0]}, 真实标签: {y_test[0]}")超参数调优
from sklearn.model_selection import GridSearchCV
param_grid = {
'C': [0.1, 1, 10],
'gamma': [0.01, 0.1, 1]
}
grid_search = GridSearchCV(SVC(kernel='rbf'), param_grid, cv=5)
grid_search.fit(X_train, y_train)
print("最优参数:", grid_search.best_params_)可视化决策边界(仅适用于2D特征):
# 降维到2个特征(仅用于演示)
X_2d = X[:, :2]
X_train_2d, X_test_2d, y_train_2d, y_test_2d = train_test_split(X_2d, y, test_size=0.2)
model = SVC(kernel='rbf', C=1.0, gamma=0.5)
model.fit(X_train_2d, y_train_2d)
# 绘制决策边界
x_min, x_max = X_train_2d[:, 0].min()-1, X_train_2d[:, 0].max()+1
y_min, y_max = X_train_2d[:, 1].min()-1, X_train_2d[:, 1].max()+1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),
np.arange(y_min, y_max, 0.02))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()]).reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.8)
plt.scatter(X_train_2d[:, 0], X_train_2d[:, 1], c=y_train_2d, edgecolors='k')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('SVM Decision Boundary (RBF Kernel)')
plt.show()

